Semantic routing has historically hit a wall when scaling to new classification tasks. Each new intent or filter often required an additional heavy machine learning model, driving up computational costs and operational complexity.
With the latest overhaul of the vLLM Semantic Router, these barriers are being dismantled through a blend of modular design, Low-Rank Adaptation (LoRA), and hardware-conscious optimizations. The result is a system that routes requests faster, supports more languages, and runs leaner than ever.
From Monolithic to Modular
Earlier systems were tightly coupled to ModernBERT, which, while effective for English, struggled with multilingual tasks and longer context windows. The integration of models like mmBERT and Qwen3-Embedding, each excelling at language coverage or context length, became cumbersome. By decoupling the routing logic from specific models, the new modular approach lets developers slot in the best-fit embedding model for any use case. This not only accommodates over 1,800 languages but also paves the way for long-context processing and future model integrations.
Layered Extensibility with Rust
At the heart of the new architecture is a layered classification system, built with Rust's candle-binding crate. The DualPathUnifiedClassifier handles routing between standard and LoRA-adapted models, separating model-agnostic logic from implementation details. This separation means new embedding models can be added quickly, ensuring the router remains agile as the machine learning landscape evolves.
Choosing the Right Model for the Task
- Qwen3-Embedding: Handles documents up to 32,768 tokens and supports more than 100 languages, ideal for complex, multilingual tasks.
- EmbeddingGemma-300M: Prioritizes efficiency with a compact model size and context window, using advanced techniques like Matryoshka representation learning and Multi-Query Attention for speed and flexibility.
By offering these choices, the router can deliver more accurate and contextually relevant results, regardless of document length or language.
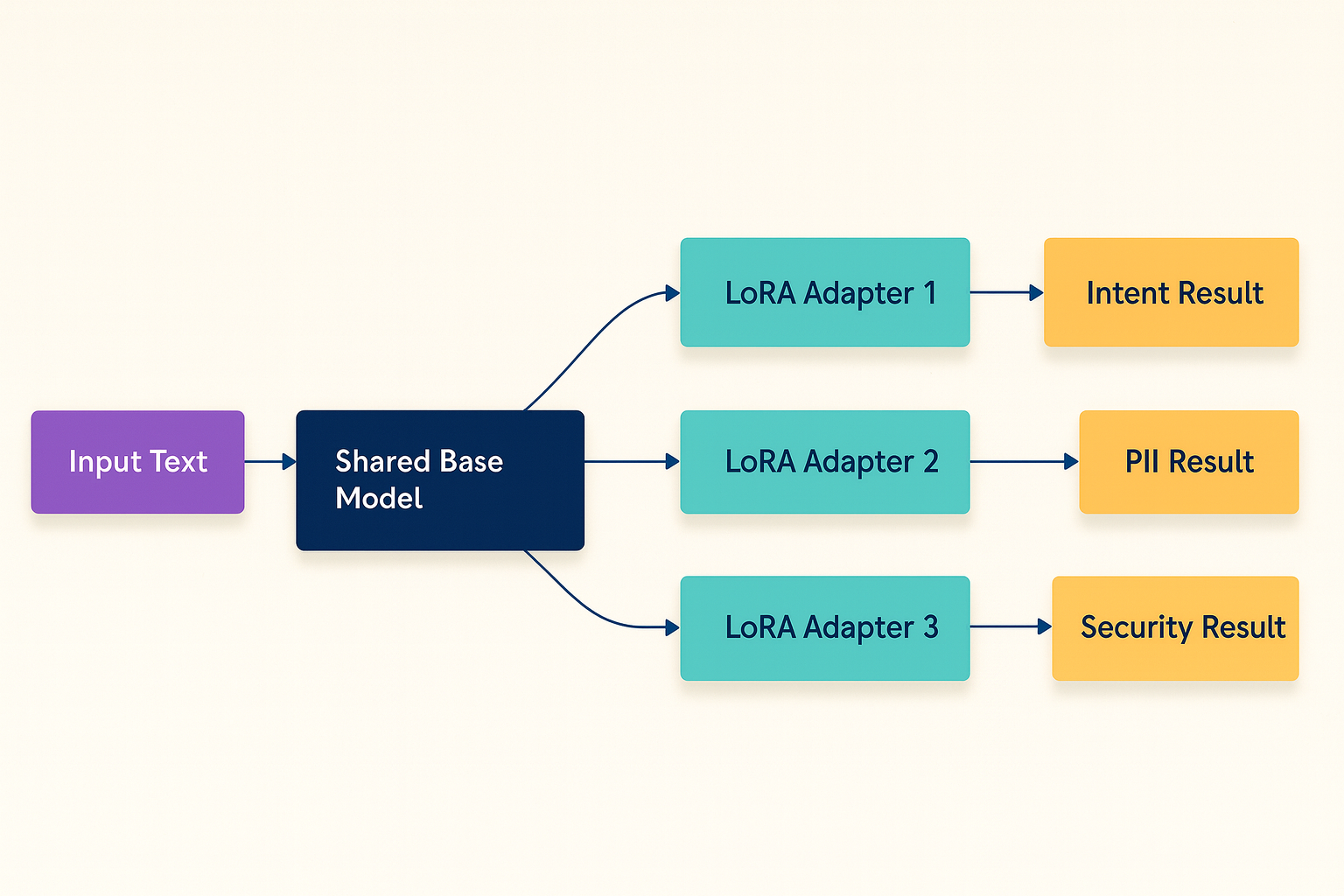
Image Credit: vLLM
Efficiency and Parallelism with LoRA
Traditional routing would run full models for every classification, multiplying costs with each new task. With LoRA, the input goes through the base model once; lightweight adapters then handle different tasks in parallel.
As these adapters modify less than 1% of the model's parameters, the system achieves dramatic speedups and lower memory usage. Parallelism via Rayon ensures tasks are completed swiftly, transforming labor-intensive workloads into streamlined processes.
Concurrency without Compromise
Scalability doesn't stop at model architecture. By moving from lazy_static to OnceLock, the system enables concurrent, lock-free access to classifier states post-initialization. This design means the router can scale linearly with CPU cores, maintaining responsiveness even under heavy traffic, a critical advantage for real-world deployments.
Turbocharging Inference with Flash Attention
Support for Flash Attention 2 brings GPU acceleration to both ModernBERT and Qwen3 models, optimizing memory access and slashing inference times for long-context documents. With potential 3–4× speedups, teams can process larger workloads without bottlenecks. Notably, this feature is optional, preserving efficiency for both GPU and CPU deployments.
Bridging Rust and Go for Cloud-Native Flexibility
While Rust powers the core ML inference engine, Go remains essential for cloud-native components like API gateways and orchestration. Exposing Rust logic through Go FFI bindings allows seamless integration, offering flexible deployment options, whether as embedded libraries for low-latency operations or isolated services for reliability. The extensible FFI layer sets the stage for future support in languages like Python, Java, and C++.
The Road Ahead
- Multi-task efficiency: LoRA enables simultaneous tasks with minimal redundancy.
- Long-document support: Models like Qwen3-Embedding tackle very large inputs
- Multilingual capability: Expanded model support unlocks global coverage.
- Max concurrency: OnceLock boosts throughput for demanding applications.
- GPU acceleration: Flash Attention delivers fast, scalable inference.
The modular, efficient foundation now in place means the router is ready to integrate new models, experiment with further quantization, and expand to more programming languages. The future of semantic routing is both flexible and powerful.
Resources
Source:vLLM Blog


Modular Architecture and LoRA Supercharge Semantic Routing Efficiency