Understanding how small molecules interact with proteins is a cornerstone of modern drug discovery. These compound–protein interactions (CPIs) determine whether a candidate molecule can modulate a biological pathway, inhibit a pathogen, or trigger therapeutic effects. Traditional experimental methods to identify CPIs are accurate but costly and time‑consuming, creating a bottleneck in early‑stage drug development.
To address this challenge, researchers have introduced GraphBAN, an inductive graph‑based framework that integrates the structural strengths of graph neural networks with the contextual reasoning of large language models.
By representing molecules and proteins as graphs and learning their interaction patterns, GraphBAN achieves state‑of‑the‑art predictive performance while remaining scalable to new, unseen compounds and targets.
This dual emphasis on accuracy and generalizability positions GraphBAN as a powerful tool for accelerating drug discovery pipelines, reducing reliance on exhaustive laboratory screening, and opening new avenues for computational biology research
Key Takeaways
- GraphBAN combines a GAE teacher, a feature-fusion student, BAN attention, and CDAN domain adaptation to enable inductive and cross-domain CPI prediction.
- Across BioSNAP, BindingDB, KIBA, C. elegans, and PDBbind 2016, GraphBAN improves AUROC over DrugBAN by 9.32%, 5.46%, 3.32%, 2.76%, and 0.72%, respectively.
- Feature extraction pairs ChemBERTa for SMILES and ESM for proteins with GCN and CNN encoders, then fuses them into compact representations ((Chithrananda et al., 2020); (Rives et al., 2021)).
- CDAN helps close the source-target distribution gap to improve cross-domain generalization (Long et al., 2018).
- The case study screens ZINC-250K for Pin1, filters with Lipinski and PAINS, uses ADMET-AI for risk, and visualizes attention on predicted binding sites.
Overview
At the heart of drug discovery lies a simple but powerful question: how do small molecules interact with the proteins that drive life’s processes?
These compound–protein interactions (CPIs) are the foundation of how medicines work, yet predicting them is one of the hardest problems in biomedical science. Proteins are intricate, dynamic structures; compounds come in endless shapes and chemistries; and the space of possible pairings is astronomically large. Traditional approaches, whether experimental or computational, struggle to keep pace with this complexity.
This research introduces GraphBAN, a new framework that marries the structural precision of graph-based models with the contextual reasoning power of large language models. By combining these two perspectives, GraphBAN doesn’t just improve the accuracy of CPI predictions, it also helps explain why certain compounds are likely to bind, offering insights that are both predictive and interpretable.
The result is more than just a performance boost on benchmarks. It’s a step toward making CPI prediction a practical tool for real-world drug discovery, where speed, reliability, and understanding all matter. By bridging cutting-edge AI with the biological realities of proteins and compounds, this work moves us closer to a future where discovering new therapies is faster, smarter, and more transparent
How it Works
GraphBAN models CPIs on a bi-partite network where compounds and proteins are nodes and active links are edges. The teacher module is a graph autoencoder (GAE) that learns structural embeddings, which transfer to a student via knowledge distillation loss terms (cosine, MSE).
The student uses feature extractors for both modalities: a GCN over molecular graphs and a ChemBERTa encoder for SMILES on the compound side; a CNN over amino acid sequences and an ESM encoder for proteins ((Chithrananda et al., 2020); (Rives et al., 2021)). A linear projection aligns dimensions and a fusion block combines features into 128-d vectors per modality.
The BAN layer forms a bilinear interaction map between compound and protein representations and applies pooling to obtain a joint vector, which feeds a classifier. This attends to substructures and residues that contribute most to predicted activity, and the paper visualizes these weights in the case study.
To handle covariate shift across datasets or cluster splits, CDAN conditions the domain discriminator on features and logits, encouraging indistinguishable joint representations across source and target domains ((Long et al., 2018)).
Methods, Materials, and Techniques
Datasets and splitting. The study uses five public CPI datasets: BindingDB, BioSNAP, KIBA, PDBbind 2016, and C. elegans, with fully inductive, cross-domain evaluation. Clusters are built using ECFP features for compounds and k-mer profiles for proteins; 60% of clusters form the labeled source domain, 40% form the target domain, of which 80% is used unlabeled during training and the remaining 20% is the labeled target test set.
Feature extraction and fusion. Compounds are encoded via a structural GCN and ChemBERTa (self-supervised on SMILES). Proteins are encoded via a 1D CNN and ESM (a large protein language model). Linear projections align embeddings and a fusion block produces compact 128-dimensional representations per modality.
Teacher-student and graph learning. A graph autoencoder (GAE) teacher learns network structure; a student receives distilled guidance using cosine and MSE losses, learns from node attributes, and drives predictions with a bilinear attention network (BAN). CDAN conditions the domain discriminator on features and logits to align source and target domains.
Training and evaluation. Implementation uses Python 3.8, PyTorch 1.7.1, and DGL 0.7.1. The teacher runs up to 250 epochs (Adam, lr=1e-3) and the student up to 50 epochs (Adam, lr=1e-4), batch size 32. Metrics are AUROC, AUPRC, and F1, averaged over five seeds; paired t-tests assess significance.
Case study pipeline. For Pin1, ~250,000 ZINC-250K compounds are screened. Candidates are filtered by Lipinski’s rule-of-five and PAINS, triaged with ADMET-AI, and docked with AutoDock Vina. Attention maps from BAN coincide with residues near predicted pockets; visualizations use ChimeraX and ChemDraw ((Swanson et al., 2024); (Baell & Holloway, 2010); (Lipinski et al., 2001); (Trott & Olson, 2010)).
Why It Matters
Drug discovery increasingly depends on models that generalize to new chemistry and targets with limited or no labeled interactions. Inductive link prediction and cross-domain robustness are practical requirements for screening large libraries or under-studied proteins.
GraphBAN addresses both by uniting graph structure learning and attribute-based learning, then adding domain adaptation at the representation level. This is a different approach from transductive-only graph models or purely tabular models that ignore network topology.
Interpretability also matters in medicinal chemistry. BAN attention highlights substructures and protein residues that drive predictions, providing qualitative signals for medicinal chemists. The teacher-student split preserves a role for topology while keeping the student deployable on unseen nodes that lack known edges.
Discussion of Results
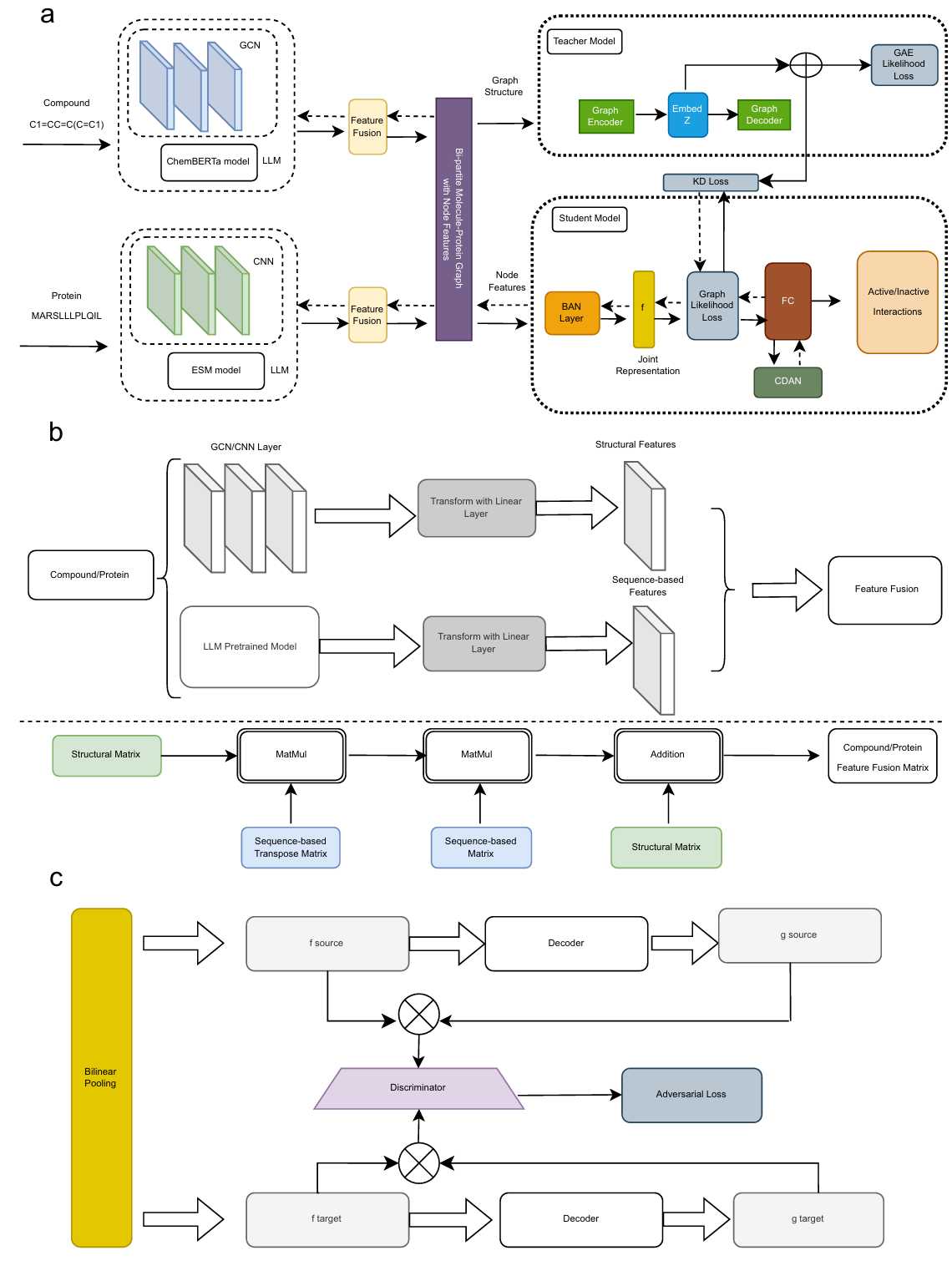
Fig. 1 | The architecture of GraphBAN. a The input compound molecules are encoded by graph convolutional network (GCN) layers and ChemBERTa separately, while protein sequences are encoded by 1D layer convolutional neural network (CNN) and evolutionary scale modeling (ESM). b Fusion of features with same architecture for both compounds and proteins. Fusion module shows how we bring the extracted features in the same dimensionality with the Linear Transform Layers. The feature fusion includes two "MatMul" layers that operate element-wise multiplication and one "Addition" layer that do the element-wise addition. c The CDAN module. It receives input from the bilinear attention network (BAN) layer and generates concatenation of the compound and protein features and SoftMax logits "g" for source and target domains into a joint conditional representation using the discriminator module. The discriminator has two fully connected layers with an adversarial loss to minimize the classification error between the source and target domains.
Evaluation setup and metrics (Figure 1, Methods). The authors evaluate GraphBAN on five public CPI datasets with fully inductive and cross-domain splits built from clustering on ECFP features for compounds and k-mer profiles for proteins. Metrics are AUROC, AUPRC, and F1, averaged over five seeds with paired t-tests reported for significance. Baselines span classical ML and recent deep models, including RF, DeepConv-DTI, GraphDTA, MolTrans, GraphsformerCPI, DSANIB, CPInformer, PocketDTA, and the closely related DrugBAN.
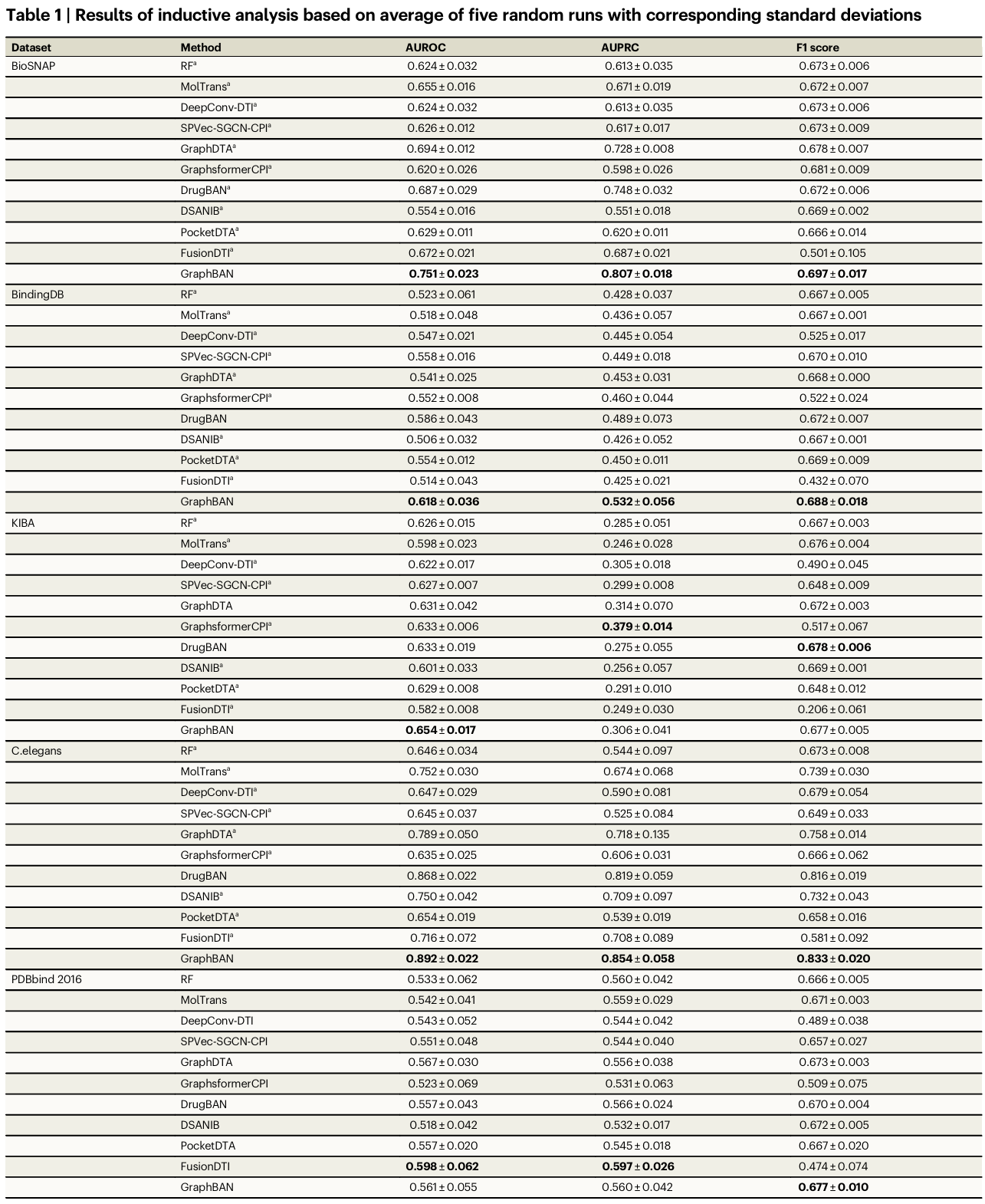
Overall performance (Table 1). GraphBAN achieves the top AUROC and AUPRC across the majority of dataset-task pairs, with statistically significant gains in many comparisons. Relative to DrugBAN, GraphBAN reports AUROC improvements of 9.32% on BioSNAP, 5.46% on BindingDB, 3.32% on KIBA, 2.76% on C. elegans, and 0.72% on PDBbind 2016. The authors note that dataset characteristics influence absolute AUPRC, such as label imbalance in KIBA.
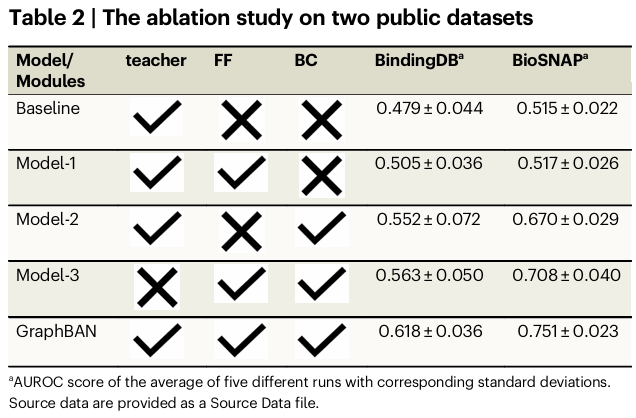
Ablations (Table 2). The feature fusion block and the BAN+CDAN stack each improve the baseline, and removing the teacher diminishes performance. On BindingDB and BioSNAP, the full model delivers the best AUROC, supporting the claim that combining network structure learning with attention-based feature fusion and domain adaptation is synergistic.
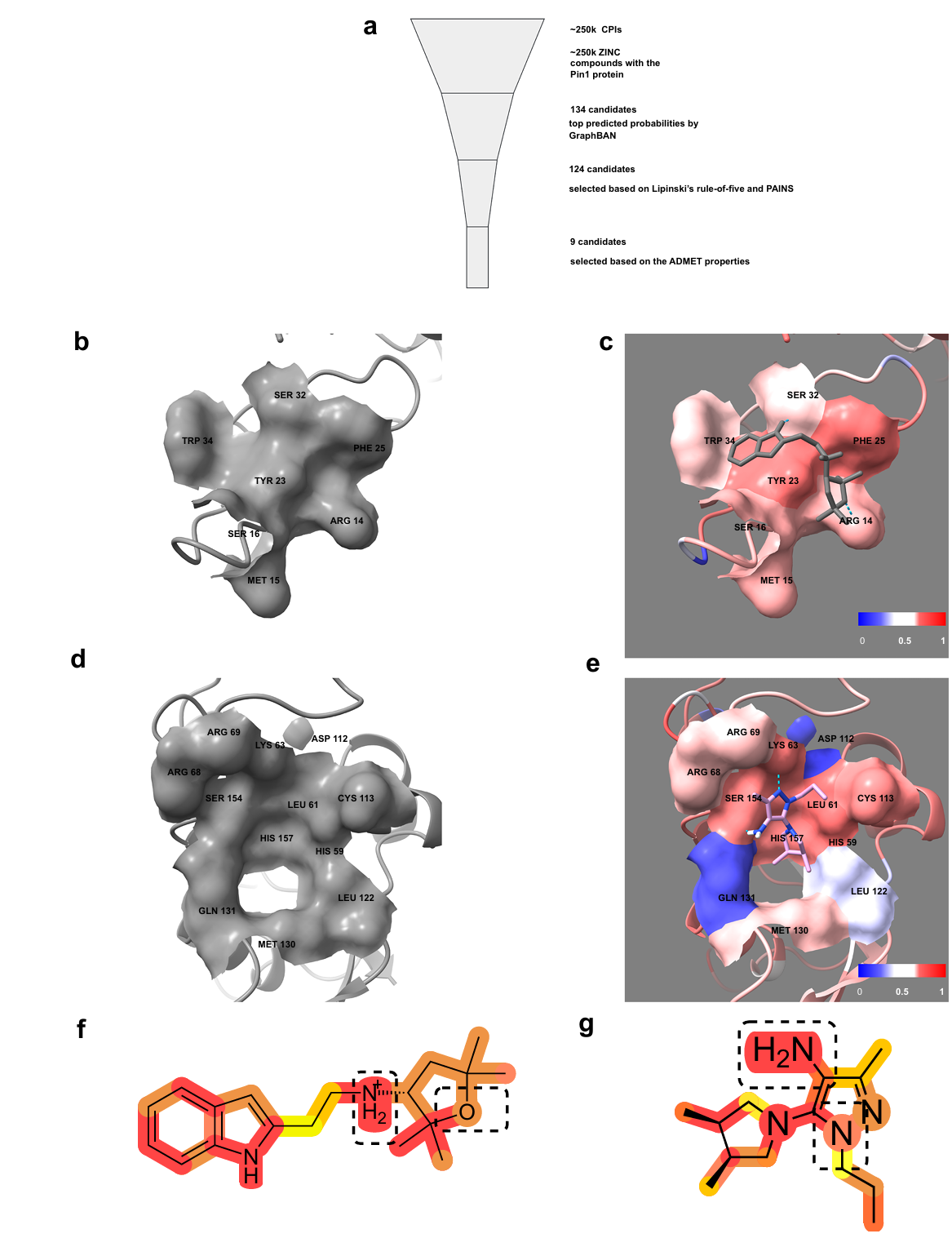
Fig. 2 | Filtering and visualizing attention weights of Pin1 binding sites and interacting compounds.
Case study on Pin1 (Figure 2). Screening ZINC-250K yields 134 common candidates across models trained on different source datasets. The pipeline applies Lipinski and PAINS filters and ADMET-AI risk flags, reducing to nine leads. Docking with AutoDock Vina identifies plausible binding poses, and BAN-derived attention weights coincide with residues near the binding pockets. Tanimoto similarities to a known selective Pin1 inhibitor, BJP-06-005-3, are moderate for two highlighted molecules, suggesting similar interaction motifs without being trivial analogs.
Summary of results.
Across five benchmarks (BioSNAP, BindingDB, KIBA, C. elegans, PDBbind 2016), GraphBAN achieved the highest AUROC and AUPRC in most settings, with paired t-tests indicating significance on many comparisons; relative to DrugBAN, AUROC improved by 9.32% (BioSNAP), 5.46% (BindingDB), 3.32% (KIBA), 2.76% (C. elegans), and 0.72% (PDBbind 2016).
AUPRC varied with class imbalance (notably in KIBA). Ablations confirmed that teacher distillation, feature fusion, and BAN+CDAN each contributed additive gains. In a Pin1 screen of ZINC-250K, 134 consensus hits were reduced to nine candidates after Lipinski/PAINS and ADMET filters; docking and attention maps showed plausible binding-site correspondence.
Reproducibility and assets.
The authors release code, data splits, trained models, and case study inputs/outputs. Data sources include BindingDB, BioSNAP, KIBA, PDBbind 2016, and C. elegans; repository directories expose splits under (GraphBAN Data) and case study artifacts under (GraphBAN case_study), with archived releases on Zenodo.
Conclusion
GraphBAN demonstrates a practical route to inductive, cross-domain CPI prediction by combining graph structure learning with strong attribute encoders and domain alignment. The method advances over ten baselines on five datasets and supports mechanistic interpretation via attention.
Limitations include sensitivity to dataset bias, class imbalance effects on AUPRC, and added complexity from multi-component training. Future work that adds incremental learning and broader multi-modal inputs could make the approach more adaptable in production discovery settings ((Hadipour et al., 2025)).



GraphBAN Marries Graphs and LLMs to Predict New Compound-Protein Interactions
GraphBAN: An inductive graph-based approach for enhanced prediction of compound-protein interactions