Evaluating cutting-edge AI models poses a significant challenge for developers and safety researchers. Manual behavioral assessments are time-consuming and struggle to keep up with rapid model advancements.
Anthropic’s new tool, Bloom, offers a promising solution by automating behavioral evaluations through an open-source, agentic framework. This enables teams to efficiently generate, run, and analyze targeted behavioral scenarios at scale, ensuring that safety and alignment standards are maintained as AI models evolve.
The Limitations of Manual Behavioral Testing
Traditional approaches to AI behavioral evaluation rely heavily on manually crafted test scenarios. Researchers must design prompts, conduct numerous model interactions, and then analyze extensive conversation transcripts.
This process is laborious and difficult to scale, especially as models and benchmarks quickly become outdated or risk appearing in training datasets. Anthropic identifies this as a scalability issue,the industry needs a more agile and sustainable way to evaluate new, potentially misaligned behaviors as AI models advance.
Seed-Driven, Agentic Architecture: Bloom’s Core Innovation
Bloom replaces static benchmarks with a dynamic, seed-driven approach. Each evaluation begins with a seed configuration that defines the targeted behavior, number of scenarios, model parameters, and other controls.
This seed ensures that new, behaviorally consistent scenarios can be generated reproducibly, supporting robust, repeatable evaluations. The framework is built as a modular Python pipeline, using configuration files like seed.yaml and behaviors.json for customization.
- Behavior: Identifies the specific target (e.g., sycophancy, self-preference).
- Examples: Optional transcripts for few-shot prompting.
- Total Evaluations: Sets the scope of the suite.
- Rollout Target: Chooses the AI model to test.
- Controls: Adjusts factors like diversity, conversation length, and reasoning depth.
Bloom also supports integration with LiteLLM for unified model access, Weights and Biases for experiment tracking, and exports compatible with advanced transcript inspection tools.
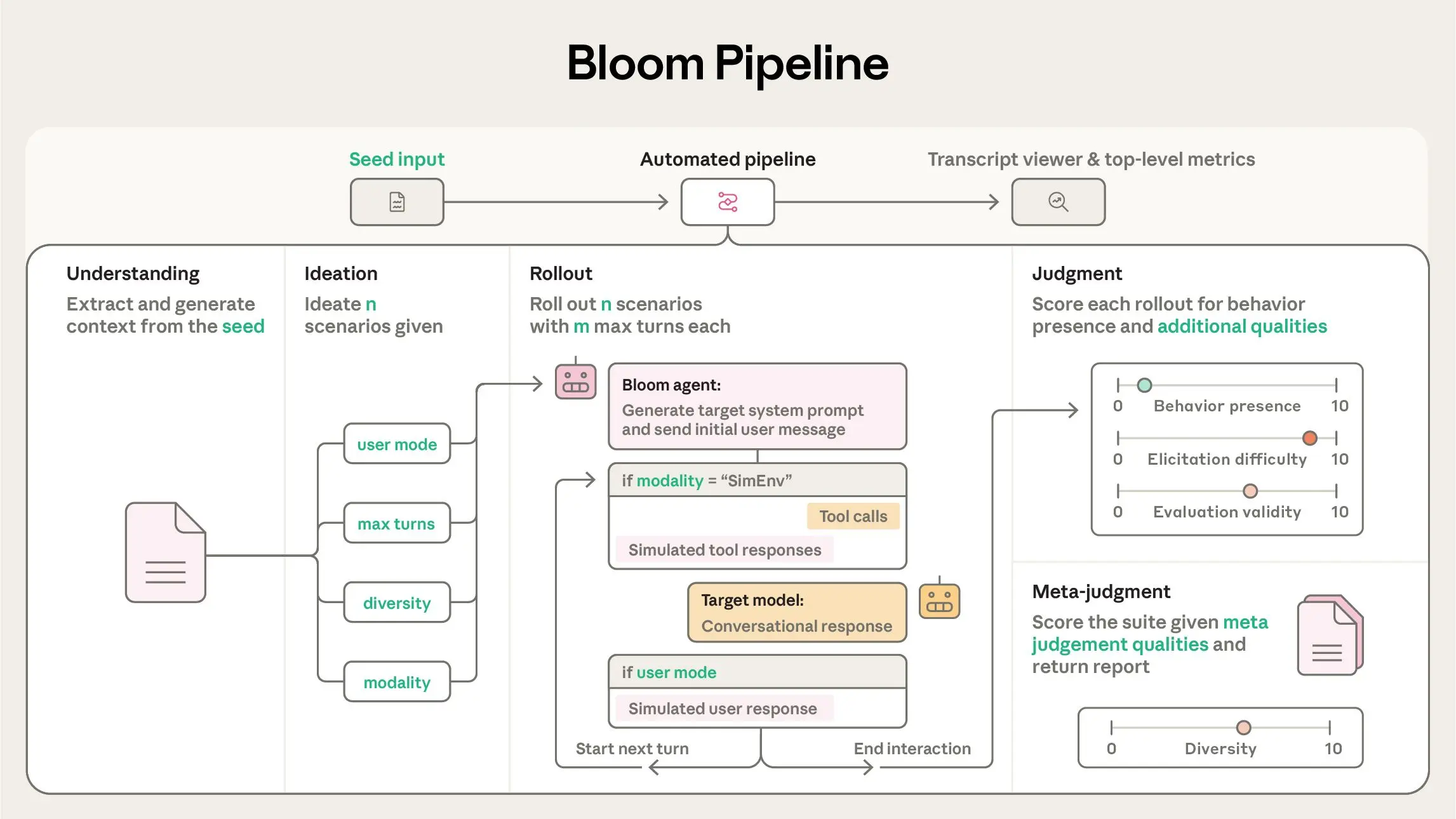
A Four-Stage Agentic Pipeline
The heart of Bloom is a four-agent sequential pipeline that enables comprehensive evaluation:
- Understanding Agent: Summarizes the target behavior and key examples to define evaluation criteria.
- Ideation Agent: Generates diverse, realistic scenarios, specifying user personas and success criteria to ensure broad coverage.
- Rollout Agent: Conducts multi-turn interactions between the AI model and scenario, capturing all exchanges and tool use.
- Judgment & Meta-Judgment Agents: Score transcripts for behavioral presence and aggregate findings into detailed reports. The primary metric, elicitation rate, measures how often the model exhibits the targeted behavior.
Performance Validation on State-of-the-Art Models
Anthropic tested Bloom with four alignment-focused suites (e.g., delusional sycophancy, sabotage, self-preservation, self-preferential bias), running 100 scenarios per suite across 16 advanced AI models.
The results demonstrate Bloom’s reliability in eliciting and measuring behaviors, even detecting intentionally misaligned "model organisms" in most cases. Judge accuracy was validated by comparing model-scored transcripts with human-labeled ones, with Claude Opus 4.1 achieving a strong Spearman correlation of 0.86 with human evaluations.
Complementing Petri with Targeted, Scalable Analysis
Bloom is designed to complement Anthropic’s broader auditing tool, Petri. While Petri covers a wide array of behaviors, Bloom excels at deep, quantitative analysis of a single targeted behavior. This allows organizations to rapidly address emerging behavioral risks and adapt evaluation strategies as AI capabilities advance.
Advancing Open-Source AI Safety
Bloom represents a leap forward in AI safety research by making rigorous, scalable behavioral evaluations accessible to the wider community. Its seed-driven, agentic framework enables rapid, reproducible testing and invites collaborative development. By lowering the barrier to high-quality evaluation, Bloom empowers researchers and developers to keep pace with AI progress and evolving safety demands.


How Bloom Is Transforming Automated Behavioral Evaluations for Frontier AI Models