If you have been following along with Ai developments you will notice that there is a lot of hype around the "Context Window" that a model can handle. Whether it's proprietary ChatGT or opensource LLaMa, they are promoting the ability for the model to generate reasoning and references to very long text and visual inputs.
In reality this hype doesn't live up to the marketing expectations according to this recent benchmarking by the Princeton Language and Intelligence group.
The LONGPROC benchmark evaluated 17 Long Context Language Models (LCLM), revealing that all struggle with coherent long procedural generation, particularly at the 8K token level, despite larger models showing some resilience. This highlights significant limitations and the need for improvements in LCLMs.
The new benchmark hopes to serve as a standard for comparing the performance of long context window LLMs by comparing the results of 6 activities that are deemed to require understanding and reference of large context windows (a lot of information).
Key Takeaways
- LONGPROC serves as a reliable testbed, exposing limitations and indicating substantial room for future research in long-context modeling.
- Recent advancements have increased the context window of pretrained language models from hundreds to millions of tokens.
- Existing benchmarks primarily focus on tasks requiring short outputs from long inputs, limiting insights into practical applications.
- The proposed LONGPROC benchmark includes six tasks that require long procedural generation, integrating dispersed information and multi-step reasoning.
- The tasks are HTML to TSV, Pseudocode to Code, Path Traversal, Theory-of-Mind Tracking, Countdown, and Travel Planning.
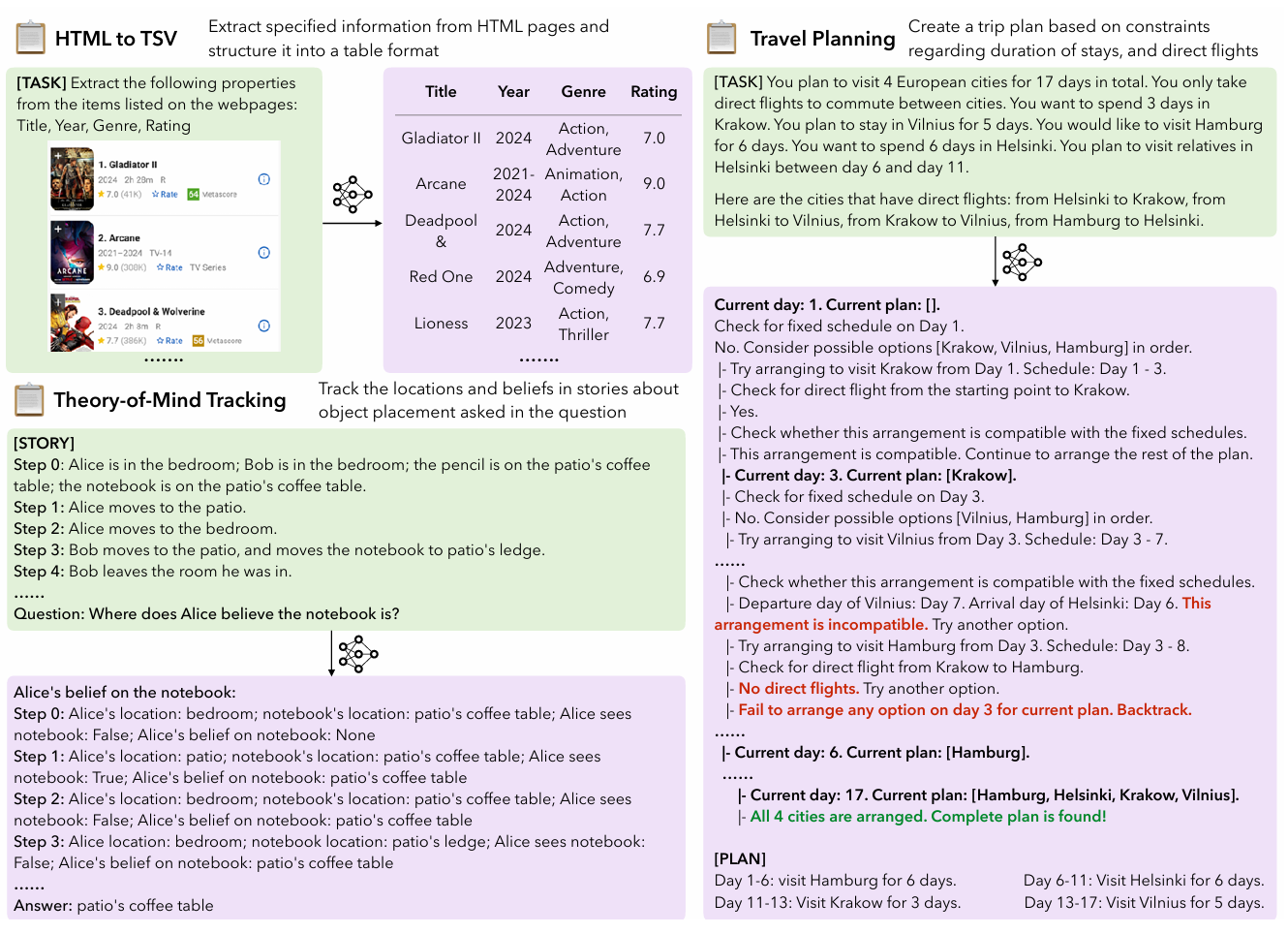
Fig 1. (Ref) Three (out of six) representative tasks in LONGPROC: HTML to TSV, Theory-of-Mind Tracking, Travel Planning. Each task requires LCLMs to follow a given procedure and generate outputs in a specified format detailed by instructions. This leads to natural longform outputs that can be evaluated reliably with rule-based metrics. Refer to appendix C for examples of all six tasks
- Each task presents unique challenges, such as information extraction, deductive reasoning, and search execution.
- LONGPROC features three difficulty levels based on output lengths: 500, 2K, and 8K tokens, differentiating model capabilities.
- Evaluation of 17 long-context language models revealed that proprietary models struggle with 8K-token tasks despite having 128K context windows.
- Open-weight models performed even worse, with difficulties on 500-token tasks, highlighting significant performance gaps.
- Tasks like Theory-of-Mind Tracking showed greater performance decline compared to simpler tasks like HTML to TSV extraction.
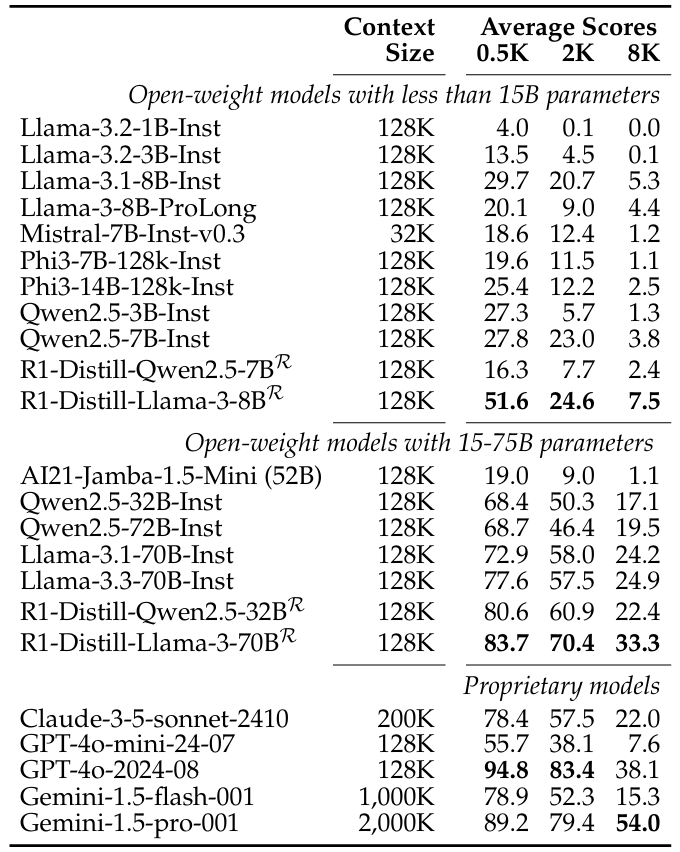
Table 3: Average performance across tasks of different LCLMs on LONGPROC at three difficulty levels (0.5K, 2K, 8K). All models show performance degradation with increased output length. Even frontier models struggle with 8K-token procedural generation tasks.
- Human evaluators solved 100% of Countdown problems and 90% of Travel Planning problems, while GPT-4o solved only 70% and 30%.
- In the ToM Tracking task, 95% of errors were due to incorrect long-range inferences about location changes.
- GPT-4o struggled with search-based tasks, with 50% of errors involving hallucinated flights and 40% failing to explore options.
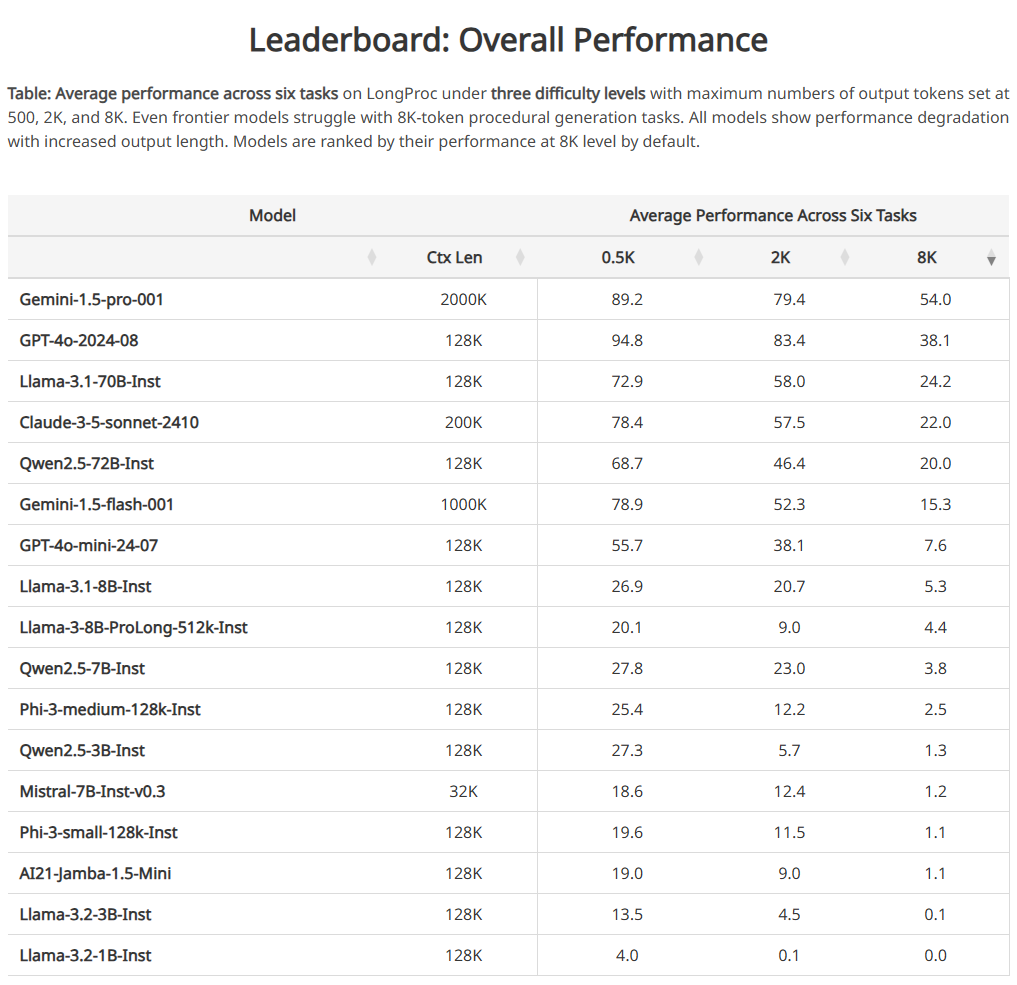
The new LONGPROC benchmark may serve as an industry standard in evaluating LLMs ability to reason and reference long context content helping to improve model accuracy and Chain of thought reasoning. The current benchmarks illustrate the need to address the accuracy of long text references in both private and public models

Princeton Group Proposes LONGPROC: A Long Context Benchmark
LongProc: Benchmarking Long-Context Language Models on LongProcedural Generation