Large Language Models (LLMs) have ushered in a new era of artificial intelligence, demonstrating unparalleled abilities in understanding and generating complex human language.
However, a fundamental challenge persists: these powerful models are inherently static.
Once their extensive pretraining on vast text corpora is complete, they largely lack the internal mechanisms to dynamically and persistently adapt their weights in response to new tasks, incoming knowledge, or novel examples.
This rigidity presents significant hurdles when attempting to tailor LLMs for highly specific applications, integrate continuously evolving information, or enable them to master new reasoning skills, especially given the often-limited availability of task-specific data.
Addressing this critical limitation, recent research introduces Self-Adapting LLMs (SEAL), a pioneering framework that empowers these models to become active participants in their own learning and refinement.
By generating their own finetuning data and specifying the directives for their internal updates, SEAL aims to transform LLMs from passive knowledge reservoirs into dynamic, self-improving intelligent systems.
Key Takeaways
- Autonomous Adaptation: SEAL enables LLMs to self-adapt by generating their own finetuning data and the necessary update directives, fundamentally shifting from static models to dynamic, adaptive ones.
- Reinforcement Learning for Self-Edits: The core of SEAL involves a reinforcement learning (RL) loop that trains the LLM to produce effective "self-edits", natural-language instructions that guide the model's weight updates, using the updated model's downstream performance as the reward signal.
- Direct Generative Control: Unlike prior adaptation methods that rely on separate modules or auxiliary networks, SEAL directly leverages the LLM's inherent generative capabilities to parameterize and control its own adaptation process.
- Superior Knowledge Incorporation: In tasks requiring the integration of new factual knowledge, SEAL-generated synthetic data has demonstrated superior performance, notably outperforming synthetic data produced by more powerful models like GPT-4.1 in question-answering tasks without context.
- Enhanced Few-Shot Generalization: SEAL significantly improves few-shot learning by autonomously selecting and configuring data augmentations and optimization hyperparameters, demonstrating its ability to intelligently manage its own adaptation pipeline.
- Pathway to Continual Learning and Agentic Systems: The framework is a promising step towards enabling continual learning, where models can integrate new information over time without catastrophic forgetting (though this remains a challenge), and for building agentic systems that adapt dynamically through extended interactions.
- Addressing the "Data Wall": SEAL offers a visionary solution to the impending "data wall" for LLM training by allowing models to generate their own high-utility training signals, fostering continued scaling and data efficiency even as human-generated text becomes exhausted.
Overview
Traditionally, Large Language Models (LLMs) are trained and deployed by directly consuming and learning from existing task data, typically through processes like finetuning or in-context learning. However, this "as-is" approach often means that the input data might not be in the most optimal format or sufficient volume for truly effective learning and adaptation.
A critical gap in current LLM capabilities is their inability to develop and execute bespoke strategies for transforming and learning from their own training data. This inflexibility impedes their capacity to integrate new information or acquire novel reasoning skills, especially when domain-specific data is scarce.
To conceptualize SEAL's approach, consider the human learning process: when preparing for an exam, a student often doesn't just reread raw lecture notes or textbooks. Instead, they assimilate, restructure, and rewrite the information in their own words, perhaps by creating summaries, diagrams, or rephrasing complex concepts.
This active reinterpretation and augmentation of external knowledge significantly enhances understanding. Critically, different individuals adopt different learning strategies, some condense, some visualize, others detail mathematical descriptions.
SEAL aims to endow LLMs with an analogous capacity for self-directed assimilation and restructuring of information as part of their learning process.
The core of the SEAL framework involves equipping LLMs with the ability to generate "self-edits", natural-language instructions that specify how to update the model's own weights, including the data to be used and, optionally, optimization hyperparameters. This process is governed by a sophisticated reinforcement learning (RL) outer loop that optimizes the generation of these self-edits.
This method stands in stark contrast to previous approaches that might rely on separate adaptation modules or auxiliary networks, as SEAL directly leverages the LLM's existing generative capabilities to control its own adaptation.
The operational mechanism of SEAL is elegantly structured into two nested loops, as depicted in Figure 1.

Figure 1: Overview of SEAL. In each RL outer loop iteration, the model generates candidate self-edits (SE)—directives on how to update the weights—applies updates, evaluates performance on a downstream task, and uses the resulting rewards to improve the self-edit generation policy.
- The inner loop performs a supervised finetuning (SFT) update: given a context `C`, the language model generates a self-edit, which then guides the update of the model's parameters to new parameters.
- The outer RL loop then evaluates the performance of this updated model on a specific downstream task.
- The outcome of this evaluation provides a reward signal, which is used to update the model's policy for generating self-edits, aiming to maximize expected future rewards.
The authors note that the dynamic nature of this reward (which depends on the model's current parameters) necessitates an on-policy RL approach to avoid using stale data.
While various on-policy methods like Group Relative Policy Optimization (GRPO) and Proximal Policy Optimization (PPO) were explored, the simpler ReSTEM approach (a form of filtered behavior cloning or "rejection sampling + SFT") was chosen due to its stability in training. This approach effectively optimizes an approximation of the objective by reinforcing only those self-edits that yield a positive performance improvement.
Why it’s important
The advent of Self-Adapting LLMs (SEAL) marks a pivotal moment in the evolution of artificial intelligence, addressing what many foresee as a fundamental constraint for future LLM scalability: the "data wall".
As the reservoir of publicly available human-generated text, which forms the bedrock of current LLM training, is projected to be exhausted by 2028, progress will increasingly hinge on a model's capacity to generate its own high-utility training signals.
SEAL offers a groundbreaking solution by empowering LLMs to create their own training data, ensuring continued progress and data efficiency even when external human data becomes scarce. This represents a profound shift from models that passively consume information to those that actively engage in their own learning and refinement.
Beyond merely overcoming data limitations, SEAL's ability to facilitate persistent weight updates through self-generated data holds transformative implications across numerous AI domains.
For knowledge incorporation, SEAL allows LLMs to efficiently embed new factual information directly into their weights, making it retrievable without the need for constant contextual prompting. This is crucial for applications demanding up-to-date information, such as real-time news analysis or specialized scientific inquiries, where manual fine tuning is impractical.
Similarly, in few-shot learning, SEAL's demonstrated capacity to autonomously configure adaptation pipelines, selecting optimal data augmentations and training parameters, can drastically reduce the manual effort and expert knowledge typically required to adapt models to novel, data-poor tasks, helping to accelerate deployment and improving generalization.
SEAL fosters a promising path towards true continual learning and self-improvement in LLMs. Envision an LLM that can ingest a new academic paper, analyze its content, and then generate extensive explanations and logical implications for itself, seamlessly integrating this new knowledge with its existing understanding.
This iterative loop of "self-expression and self-refinement" could enable models to continuously deepen their understanding of rare or underrepresented topics, independent of additional external human supervision. Such a capability is particularly compelling for developing agentic systems, AI models designed to operate over extended periods, interact dynamically with environments, and adapt to evolving goals.
These agents inherently need to incrementally acquire and retain knowledge throughout their operational lifespan. SEAL’s structured self-modification mechanism allows an agent to synthesize a "self-edit" after an interaction, triggering a weight update that aligns its behavior with prior experiences and reduces reliance on repeated external supervision.
The potential for synergy with other advancements in AI is also significant. While modern reasoning models often use reinforcement learning to generate intricate "chain-of-thought" (CoT) traces for complex problem-solving, SEAL introduces a complementary mechanism by teaching the model when and how to update its own weights.
This integration could lead to sophisticated LLMs that choose to perform weight updates mid-reasoning to guide their current trajectory, or distill key insights into their parameters after completing a complex reasoning process, thereby enhancing future inference through internalized learning.
In essence, SEAL pushes LLMs closer to a state of genuine artificial general intelligence, where they can autonomously learn, adapt, and evolve in response to new information and experiences, paving the way for more robust, efficient, and intelligent AI systems.
Summary of Results
The efficacy of the Self-Adapting LLMs (SEAL) framework was empirically validated across two distinct yet complementary adaptation domains: knowledge incorporation and few-shot learning. These experiments aimed to demonstrate SEAL's ability to both internalize new information persistently and generalize effectively from limited examples.
Few-Shot Learning
For few-shot learning, experiments utilized Llama-3.2-1B-Instruct, a small open-source model. To ensure a controlled evaluation focusing on self-edit learning rather than general abstract reasoning capabilities, a specific subset of tasks from the ARC-AGI benchmark was curated: 11 for training and 8 for evaluation. These tasks were chosen because they were known to be solvable under optimal Test-Time Training (TTT) configurations for the base model.
The training process for SEAL involved a single outer loop of reinforcement learning applied to the 11 training problems.
For each problem, the model generated 15 self-edit configurations. These configurations involved two main decisions:
- Data augmentation strategy: Whether to include variations like `basic_augmentations`, `size_augmentations`, `chained_reasoning`, and `repeated_inputs`.
- Optimization configuration: Specifications for hyperparameters such as `learning_rate`, `num_train_epochs`, and the type of loss function (e.g., computed over all tokens or only output tokens).
Each generated configuration was then evaluated via Test-Time Training (TTT), and a binary reward (1 for correct solution, 0 otherwise) was assigned based on the adapted model's performance. To promote efficient adaptation, only configurations that yielded a positive reward and were computationally acceptable for LoRA-based Supervised Finetuning (SFT) were retained for reinforcement.
The evaluation of the trained model involved generating 5 self-edit configurations for each of the 8 held-out evaluation tasks. Success was measured as the percentage of these configurations that led to correct outputs after adaptation.
SEAL's performance was rigorously compared against several baselines:
- ICL (In-Context Learning): The base Llama-3.2-1B-Instruct model was directly prompted with few-shot examples and queried on the test input.
- TTT + Self-Edit (w/o prior RL): The base model performed TTT using few-shot examples and synthetic augmentations, but without any prior RL training to optimize the selection of augmentations or training configurations.
- Oracle TTT: This represented an upper bound, where the model performed TTT using the optimal, human-crafted configuration from prior research.
The results, presented in Table 1, clearly highlight SEAL's significant advantage:

SEAL achieved a success rate of 72.5%, a substantial improvement over the TTT + Self-Edit baseline without prior RL (20%) and ICL (0%). While its performance did not reach the Oracle TTT's perfect 100%, these findings underscore SEAL's effectiveness in learning to autonomously configure the adaptation pipeline, thereby significantly enhancing LLM generalization capabilities from limited examples. This is further illustrated by the conceptual flow in Figure 3, which outlines how SEAL generates adaptation directives for few-shot learning.
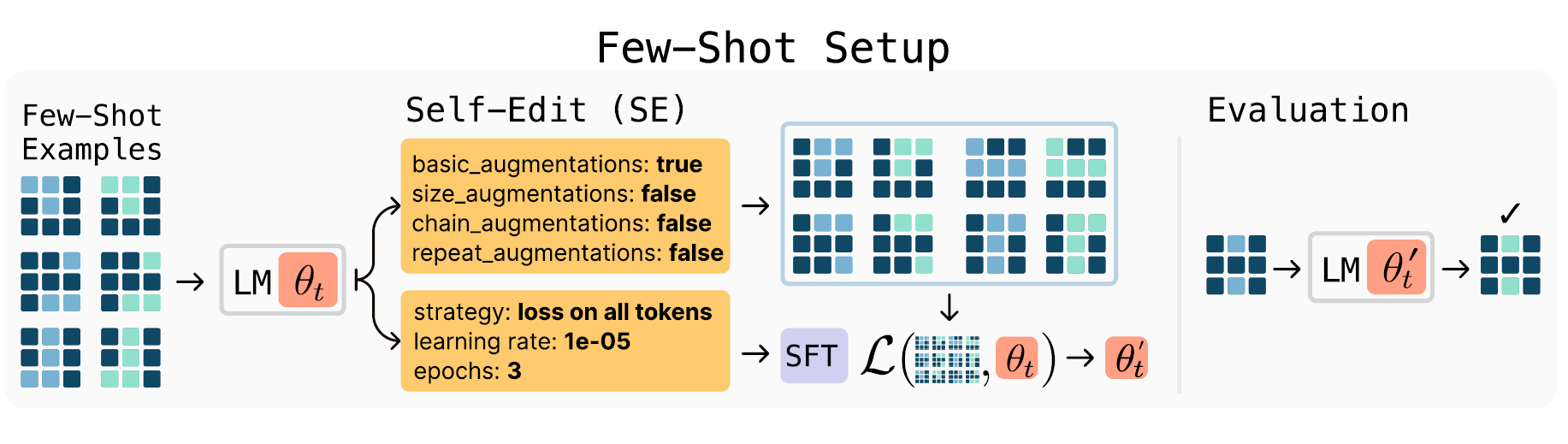
Figure 3: Few-Shot Learning with SEAL. Left: example ARC demonstrations. Center: the model generates a self-edit specifying augmentations and training hyperparameters. Right: the adapted model is evaluated on a held-out test input.
Knowledge Incorporation
For the task of incorporating novel factual knowledge, the Qwen2.5-7B base model was employed, with the SQuAD dataset v1.1 repurposed for question-answering without the passage in context. This setup directly tested the model's ability to internalize information into its weights for subsequent recall.
The training regimen consisted of 2 rounds of ReSTEM. In each round, a batch of 50 context-question-answer triples from the SQuAD training set was used. For every context, 5 self-edit generations were sampled at a temperature of 1. Each self-edit was then evaluated by finetuning the model on the generated content and assessing the updated model's performance on the corresponding questions.
The single best generation for each context was selected to form the dataset for the subsequent supervised finetuning round. The self-generated content primarily took the form of "implications" derived from the passage, prompted by instructions like "List several implications derived from the content". The accuracy of the adapted model on these questions served as the reward signal for the RL optimization.
SEAL's performance in knowledge incorporation was benchmarked against the following approaches:
- Base Model: The pretrained Qwen2.5-7B model evaluated without any adaptation or access to the passage.
- Train on Passage Only: The model was finetuned directly on the raw passage text using standard language modeling loss, without synthetic data.
- Train on Passage + Synthetic Data: The model was trained on the passage along with self-generated implications, but without any prior RL training to optimize their generation.
- Train on Passage + GPT-4.1 Synthetic Data: The model was trained on the passage and implications generated by GPT-4.1 via the OpenAI API.
The results, detailed in Table 2, were reported for two distinct regimes: single-passage (n=1) and continued pretraining (CPT, n=200):
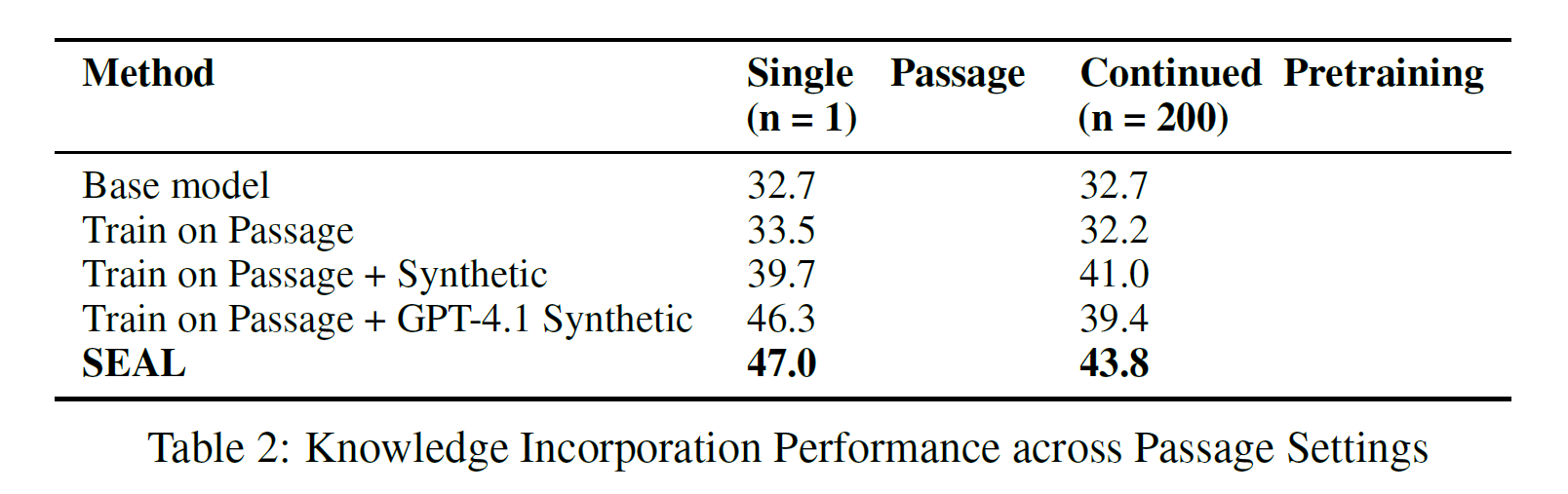
In the single-passage setting, finetuning on the raw passage alone offered a negligible improvement (33.5%) over the base model (32.7%), confirming that raw data alone is insufficient for effective knowledge incorporation.
Synthetic implications generated by GPT-4.1 boosted accuracy to 46.3%. Remarkably, after reinforcement learning, SEAL further improved accuracy to 47.0%, outperforming the synthetic data produced by GPT-4.1, despite SEAL leveraging a much smaller Qwen-2.5-7B model. This underscores SEAL’s ability to generate highly effective training signals through its self-adaptive process.
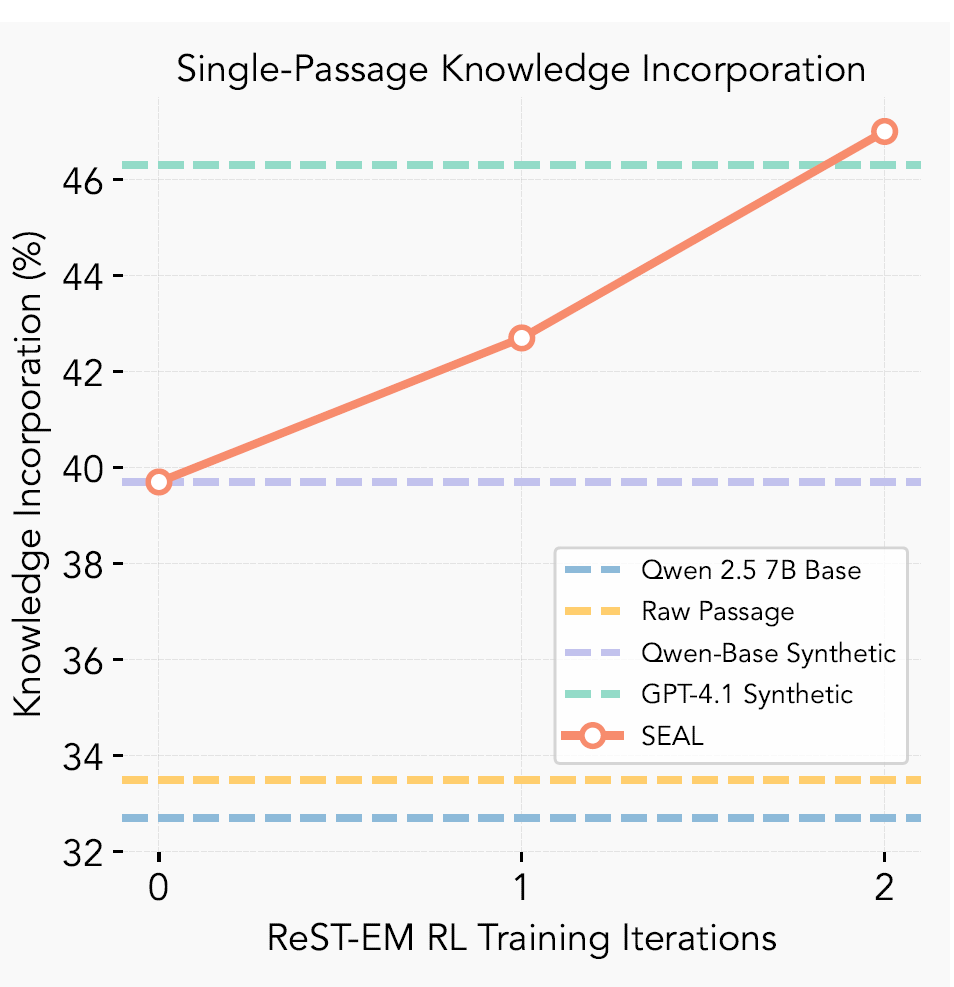
Figure 4: Accuracy over RL iterations. Each iteration consists of a mini-batch of 50 contexts, each with 5 sampled self-edits. SEAL surpasses GPT-4.1 synthetic data after two iterations of ReSTEM on the no-context SQuAD set.
Figure 4 illustrates the rapid convergence of SEAL's policy, demonstrating that it overtakes GPT-4.1 data within just two reinforcement learning iterations, with subsequent iterations yielding diminishing returns. Qualitative examples, such as those in Figure 5, show how RL training leads to the generation of more detailed and effective self-edits over time, which directly correlates with improved performance.

Figure 5: Example Knowledge Incorporation Self-Edits Across RL Iterations. In this example, we see how RL leads to the generation of more detailed self-edits, which in turn results in better performance. While the progression is clear in this case, the differences across iterations are sometimes more subtle in other examples. We show in §C that prompting for longer self-edits is effective, and that RL training further improves performance by a similar margin.
In the continued pretraining (CPT) setting, where the model assimilated information from 200 passages, SEAL again demonstrated superior performance, achieving 43.8% accuracy. Although the absolute performance was lower than in the single-passage case (likely due to increased gradient interference from the larger dataset), the consistent relative improvements suggest the learned editing policy generalizes effectively beyond single-passage scenarios.
The researchers also investigated the impact of various prompt types for self-edit generation in knowledge incorporation (Table 6). While certain prompts like "implications-long" or "rewrite" could yield higher baseline performance than the canonical "implications" prompt, the key finding was that RL training consistently enhanced performance across all prompt types by approximately 6 to 11 percentage points. This indicates that SEAL's RL framework effectively boosts the utility of self-generated data regardless of the initial prompting strategy employed.

Table 6: Performance across 2 rounds of ReSTEM RL training on various prompts in the single-document knowledge incorporation setting.
Limitations
Despite its compelling advancements, the SEAL framework does face certain limitations. A prominent challenge is catastrophic forgetting, where sequential updates to integrate new information can destructively interfere with previously learned knowledge.
Although experiments simulating continual learning showed a gradual decline in performance on earlier tasks as more self-edits were applied, the model avoided complete collapse, indicating potential for future improvement. Figure 6 visualizes this observed degradation in retention.
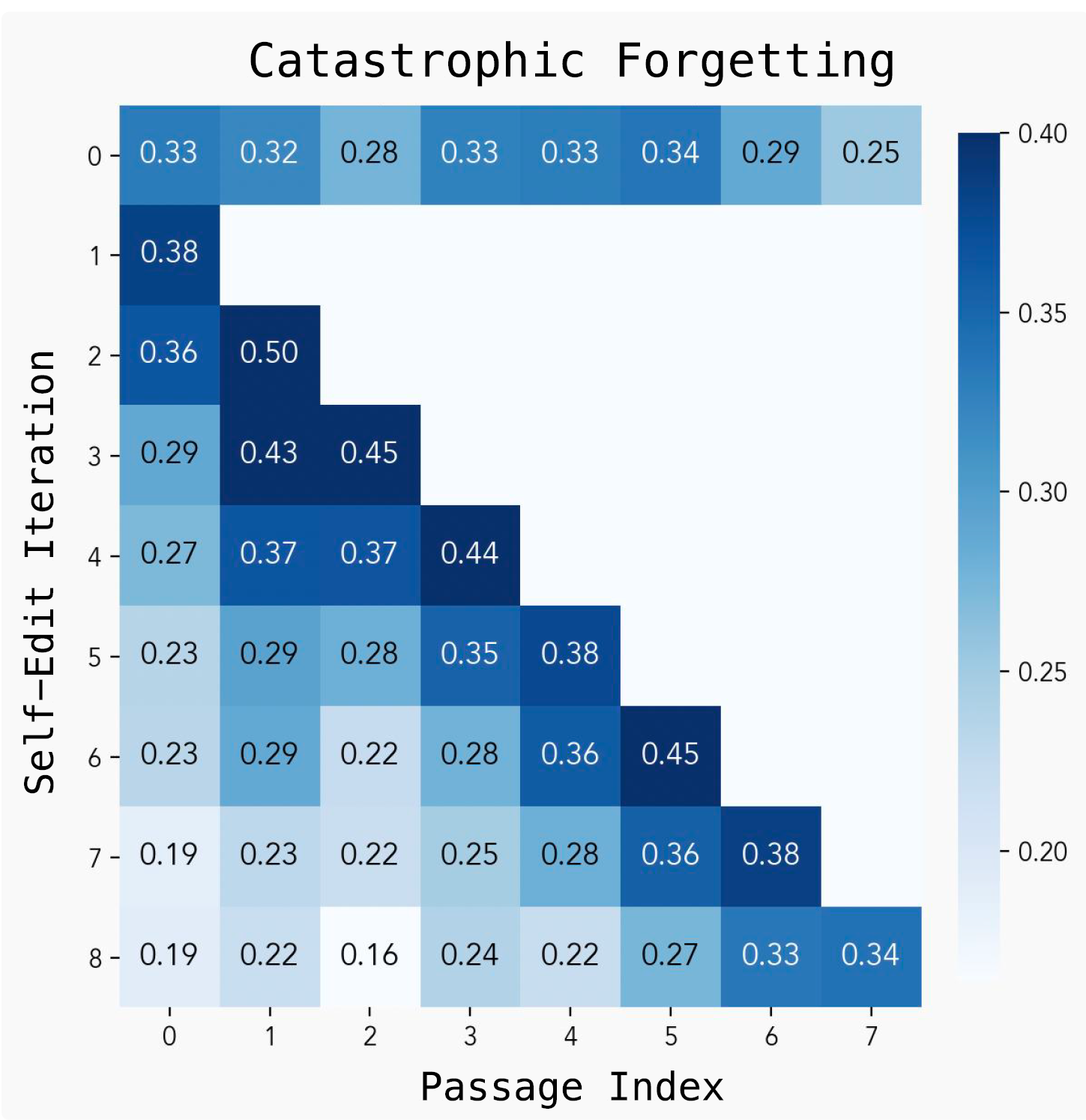
Figure 6: Catastrophic forgetting from continual self-edits. We sequentially update the model on new passages and track degradation on prior tasks.
Another practical consideration is the computational overhead. Unlike simpler reinforcement learning loops, where reward signals might be computed from a single model forward pass, SEAL's approach necessitates a full model finetuning and evaluation for each self-edit, which can take approximately 30-45 seconds per evaluation, incurring substantial computational costs.
Lastly, the current instantiations of SEAL rely on context-dependent evaluation, meaning each context must be accompanied by an explicit downstream task and ground-truth for accurate reward computation. This reliance restricts its scalability to truly unlabeled corpora, though the authors propose a potential solution where the model could generate its own evaluation questions to provide immediate supervision, broadening applicability to general training domains.
Conclusion
The Self-Adapting LLMs (SEAL) framework marks a conceptual and practical advancement in the field of artificial intelligence, transitioning Large Language Models from static, pre-trained entities to dynamic, self-improving systems.
By empowering LLMs to autonomously generate their own finetuning data and specify adaptation directives, a process term coined as "self-editing", SEAL directly confronts the critical challenges of data scarcity for specialized tasks and the inherent rigidity that has limited the continuous evolution of existing models.
The innovation lies in its sophisticated reinforcement learning loop, which trains the model to produce these self-edits, optimizing for the actual downstream performance of the model after it has updated its own weights. This research may be setting the stage for consistently evolving AI which continues to assimilate information much like ourselves. The fact that SEAL can lose track of previous “memories” draws an interesting parallel to how humans can process a limited amount before losing track.
Through comprehensive experimental validation, SEAL has demonstrated remarkable capabilities across two critical domains: knowledge incorporation and few-shot learning. In the former, its ability to internalize new factual information has been shown to be exceptionally effective, even surpassing the quality of synthetic data generated by a larger, external model like GPT-4.1.
For few-shot learning, SEAL exhibits a sophisticated capacity to autonomously configure its own adaptation pipeline, leading to significantly enhanced generalization from minimal examples. These collective results underscore SEAL's versatility and its potential to fundamentally reshape how LLMs acquire, retain, and apply knowledge.
While the framework currently grapples with challenges such as catastrophic forgetting and considerable computational overhead, the research clearly delineates pathways for future development. These include integrating advanced continual learning strategies to mitigate forgetting or empowering models to generate their own evaluation questions, thus enabling unsupervised learning from raw, unlabeled data.
Ultimately, SEAL lays a robust foundation for a future where LLMs can continuously refine their understanding, adapt to emergent challenges, and function as truly agentic systems that learn and evolve through ongoing interaction with their environment. This shift towards self-directed adaptation is not merely an incremental enhancement but a transformative step towards more robust, efficient, and intelligent AI, particularly crucial as the availability of novel human-generated data becomes increasingly constrained.


The Dawn of Self-Adapting Language Models: A New Paradigm for AI Learning
Self-Adapting Language Models