Describing images with natural language and having an AI instantly understand and act on your request is no longer science fiction. Gemini 2.5 introduces conversational image segmentation, allowing you to interact with images in a way that feels as intuitive as speaking to a colleague. This shift moves us away from rigid commands toward a more natural, flexible exchange between humans and machines.
Breaking Free from Old Limitations
Traditional models could draw boxes or segment shapes, but only within a limited category set. Open-vocabulary approaches extended these boundaries, letting you reference objects with uncommon names. Gemini 2.5 goes even further, understanding precise, descriptive phrases like “the car that is farthest away.” This advancement provides a more intuitive and detailed way to interact with visuals, making complex queries simple.
Credit: Google
Five Query Types That Make Gemini 2.5 Stand Out
- Object relationships: Find objects by their connections, such as “the person holding the umbrella” or “the third book from the left.”
- Conditional logic: Use conditions or exclusions, for example, “the people who are not sitting” or “food that is vegetarian.”
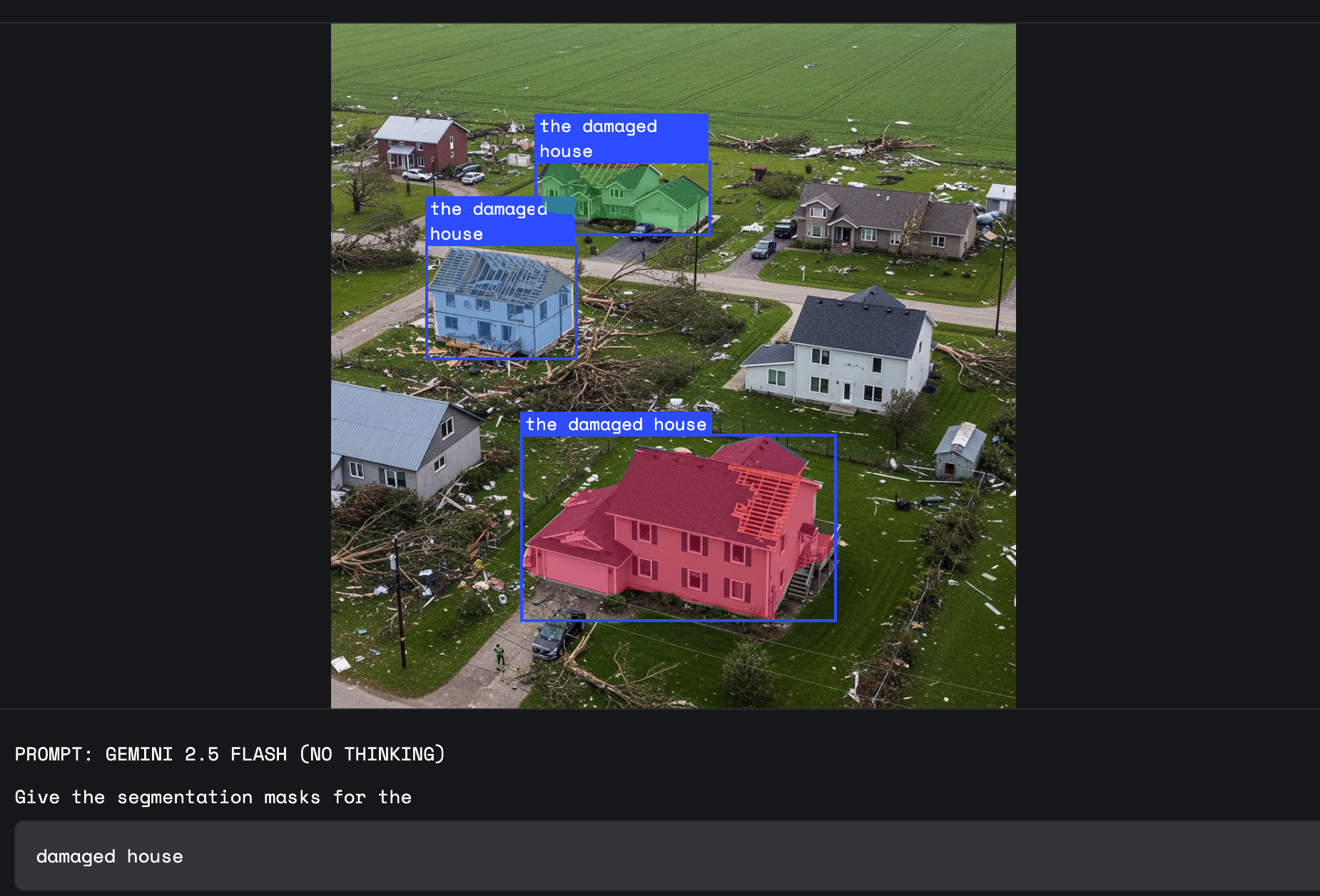
- Abstract concepts: Pinpoint ideas without clear visual forms, including “damage,” “a mess,” or “opportunity.”
- In-image text: Select objects based on their written labels, thanks to advanced OCR—think “the pistachio baklava” in a bakery display.
- Multi-lingual labels: Handle queries and segmentation overlays in diverse languages, opening the door to global applications.
Developer Benefits: Flexibility and Simplicity
Gemini 2.5 liberates developers from static, pre-defined classes. It empowers you to handle unique, domain-specific queries through a single API. There’s no need to train separate models for every segmentation scenario. Comprehensive documentation and interactive demos, both in the browser and with Python, make it easy to start experimenting right away.
Unlocking Real-World Value
- Interactive media editing: Designers can select sophisticated regions, like “the shadow cast by the building,” using conversational prompts instead of tedious manual tools.
- Safety and compliance monitoring: Automated systems can spot issues such as “employees not wearing hard hats,” enhancing workplace safety.
- Insurance claim processing: Adjusters can quickly segment “homes with weather damage,” streamlining assessments with AI’s understanding of subtle visual cues.
How to Get Started
Google offers convenient tools to try conversational segmentation, including a Spatial Understanding demo and a Colab notebook. For best results, use the gemini-2.5-flash model, disable thinking set (thinkingBudget=0), and follow recommended prompt formats—requesting JSON outputs with precise, descriptive labeling.
A New Standard for Visual Intelligence
Gemini 2.5 represents a leap in making image segmentation feel natural and accessible. By connecting language and vision at a granular level, it empowers professionals across design, safety, insurance, and more to innovate with ease. As conversational image segmentation becomes mainstream, expect new creative and practical possibilities to emerge.
Source: Google Developers Blog


Conversational Image Segmentation: How Gemini 2.5 Is Changing Visual Interaction