Researchers face a growing challenge: staying current with the ever-expanding body of scientific literature. Foundation models offer promise in helping synthesize and analyze this vast information, but assessing their performance on nuanced, discipline-specific scientific tasks is tricky. Traditional benchmarks quickly become outdated and often lack the rigor scientists need for reliable model evaluation.
SciArena: A Collaborative Solution
SciArena steps in as an open, collaborative platform designed to evaluate foundation models in scientific literature tasks. Inspired by community-driven platforms like Chatbot Arena, SciArena invites the scientific community to participate directly in head-to-head assessments of large language models (LLMs) using real-world scientific scenarios. This approach harnesses collective expertise and ensures evaluations remain relevant and robust.
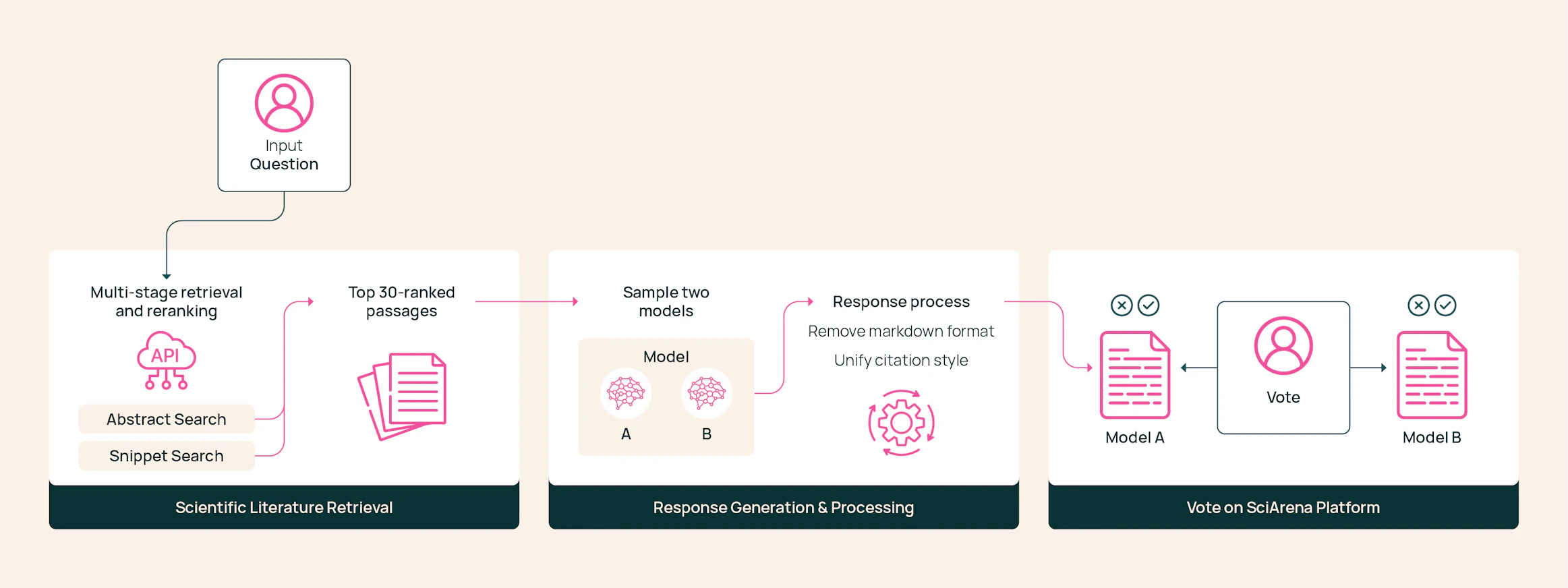
Image Credit: Yale
How SciArena Works
- Interactive Platform: Users submit research questions, review model-generated responses grounded in actual scientific papers, and vote for the best answer.
- Dynamic Leaderboard: Models are ranked using an Elo system, reflecting real-time performance across multiple scientific domains based on community feedback.
- SciArena-Eval: This meta-benchmark leverages human voting data to measure the reliability of automated model evaluators, ensuring that evaluation tools themselves are held to high standards.
The Evaluation Process
SciArena’s pipeline is meticulously designed for scientific rigor. When a user poses a question, the platform retrieves relevant scientific passages using a multi-stage system adapted from Ai2’s Scholar QA.
Two randomly selected models generate responses based on these passages. Their outputs, rich in citations and grounded in literature, are anonymized and standardized before being presented to human evaluators who judge solely on content quality and relevance.
Performance Insights and Benchmarks
By June 2025, 23 advanced foundation models had been evaluated on SciArena. The o3 model leads in technical and engineering responses, while Claude-4-Opus and DeepSeek-R1-0528 shine in healthcare and natural sciences.
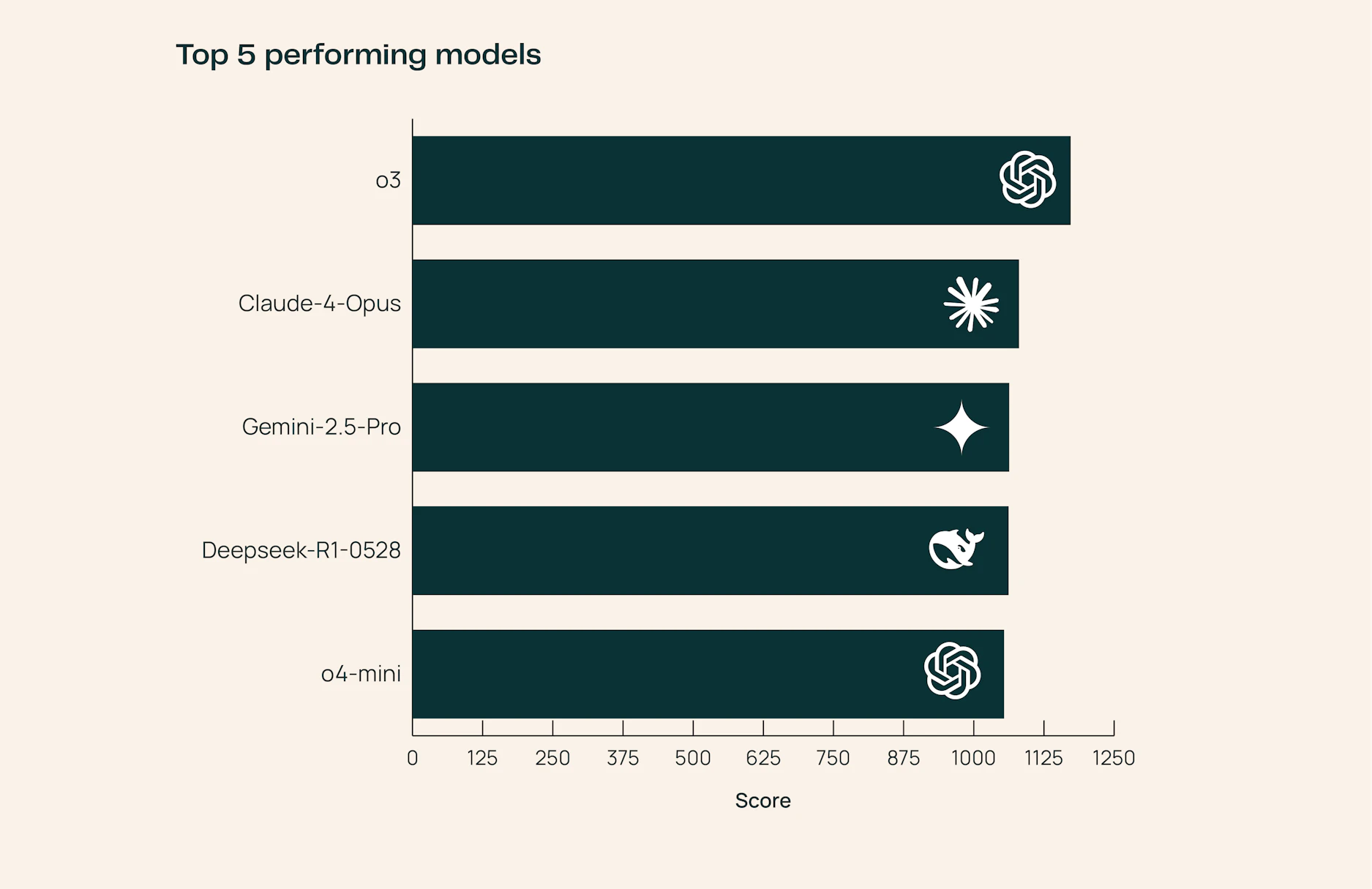
Image Credit: Yale
These variations underscore that model strengths are often discipline-dependent. Notably, even the best automated evaluators lag behind human judgment, top models only achieve 65.1% accuracy in matching human preferences, highlighting the complexity of scientific evaluation versus general tasks
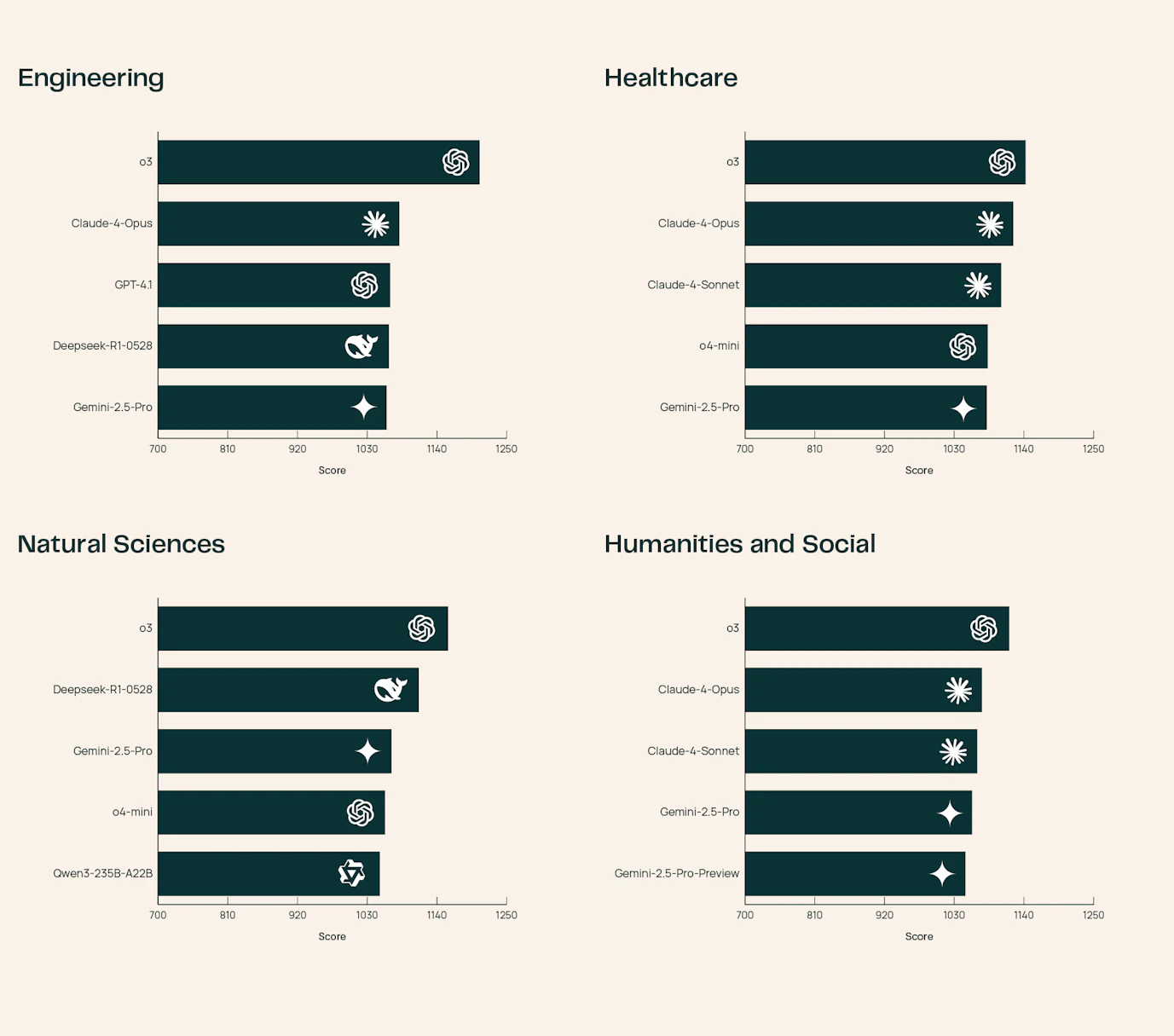
Image Credit: Yale
Ensuring Quality and Trust
- Expert Annotators: SciArena’s evaluator pool includes 102 vetted researchers with peer-reviewed publications and AI tool expertise.
- Thorough Training: All annotators undergo comprehensive training for consistent, reliable assessments.
- Blind Evaluation: Model identities are hidden to prevent brand bias.
- Reliability Metrics: High inter-annotator agreement (weighted Cohen’s κ = 0.76) and self-consistency (κ = 0.91) confirm strong evaluation integrity.
With more than 13,000 human votes in just four months, SciArena’s commitment to data quality ensures its model rankings and benchmarks are both trustworthy and actionable.
Continuous Improvement and Community Involvement
SciArena is designed for continuous growth. Model developers are encouraged to participate as the platform expands to new models and disciplines. Upcoming features include testing additional retrieval and prompting strategies within the retrieval-augmented generation (RAG) pipeline to further enhance evaluation accuracy. SciArena’s open ethos, sharing datasets, code, and metrics, empowers researchers to build on its foundation.
How to Participate
- Explore and vote on model outputs at the SciArena platform.
- Monitor real-time model rankings on the leaderboard.
- Leverage open datasets and evaluation tools for your own research.
- Read the full technical paper for deeper insights.
Conclusion
SciArena represents a leap forward in transparent, community-driven evaluation of AI models for scientific research. By leveraging expert judgment, rigorous methods, and open data, it tackles the challenge of reliable AI assessment and sets a new standard for the future of scientific evaluation.
Source: Allen Institute for Artificial Intelligence (AI2) - SciArena Blog
Github: https://github.com/yale-nlp/SciArena


SciArena: Transforming How We Evaluate AI Models in Scientific Research