The ability of language models to process and understand increasingly long texts, known as long-context language models (LCLMs), is unlocking a wide range of potential applications, from summarizing lengthy documents to learning from numerous examples simultaneously.
However, effectively evaluating the diverse capabilities of these models across realistic tasks presents a significant challenge. Many existing benchmarks often fall short, relying on synthetic tests that may not reflect real-world performance or focusing only on narrow domains.
This lack of comprehensive and reliable evaluation makes it difficult to compare different LCLMs and understand their strengths and weaknesses. The research introduces HELMET (How to Evaluate Long-context Models Effectively and Thoroughly), a new benchmark designed to address these limitations by providing a comprehensive and application-centric evaluation framework for LCLMs.
Interested in other Long Context Benchmark research? Checkout my LONGPROC research review! View
Key Takeaways
- Synthetic tasks like Needle-in-a-Haystack (NIAH) are not reliable predictors of performance on diverse downstream applications. While many LCLMs achieve perfect scores on NIAH, this does not guarantee strong performance on more complex, application-oriented tasks.
- The diverse categories included in HELMET exhibit distinct trends and have low correlations with each other. This suggests that different tasks require different capabilities from LCLMs, and strong performance in one area (like summarization) does not necessarily translate to strong performance in another (like question answering or generation with citations).
- Through a study of 59 LCLMs, the research found that while open-source models can match closed models on synthetic tasks like NIAH, they significantly lag behind closed models on tasks requiring full-context reasoning or complex instruction following. This performance gap tends to widen as the context length increases.
- The researchers recommend using Retrieval-Augmented Generation (RAG) tasks for faster model development. These tasks are easier to run than some others and show better correlation with performance on other downstream tasks.
- HELMET introduces model-based evaluation using large language models like GPT-4o as judges, addressing the known unreliability of traditional automatic metrics like ROUGE for long-context tasks.
- It also uses few-shot prompting to enable robust evaluation of both base and instruction-tuned models.
Overview
Evaluating the capabilities of LCLMs is crucial for their development, deployment and trust with end users. However, previous benchmarks often suffer from several limitations which can lead to incorrect assumptions when specifying them in real world use cases.
Some are restricted to relatively short context lengths while others lack rigorous evaluation methods, sometimes relying on metrics known to be unreliable for summarization, such as ROUGE. Many existing efforts focus on specific domains like question answering, in-context learning, summarization, or RAG in isolation which doesn’t accurately capture their capability.
A popular method for stress-testing LCLMs has been synthetic tasks like Needle-in-a-Haystack (NIAH). These tasks involve embedding a specific piece of information (the "needle") within a very long text filled with distracting information (the "haystack") and asking the model to retrieve it. While easy to set up and control for length and needle position, it has been unclear whether performance on these synthetic tasks accurately reflects performance on real-world applications.
The authors of HELMET identify several critical design flaws in existing benchmarks that contribute to this inconsistent evaluation landscape:
- Insufficient coverage of downstream tasks: Many benchmarks focus too narrowly on synthetic tasks or simple question answering, neglecting other important LCLM applications like summarization, in-context learning, or retrieval-augmented generation (RAG).
- Inadequate context lengths: Most natural language datasets used in benchmarks are too short to truly test the capabilities of frontier LCLMs, which can often handle 128K tokens or more.
- Unreliable metrics: Commonly used metrics like ROUGE (Recall-Oriented Understudy for Gisting Evaluation), which relies on n-gram overlap, have been shown to be noisy and correlate poorly with human judgment, especially for tasks with long outputs like summarization.
- Incompatibility with base models: Many LCLM advancements are focused on base models (models without instruction tuning). However, most existing benchmarks require instruction-tuned models, forcing developers of base models to rely on less informative synthetic tasks or perplexity scores.
These shortcomings lead to benchmarks that are either not applicable to cutting-edge LCLMs or provide unreliable signals.
Figure 1 from the paper illustrates this, showing how NIAH tasks are often saturated (most models perform perfectly), while other benchmarks like RULER and ∞Bench can show inconsistent or unexpected trends for state-of-the-art models.

Figure 1: Long-context benchmark results of frontier LCLMs (Llama-3.1 8B/70B, GPT-4o-mini, GPT-4o-08-06, and Gemini-1.5 Flash/Pro) at 128K input length. NIAH is saturated for almost all models; RULER (Hsieh et al., 2024) and ∞Bench (Zhang et al., 2024b) show unexpected trends for Llama-3.1 (Dubey et al., 2024). In contrast, HELMET demonstrates more consistent rankings of these frontier models.
The paper provides a comparative overview of HELMET against other existing benchmarks in Table 2.
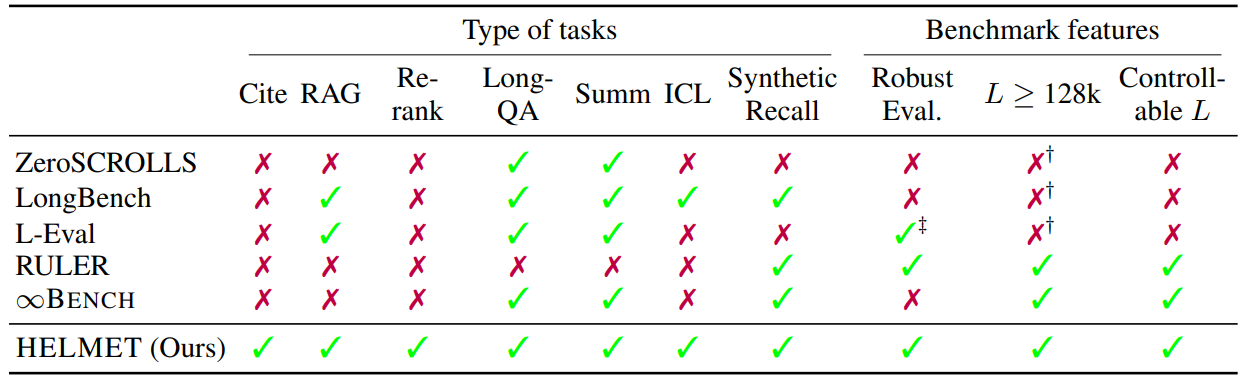
Table 2: *Comparison of long-context benchmarks: ZeroSCROLLS (Shaham et al., 2023), LongBench (Bai et al., 2024), L-Eval (An et al., 2024), RULER (Hsieh et al., 2024), ∞Bench (Zhang et al., 2024b), and our HELMET. L: input tokens. : All datasets have L < 128K except one dataset. †: L-Eval uses LLMs to compute reference-free, pairwise win-rates; we design reference-based model evaluation for specific tasks.
HELMET aims to provide a more comprehensive and reliable evaluation by encompassing seven diverse, application-centric categories:
- Retrieval-augmented generation (RAG): Factoid, trivia, long-tail entity, and multi-hop question answering (e.g., Natural Questions, TriviaQA, PopQA, HotpotQA). For these tasks, distractors that do not contain the answer are retrieved from Wikipedia passages, making the task more challenging than randomly sampling passages. Substring exact match (SubEM) is used as a metric.
- Generation with citations (Cite): Answering questions while providing correct attributions by citing relevant passages (leveraging datasets like ASQA and QAMPARI from ALCE). This tests the ability to utilize context and follow complex citation instructions.
- Passage re-ranking: Re-ranking passages based on a query (using datasets like MS MARCO).
- Many-shot in-context learning (ICL): Learning new tasks from many examples provided in the context, such as intent classification across various domains (e.g., TREC Coarse/Fine, NLU, BANKING77, CLINC150).
- Long-document QA: Answering questions based on very long documents like books or movie scripts (e.g., NarrativeQA, ∞Bench QA/MC). Evaluation for NarrativeQA uses a model-based metric assessing fluency and correctness.
- Summarization: Synthesizing information from extensive documents (e.g., Multi-LexSum for legal documents, ∞Bench Sum for novels). This category explicitly uses model-based evaluation instead of ROUGE.
- Synthetic recall: Includes various synthetic tasks like JSON KV retrieval and RULER variants beyond simple NIAH (e.g., RULER MK Needle, RULER MK UUID, RULER MV). SubEM is used for metrics.
HELMET supports controllable context lengths up to 128K tokens. It also employs a few-shot prompting technique to evaluate base models more robustly, recognizing that adding a few examples can significantly improve performance in realistic settings.
Why it’s Important
The finding that synthetic tasks like NIAH, while widely used, do not reliably predict downstream performance highlights the need for developers and researchers to move beyond these simple tests. Relying on NIAH scores can give a misleading impression of a model's real-world utility. HELMET provides a set of more application-relevant tasks to give a more holistic understanding.
Secondly, demonstrating the low correlation between different HELMET categories underscores that long-context ability is not a single, monolithic skill. A model might excel at retrieving a single fact but struggle to synthesize information for summarization or follow complex instructions for citation generation.
Comprehensive evaluation across diverse tasks is therefore essential to fully characterize an LCLM's capabilities. The finding that generating citations in ALCE (Automatic LLMs' Citation Evaluation) datasets requires distinct skills from simply answering questions with facts further illustrates this point.
Thirdly, the observed gap between open-source and closed models in tasks requiring full-context reasoning or complex instruction following points to specific areas where open-source models need further improvement. This insight is valuable for guiding future research and development efforts in the open-source community allowing open-source models to compete effectively.
Additionally, the adoption of model-based evaluation using powerful LLMs like GPT-4o as judges is a crucial methodological advancement. This approach is used for tasks like summarization and long-document QA to overcome the known limitations of traditional metrics like ROUGE, which may not align well with human judgments.
The research validates this approach through qualitative analysis and human evaluation, showing substantial to near-perfect agreement with human judgments for summarization metrics (Cohen's κ between 0.72 and 0.91). Model-based evaluation provides a more reliable signal of model quality that better reflects user experience.
Finally, the commitment to reproducibility through the public release of code and data ensures that other researchers can verify findings and build upon this work, contributing to more transparent and comparable evaluations in the field.
In essence, HELMET provides the LCLM community with a more nuanced, reliable, and comprehensive toolkit to measure and understand the capabilities of these powerful models, thereby fostering more targeted and effective advancements.
Summary of Results
The introduction of HELMET involved not only the creation of a new benchmark but also a comprehensive study evaluating 59 different LCLMs.
These models spanned various architectures (full-attention transformers, sliding-window attention, hybrid SSM models), scales, and training approaches, including both closed-source models like GPT-4 and Gemini, and open-source families such as Llama, Mistral, and Qwen.
Evaluations were conducted at input lengths of 8K, 16K, 32K, 64K, and 128K Llama-2 tokens, using greedy decoding for consistency.
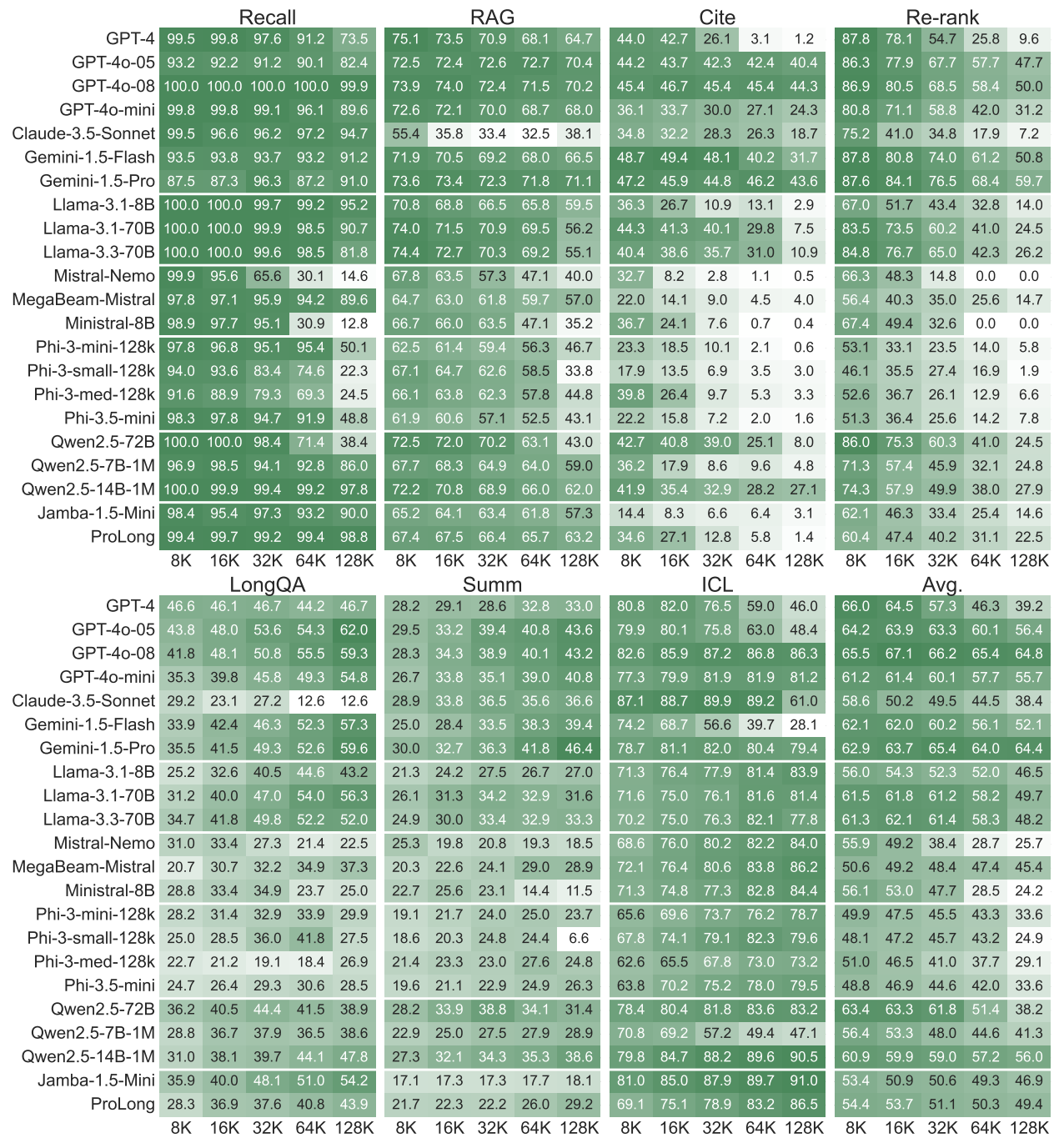
Figure 6 (data reference): Results of HELMET. All models are instruction-tuned and have a claimed context window of 128K tokens or more. This extensive table shows that closed-source models like GPT-4o-08 and Gemini-1.5-Pro generally lead, especially on complex tasks at 128K tokens. Open-source models, while strong in areas like ICL and synthetic recall, show a significant performance gap in tasks like generation with citations and re-ranking.
A key finding was the limited correlation between synthetic tasks and downstream performance. While many models achieved perfect 100% scores on simple NIAH variants, their performance on complex application tasks varied significantly.
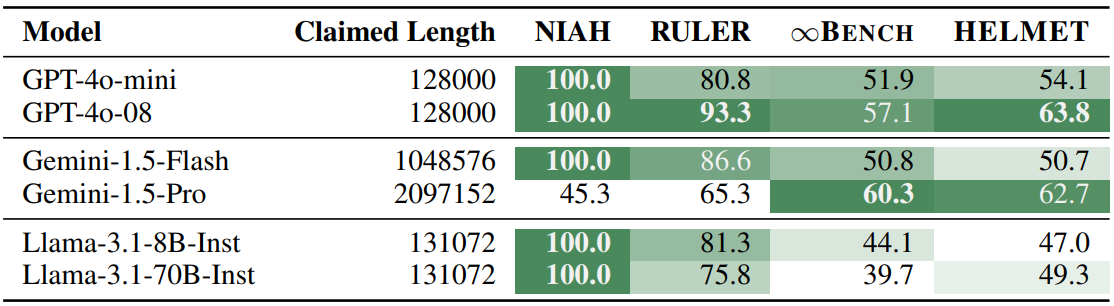
For example, Table 5 shows models like GPT-4o-mini, Gemini-1.5-Flash, Llama-3.1-8B-Inst, and Llama-3.1-70B-Inst all scoring 100% on NIAH at 128k tokens but having overall HELMET scores ranging from 47.0 to 54.1. In contrast, Gemini-1.5-Pro scored only 45.3% on NIAH but achieved a higher HELMET score of 62.7. This suggests that NIAH is not a reliable indicator of broader LCLM capability.
The analysis of correlations across datasets showed that synthetic tasks are generally less correlated with downstream tasks, although certain variants like JSON KV and specific RULER tasks (MK Needle/UUID, MV) showed higher correlation and were included in the benchmark's synthetic recall subset.
The study also revealed low correlations between datasets across different HELMET categories, except within the same category. For instance, the ALCE citation generation tasks showed low correlation with other categories, indicating that the ability to generate correct citations is distinct from general QA or retrieval. This supports the argument for evaluating models across a diverse set of tasks to get a complete picture of their capabilities.
While many LCLMs achieved perfect NIAH scores, the study found a significant performance gap between closed and open-source models on tasks requiring complex reasoning or instruction following. This gap became more pronounced at longer context lengths.
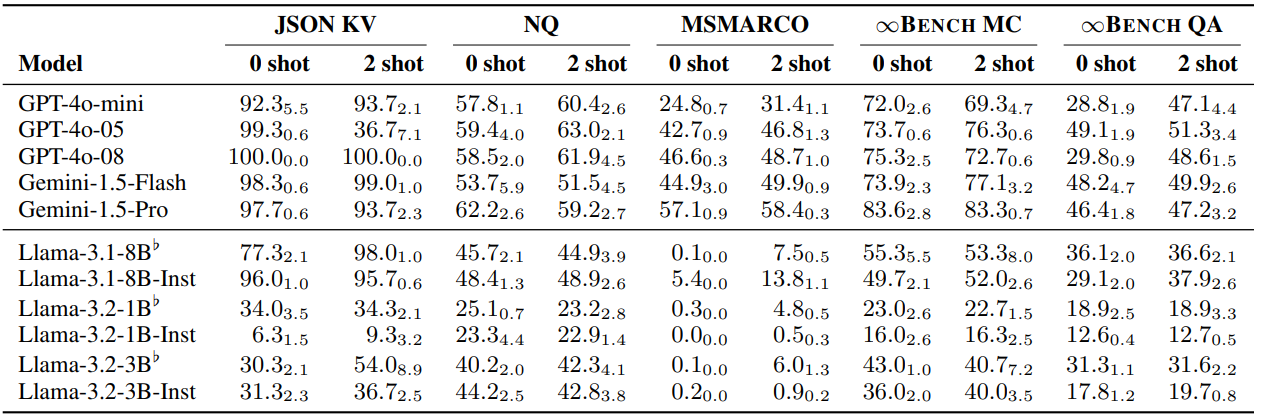
Table 8: We evaluate the performance of models on a subset of HELMET tasks with 0-shot and 2-shot demonstrations at 128k input length to understand the impact of ICL on model performance, averaged across three random seeds. The standard deviation across three runs are shown in the subscript. We observe that the performance is generally higher for 2-shot demonstrations compared to 0-shot demonstrations. Crucially, the 2-shot examples enable base models to achieve higher results that reflect the model’s long-context capabilities in realistic settings, such as for MSMARCO and JSON KV. ♭denotes base models.
The research highlights the value of few-shot prompting for evaluating base models. As shown in Table 8, providing just two examples often leads to substantially higher performance compared to zero-shot evaluation across various tasks like JSON KV, NQ, MSMARCO, and ∞BENCH QA/MC. This is particularly important for accurately reflecting the potential of base models in realistic settings.
The researchers also detail the model-based evaluation methodology used for summarization and long-document QA, which leverages GPT-4o as a judge. For summarization recall, GPT-4o is instructed to decompose a gold summary into key points and then assess how many of these points are present in the model's generated summary.
For summarization precision, the model checks if each sentence in the generated summary is supported by the expert summary. Fluency is also assessed with a simple 0 or 1 score. The final summarization score is the product of the F1 score (derived from recall and precision) and the fluency score.
For long-document QA (NarrativeQA), GPT-4o judges the model's output for fluency and correctness using specific rubrics, and the final score is the product of the two scores. The rubrics provide detailed scoring guidelines for correctness (0 to 3) and fluency (0 or 1).
Human evaluation confirmed substantial to near-perfect agreement with the GPT-4o judgments on summarization tasks.
The research also provides qualitative examples of model outputs, illustrating challenges such as models failing to follow instructions (e.g., Claude not outputting citation markers in ALCE ASQA or failing to generate rankings in MS MARCO and labels in BANKING77).
Overall, the results from HELMET provide a granular, multi-dimensional view of LCLM performance, highlighting the inadequacy of relying on narrow or synthetic evaluations and underscoring the distinct nature of various long-context capabilities.
Conclusion
The research on HELMET provides valuable insights into the current state and effective evaluation of long-context language models. By moving beyond synthetic tasks and incorporating a diverse suite of application-centric evaluations, HELMET offers a more reliable and comprehensive picture of LCLM capabilities.
The findings demonstrate that success on simple tests like NIAH does not guarantee performance on complex downstream tasks and highlight the need to evaluate distinct skills like information synthesis, instruction following, and fact retrieval independently. The model-based evaluation methodology addresses the shortcomings of traditional metrics, offering a more human-aligned assessment of quality.
The benchmark also reveals a performance gap between closed and open-source models in challenging areas, guiding future research. The recommendation to use RAG tasks for faster development provides practical guidance for the field. Ultimately, HELMET advocates for a holistic evaluation approach across diverse tasks to form a complete understanding of long-context language models. The public release of code and data ensures reproducibility and facilitates further research in this rapidly evolving area.
Interested in another Long Context Benchmark research? Checkout LONGPROC research review!


HELMET: A Comprehensive Benchmark for Evaluating Long-Context Language Models
HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly