Qwen3-Omni is a natively end-to-end, multilingual, omni-modal foundation model from the Qwen team at Alibaba Cloud. It can understand text, images, audio, and video, and respond in real time with both text and natural-sounding speech.
The repository brings everything together: models, usage cookbooks, a browser demo, and Docker images that make it practical to build multimodal apps quickly.
The headline promise is any-to-any interaction with state-of-the-art results across audio and audio-visual benchmarks, while keeping text and vision quality on par with single-modality peers. You can see this emphasis right in the project's README.md.

The Problem & The Solution
Today's AI landscape resembles a complex assembly line where separate models can handle speech, vision, and text processing. Each handoff introduces latency, context gets lost in translation between systems, and the promise of seamless real-time interaction remains frustratingly out of reach.
Qwen3-Omni introduces an elegant, end-to-end approach. Rather than orchestrating multiple specialized models, it offers a single, natively multimodal foundation that ingests audio, images, video, and text simultaneously.
The system's innovative "thinker–talker" architecture allows it to reason across all modalities with the thinker component, then respond through low-latency speech via the talker module. This unified design dramatically reduces system complexity while enabling the kind of natural, streaming interactions that feel truly conversational.
The technical report and comprehensive documentation in assets/Qwen3_Omni.pdf detail their MoE-based architecture and multi-codebook strategy that makes this low-latency magic possible (Qwen Team, 2025).
Key Features
- Omni-modal, any-to-any IO: Understands text, images, audio, and video; outputs text and low-latency speech. The Instruct checkpoint includes both the thinker (reasoning) and talker (TTS) modules; the Thinking checkpoint focuses on reasoning-only.
- Real-time streaming: Designed for low-latency, natural turn-taking, great for live voice or A/V co-pilots. The web demo in web_demo.py highlights this.
- Performance with balance: Strong results across 36 audio and audio-visual benchmarks, with text and vision quality preserved. The README collates public comparisons and benchmark settings.
- Developer-first pathways: Support for Transformers and vLLM, plus an API route. A prebuilt Docker image keeps environments reproducible.
- Detailed audio captioner: Qwen3-Omni-30B-A3B-Captioner is provided for fine-grained, low-hallucination audio descriptions, an open-source gap-filler.
Why I Like It
This repo balances ambitious research with developer pragmatism. You get a realistic path to production: Hugging Face Transformers for completeness, vLLM for throughput and latency, and a ready-to-run Docker image for clean environments.
The cookbooks aren't marketing fluff, they're runnable notebooks with execution logs that showcase real tasks like multilingual ASR, video description, audio–visual dialogue, and fine-grained audio captioning, all linked from cookbooks/. That combination of breadth, depth, and ergonomics makes Qwen3-Omni feel practical, not just impressive.
Under the Hood
The repo exposes two primary usage paths.
First, Transformers: install from source (the model code has been merged upstream but may precede a PyPI cut), add FlashAttention 2 for memory efficiency, and use the project's qwen-omni-utils to package multi-modal inputs (base64, URLs, interleaved sequences).
Second, vLLM: build from source on a Qwen branch while audio-output support stabilizes, and take advantage of tensor parallelism and the engine's batching to scale.
The docs discuss memory envelopes for BF16 across video lengths, prompts for A/V interaction, and best practices for the thinking-only model. For a self-contained experience, and to avoid CUDA/driver mismatches, the team ships qwenllm/qwen3-omni, mapping host ports and a shared workspace.
These choices aim for a balance of performance (MoE, streaming), practicality (Docker, vLLM), and developer productivity (cookbooks, utilities). For background on high-throughput inference, see the vLLM documentation (vLLM, 2025).
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
model_id = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
model_id, dtype="auto", device_map="auto", attn_implementation="flash_attention_2"
)
processor = Qwen3OmniMoeProcessor.from_pretrained(model_id)
messages = [{
"role": "user",
"content": [
{"type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cars.jpg"},
{"type": "text", "text": "One-sentence description?"}
]
}]
text = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(messages, use_audio_in_video=True)
inputs = processor(text=text, audio=audios, images=images, videos=videos,
return_tensors="pt", padding=True, use_audio_in_video=True)
inputs = inputs.to(model.device).to(model.dtype)
text_ids, audio = model.generate(**inputs, speaker="Ethan", thinker_return_dict_in_generate=True, use_audio_in_video=True) 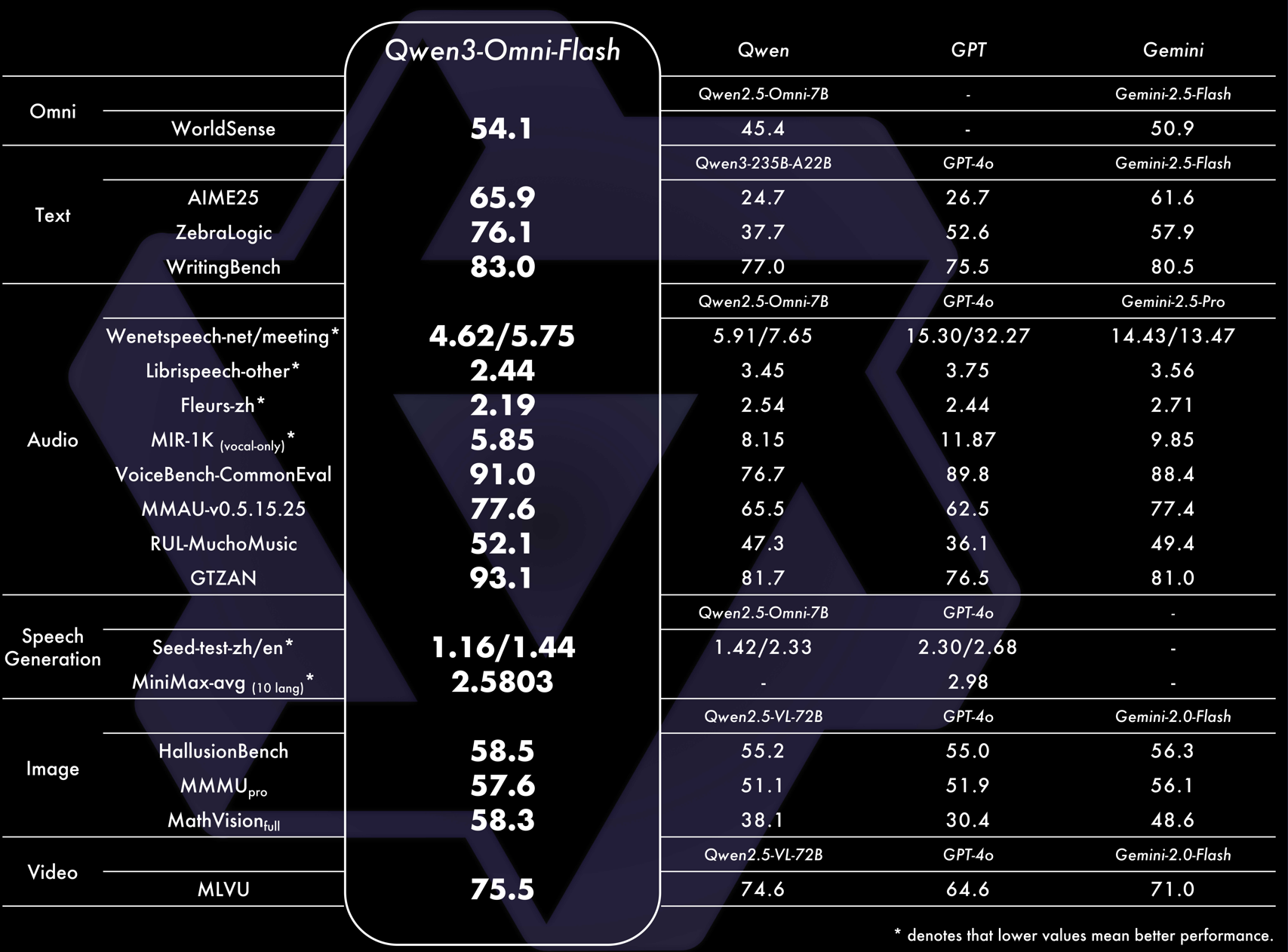
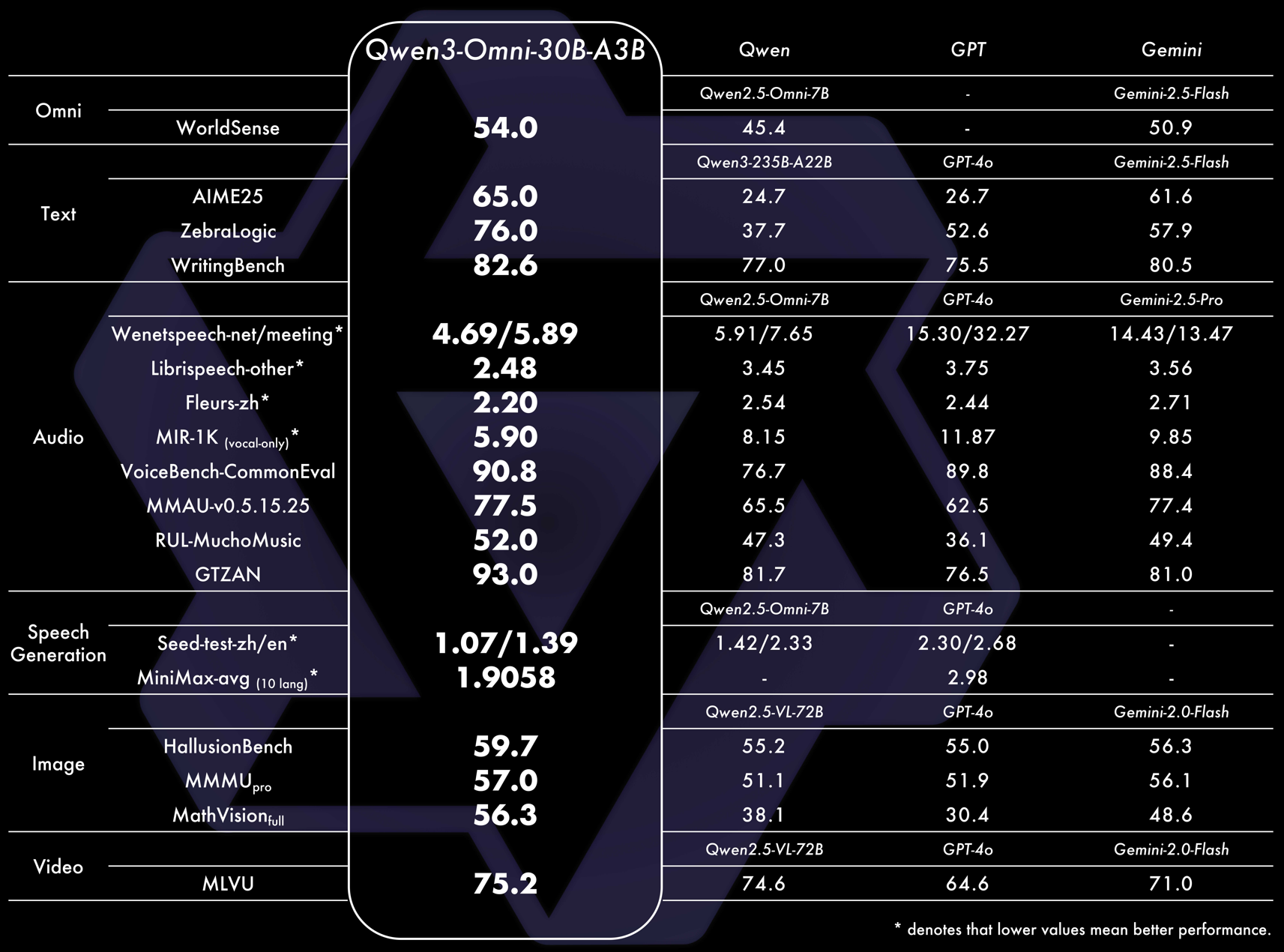
Image Credit: Qwen Team
Performance Benchmarks
Qwen3-Omni, which matches the performance of same-sized single-modal models within the Qwen series and excels particularly on audio tasks. Across 36 audio and audio-visual benchmarks, Qwen3-Omni achieves open-
source SOTA on 32 benchmarks and overall SOTA on 22, outperforming strong closed-source models such as Gemini-2.5-Pro, Seed-ASR, and GPT-4o-Transcribe.
Use Cases
Qwen3-Omni's demos and cookbooks reveal a rich tapestry of practical applications that span industries and use cases. The model's ability to seamlessly process and generate across text, audio, video, and image modalities opens up possibilities that were previously difficult or impossible with single-modal systems.
Healthcare and Medical Imaging
Medical professionals can leverage Qwen3-Omni for comprehensive patient consultations where they describe symptoms verbally while simultaneously analyzing medical images, X-rays, or video footage of patient movements. The model can provide real-time analysis combining visual medical data with spoken patient histories, offering a more holistic diagnostic support tool. This mirrors the approach that companies like IBM are exploring in their multimodal AI healthcare initiatives, where combining different data types leads to more accurate medical insights.
Interactive Education and Training
Educational institutions can create immersive learning experiences where students can ask questions about historical photographs, scientific diagrams, or complex mathematical concepts while receiving both visual and auditory explanations. Language learning becomes particularly powerful when students can practice conversations while looking at contextual images or videos, receiving immediate feedback on pronunciation, grammar, and cultural context understanding.
Enhanced Accessibility Solutions
Building on initiatives like OpenAI's collaboration with Be My Eyes, Qwen3-Omni can provide comprehensive scene descriptions that go beyond static image analysis. Users with visual impairments can receive real-time audio descriptions of their surroundings, including movement, ambient sounds, and contextual information that helps them navigate both physical and digital spaces more effectively.
Next-Generation Customer Support
Customer service operations can move past traditional chat or phone support by enabling agents to simultaneously view customer-submitted photos or videos of product issues while maintaining natural voice conversations. For instance, a customer experiencing technical difficulties with a device can show the problem via video call while describing the issue, and the AI can provide step-by-step visual and audio guidance for resolution.
Creative Industries and Content Production
Content creators, journalists, and marketers can use Qwen3-Omni to automatically generate comprehensive multimedia content. A journalist could take photos at an event, record ambient audio, and receive automatically generated articles with rich descriptions that capture both the visual and auditory atmosphere. This streamlines content production while maintaining narrative depth and sensory richness.
Intelligent Security and Monitoring Systems
Security applications can benefit from real-time analysis of video surveillance feeds combined with audio detection, providing security personnel with comprehensive situational awareness. The system can simultaneously process visual anomalies and audio cues, generating detailed reports that combine what is seen and heard in security environments.
Scientific Research and Data Analysis
Researchers across disciplines can leverage Qwen3-Omni's capabilities to analyze complex datasets that include visual charts, graphs, video recordings of experiments, and audio logs. The model can help scientists identify patterns across multiple data modalities simultaneously, potentially accelerating discovery processes in fields ranging from behavioral psychology to environmental science.
Each of these applications maps directly to the practical notebooks available in cookbooks/, providing developers with ready-to-implement examples that can be adapted for specific industry needs. The repository's comprehensive approach makes these advanced use cases accessible to organizations of all sizes.
Community & Contribution
At launch, the repository itself shows no open issues or pull requests, unsurprising for a fresh release but the broader Qwen ecosystem is highly active across adjacent repos (Qwen3, Qwen-Agent, Qwen-Image). You can engage via the org's channels (GitHub, Discord, WeChat) linked from the repo and org profile (QwenLM).
If you plan to contribute, start by exploring README.md, the cookbooks, and the demo scripts; most projects in the org follow standard contribution etiquette even when a CONTRIBUTING.md is not present. For usage support and managed access, the real-time API and offline API are documented by Alibaba Cloud.
Usage & License Terms
Qwen3-Omni is released under the Apache License 2.0 (LICENSE). In brief, the license permits commercial use, modification, distribution, and private use, and includes a patent grant. You must include a copy of the license and retain notices in source distributions; if a NOTICE file is present, keep its attributions in your distributions or documentation. There is no warranty; use is at your own risk. This permissive licensing is a strong signal that the team wants broad experimentation and integration.
Impact & What's Next
End-to-end, real-time models are reshaping the HCI surface of AI, from call centers and voice UIs to live A/V copilots for field work. Qwen3-Omni's architecture and tooling land at a sweet spot: competitive benchmarks, a practical path to deployment (vLLM, Docker, APIs), and a gallery of reproducible tasks. Expect accelerated integrations with agent frameworks (for example, Qwen-Agent) and richer guardrails, plus tighter loops between thinking-only reasoning and speech output. As vLLM support for audio output matures, the operational story will get even cleaner. If you're building multimodal experiences, this is a compelling open-source baseline.
About Qwen (Alibaba Cloud)
Qwen is Alibaba Cloud's AI model team, shipping the Qwen and Qwen3 series (general, coding, vision, embedding) and a growing ecosystem of tools. The organization's public profile lists the website, blog, and social channels, with active development across Python, Jupyter, and TypeScript projects. Learn more at qwen.ai, the org page on GitHub (QwenLM), and the official blog (qwenlm.github.io).
Conclusion
Qwen3-Omni stands out for its native multimodality, real-time speech, and developer-first packaging. It solves a messy integration problem with a unified "thinker–talker" design and backs it up with runnable cookbooks and a clean path to deployment. Explore the code, try the demos, and adapt the cookbooks to your data—then share what you build. Start with the README, browse cookbooks, and, if you prefer a managed route, check the Hugging Face collection and Alibaba Cloud APIs. Happy building.


Qwen3-Omni: Native Any-to-Any Multimodality, Now Practical