The rapid advancement of Large Language Models (LLMs) has ignited considerable interest in their potential applications within healthcare, particularly given their impressive performance on medical knowledge benchmarks.
However, the ability of these models to achieve near-perfect scores on standardized medical licensing exams does not fully capture the intricate and diverse demands of real-world clinical practice.
Traditional evaluations often fall short by relying on synthetic data, lacking real-world electronic health record (EHR) data, and focusing on a narrow range of tasks, largely ignoring critical aspects of hospital operations, documentation, and patient communication.
This significant gap between benchmark performance and readiness for real-world deployment underscores a crucial need for more robust evaluation methods.
To address this challenge, researchers introduced MedHELM (Holistic Evaluation of Large Language Models for Medical Tasks), an extensible evaluation framework designed to rigorously assess LLM performance across the complexity of medical tasks.
This framework represents a pivotal step towards ensuring that AI models can truly support healthcare professionals in their day-to-day activities and contribute safely and effectively to clinical settings.
Explore the Results and Leaderboard
Key Takeaways
- Researchers introduce a clinician-validated, comprehensive, multi-layered classification system comprising five categories, 22 subcategories, and 121 distinct medical tasks, developed in collaboration with 29 clinicians, ensuring its relevance and accuracy to real-world practice.
- The taxonomy organizes a collection of 35 benchmarks, including both existing and newly formulated datasets, providing significant coverage of all defined categories and subcategories.
- They evaluated nine frontier LLMs, employing advanced evaluation methods and a detailed cost-performance analysis to offer practical deployment insights.
- Significant performance differences were observed among LLMs, with advanced reasoning models like DeepSeek R1 (66% win-rate) and o3-mini (64% win-rate) demonstrating superior overall performance.
- While top reasoning models excel, Claude 3.5 Sonnet achieved comparable performance at an estimated 40% lower computational cost, highlighting important trade-offs for practical deployment in resource-constrained environments.
- LLMs generally performed strongest in Clinical Note Generation (0.74-0.85) and Patient Communication & Education (0.76-0.89), moderately in Medical Research Assistance and Clinical Decision Support, and lowest in Administration & Workflow (0.53-0.63) categories.
- The introduction of a LLM-jury evaluation method for open-ended tasks achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and traditional automated metrics like ROUGE-L and BERTScore-F1.
Overview
The widespread interest in deploying Large Language Models (LLMs) in healthcare stems from their impressive ability to score highly on medical knowledge benchmarks, such as achieving approximately 99% accuracy on standardized exams like MedQA.
This has led to the exploration of their potential in supporting clinical decision-making, optimizing workflows, and enhancing patient communication.
However, the existing evaluation landscape for LLMs in medicine possesses significant limitations for a challenging field like medicine:
- Mismatch with Real-World Settings: Current benchmarks often use synthetic vignettes or narrowly focused exam questions, failing to capture the complexity of real diagnostic processes, such as extracting relevant details from ambiguous patient records.
- Limited Real-World Data: A mere 5% of LLM evaluations incorporate real-world Electronic Health Record (EHR) data. EHRs, which are digital versions of a patient's medical chart, contain unique challenges like ambiguities, inconsistencies, and domain-specific shorthand that synthetic data cannot replicate.
- Lack of Task Diversity: About 64% of LLM evaluations in healthcare focus almost exclusively on medical licensing exams and diagnostic tasks, neglecting other essential hospital operations. These include administrative tasks (e.g., generating prior authorization letters), clinical documentation (e.g., writing progress notes), and patient communication (e.g., asynchronous messaging via patient portals).
To overcome these shortcomings, MedHELM was developed as an extensible evaluation framework. Inspired by the cross-domain HELM project, MedHELM evaluates nine LLMs across 35 distinct benchmarks that span 22 subcategories of medical tasks, focusing on the day-to-day activities of clinicians rather than just exam performance. The evaluation framework is depicted in Figure 1 below, illustrating its three core stages:
Figure 1: The MedHELM Evaluation Framework
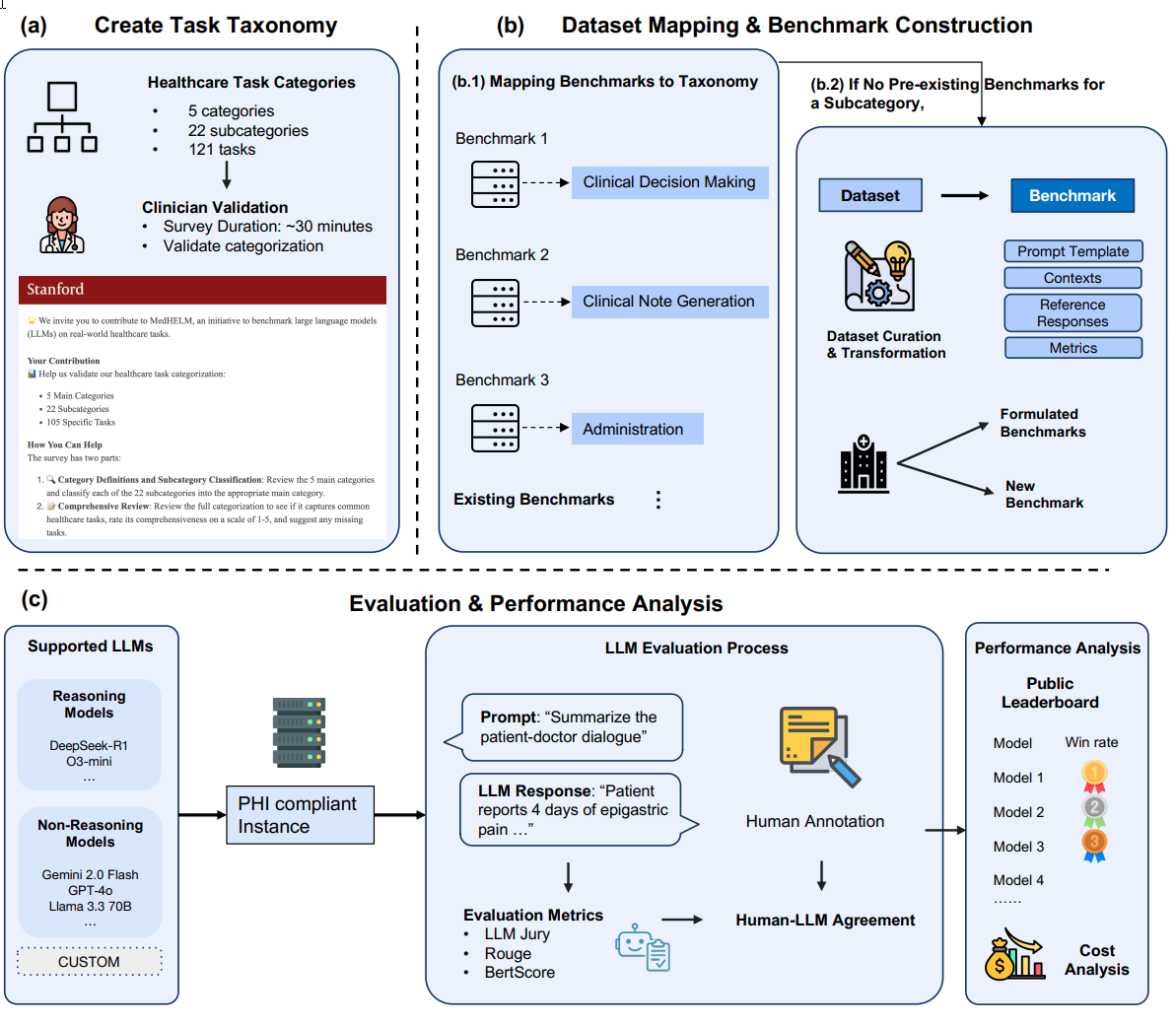
Fig. 1 This figure illustrates: (a) a clinician-validated taxonomy organizing 121 medical tasks into five categories and 22 subcategories; (b) a suite of benchmarks that map existing benchmarks to this taxonomy and introduces new benchmarks for complete coverage; and (c) an evaluation comparing reasoning and non-reasoning LLMs, with model rankings, LLM jury based evaluation of open-ended benchmarks, and cost-performance analysis.
The MedHELM framework's primary contributions are:
- Clinician-Validated Taxonomy: A hierarchical classification of 121 medical tasks, organized into five categories and 22 subcategories, developed with input from 29 clinicians. This ensures the taxonomy accurately reflects how healthcare professionals conceptualize their daily work and contributes to better classification of important benchmark metrics.
- Benchmark Suite: A collection of 35 benchmarks, including 17 existing, five re-formulated from existing datasets, and 13 newly formulated datasets. This suite contributes to more complete coverage of all areas within the proposed taxonomy.
- Comparative Evaluation and Cost-Performance Analysis: A systematic comparison of LLM performance using improved evaluation methods, including an LLM-jury for open-ended responses, coupled with an analysis of computational cost.
The framework aims to benefit key stakeholders: healthcare systems evaluating LLMs for specific tasks, AI developers identifying performance gaps, and researchers needing reproducible methods for measuring LLM capabilities in medicine. To foster ongoing collaboration, MedHELM provides an openly accessible leaderboard and shares its codebase.
Why it’s Important
MedHELM represents a significant step forward in evaluating Large Language Models for professional healthcare applications. Its importance lies in bridging the critical gap between theoretical knowledge assessment and practical, real-world utility.
First, by moving beyond traditional, narrowly scoped medical licensing exams, MedHELM offers an evaluation framework that attempts to mirror the complexity and diversity of actual clinical practice.
This shift is crucial because high scores on standardized tests do not guarantee effective performance in the nuanced, data-rich environment of a hospital or clinic. The high success rate of LLMs on these tests further suggests that their training data overlaps with the exam questions leading to overfitting.
The proposed framework incorporates real-world Electronic Health Record (EHR) data and provides a more authentic stress test for LLMs thanks to its ambiguities and domain-specific shorthand.
Secondly, perhaps the most important contribution is MedHELM’s clinician-validated taxonomy which ensures that the evaluated tasks are directly relevant to the daily activities of healthcare professionals.
This collaborative design, involving 29 clinicians across 14 specialties, attempts to guide the framework to assess skills genuinely valued and performed by medical practitioners. This grounded approach provides a common language and standardized evaluation methods, which are vital for reproducible and meaningful assessment of AI capabilities in medicine.
Thirdly, the framework’s inclusion of cost-performance analysis is a practical necessity for healthcare systems. In resource-constrained settings, understanding the trade-off between model performance and computational cost is paramount for making informed deployment decisions. For example, identifying models like Claude 3.5 Sonnet that offer comparable performance to top models at significantly lower costs is invaluable for real-world implementation.
While the innovative LLM-jury evaluation method for open-ended text generation tasks addresses a critical bottleneck: the scarcity and expense of clinician time for manual evaluations. By demonstrating that an ensemble of LLMs can assess outputs with agreement levels surpassing even average clinician-clinician agreement, MedHELM potentially provides a scalable and valid alternative, accelerating the evaluation cycle for medical AI development.
Finally, the identification of performance gaps, particularly the lower scores in Administration & Workflow tasks, highlights areas where LLMs may need further development or where caution is required for deployment.
By providing an open-source framework, leaderboard, and codebase, MedHELM fosters a collaborative environment for continuous improvement and reproducible measurement of LLM capabilities on medical professional tasks.
Summary of Results
The MedHELM research yielded comprehensive results across its three core contributions: the clinician-validated taxonomy, the benchmark suite, and the systematic evaluation of LLMs with cost-performance analysis.
1. Clinician Validation of the Taxonomy
The initial taxonomy, comprising five categories, 21 subcategories, and 98 tasks, underwent a structured review by 29 practicing clinicians from 14 medical specialties. This validation process confirmed the structure's clarity and relevance:
- Clinicians achieved a 96.7% agreement rate when assigning subcategories to their appropriate top-level categories, indicating the clear and discrete nature of the classification.
- The proposed tasks were rated highly for comprehensiveness, with a mean score of 4.21 out of 5.
- Based on clinician feedback, the taxonomy was refined and expanded to its final form: five categories, 22 subcategories, and 121 tasks.
Figure 2 provides an overview of this final taxonomy, highlighting its structure:
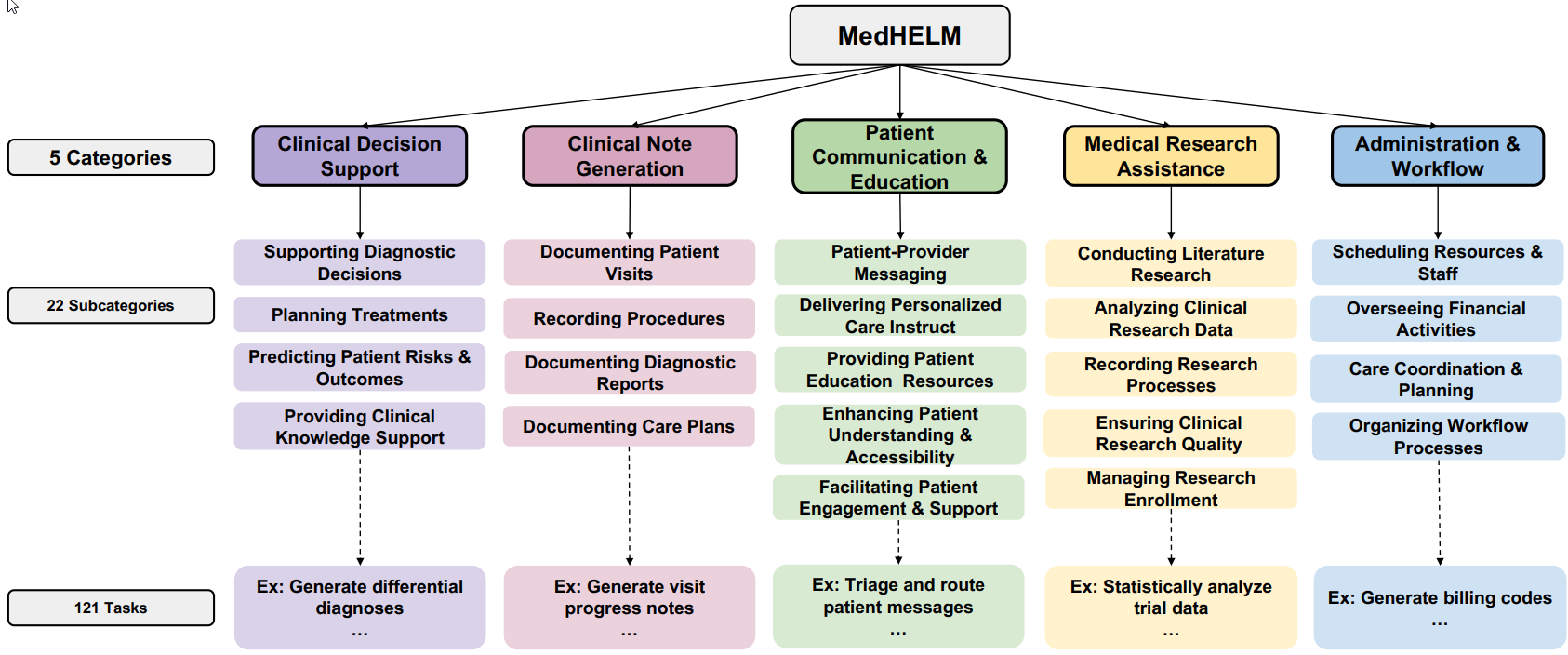
Fig. 2 Overview of the final taxonomy comprising five main categories and 22 subcategories.
2. Overview of the Benchmark Suite
The MedHELM benchmark suite consists of 35 benchmarks, providing full coverage of all 22 subcategories and five categories within the taxonomy. The datasets were curated using a three-tiered strategy:
- 17 existing benchmarks from public or gated sources (e.g., MedQA, MIMIC-IV Billing Code, ACI-Bench).
- 5 re-formulated benchmarks derived from previously unevaluated medical datasets.
- 13 new benchmarks, 12 of which are based on real-world Electronic Health Record (EHR)
data, specifically curated to address under-represented areas like Administration & Workflow.
The suite includes 13 open-ended benchmarks (requiring free-text generation) and 22 closed-ended benchmarks (with predefined answer choices). Access levels vary, with 14 public, seven gated (requiring approval), and 14 private datasets.
The Clinical Decision Support category is the most extensively represented with ten benchmarks, followed by Patient Communication (eight), Clinical Note Generation (six), Medical Research Assistance (six), and Administration & Workflow (five). While comprehensive, the distribution of benchmarks across subcategories is uneven, with 15 subcategories having only a single benchmark.
Each benchmark was transformed from its raw dataset by defining three key components for every item:
- Context: The raw input provided to the LLM (e.g., a clinical note or patient message).
- Prompt: A standardized instruction template to elicit consistent, task-appropriate responses (e.g., "Summarize the patient-doctor dialogue").
- Evaluation Metric: A pre-specified scoring method matched to the task type, such as exact-match accuracy for closed-ended questions, Micro-F1 for multi-label classification, or an LLM-jury ensemble for open-ended text generation.
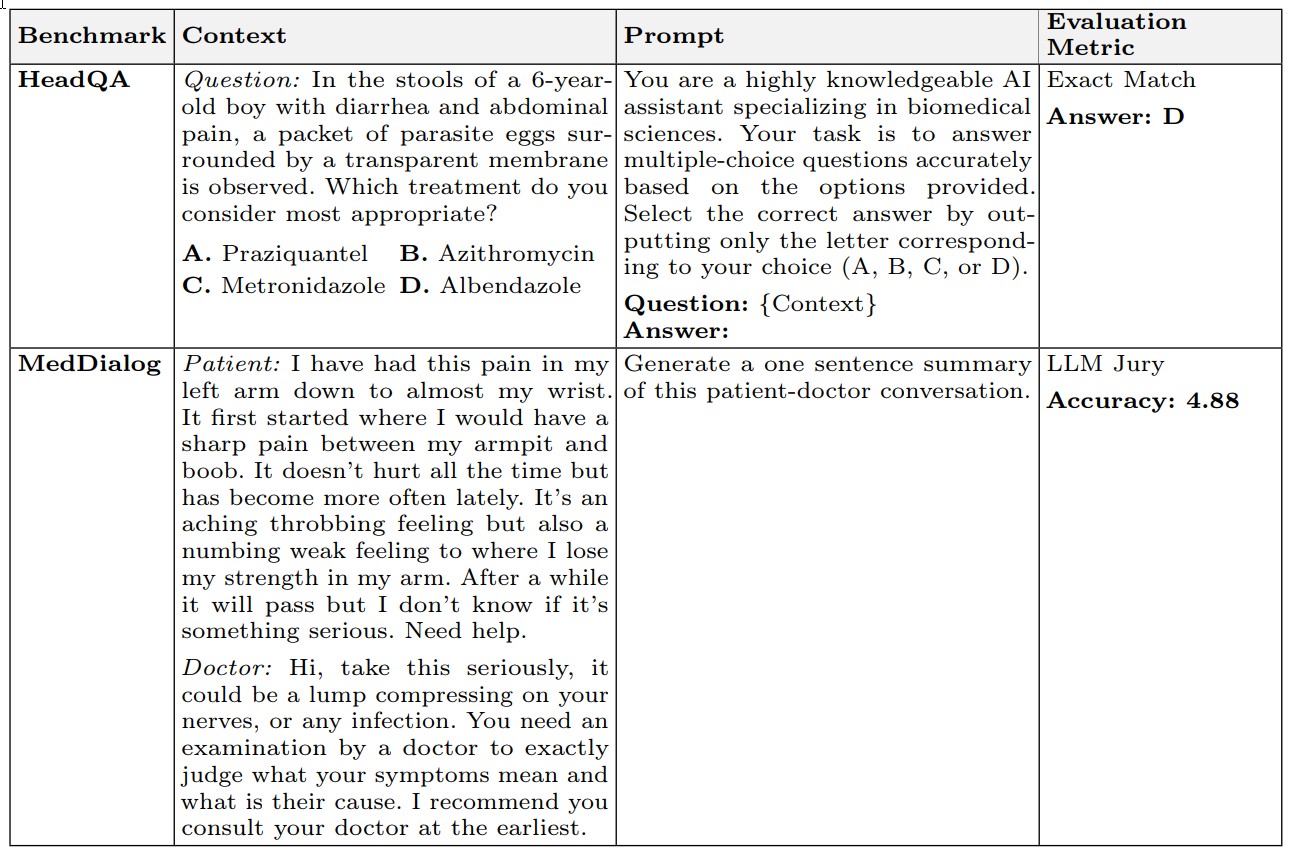
Table 4 illustrates how these components are applied for specific benchmarks like HeadQA (closed-ended) and MedDialog (open-ended), detailing the context, prompt, and evaluation metric. This structured approach ensures consistency and clarity in the evaluation process.
3. Model Evaluation & Cost-Performance Analysis
Nine state-of-the-art LLMs were evaluated, including reasoning models (DeepSeek R1, o3-mini) and non-reasoning models (Gemini 2.0 Flash, GPT-4o, Llama 3.3 Instruct).
Overall Performance (Table 1) Performance was assessed using pairwise win-rate (proportion of head-to-head comparisons won) and macro-average scores across all 35 benchmarks.
Table 1: Comparison of Performance of Frontier Models Across 35 MedHELM Benchmarks
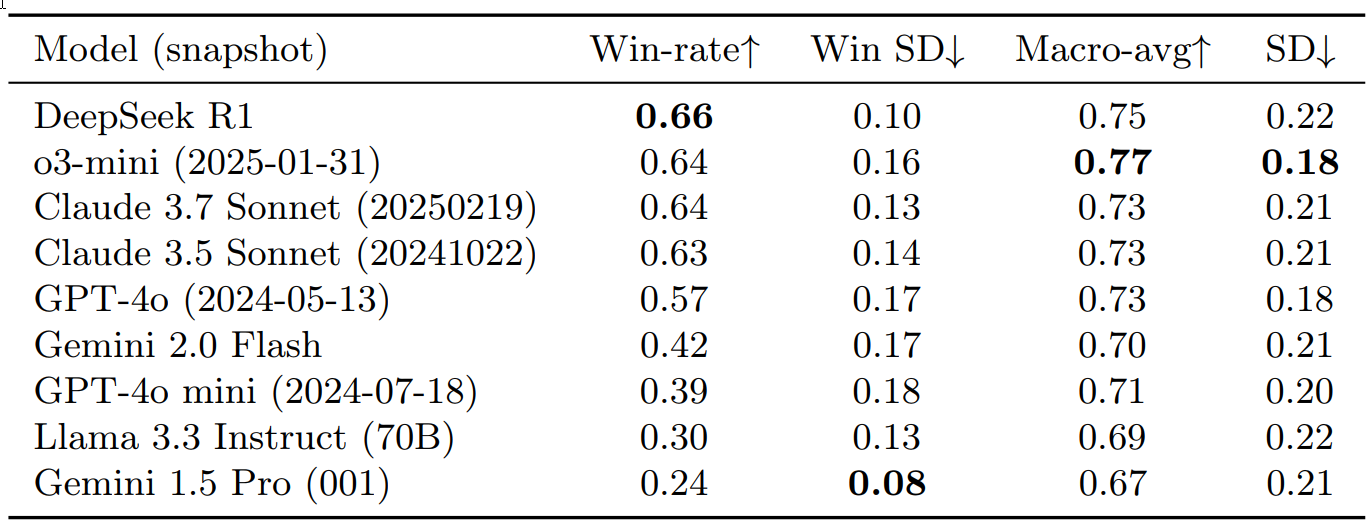
Table 1 provides a comparison of the performance of frontier models across 35 MedHELM benchmarks, sorted by descending win-rate. Win-rate indicates the proportion of pairwise comparisons where a model performed better. Win SD (Standard Deviation) shows consistency (lower is better). Macro-avg is the average performance score, and SD indicates performance variation across benchmarks.
Key findings from Table 1:
- DeepSeek R1 showed the best win-rate (0.66), while o3-mini achieved the highest macro-average (0.77), especially excelling in clinical decision support.
- The Claude Sonnet models (3.5 and 3.7) demonstrated strong performance with win-rates of 0.63-0.64 and a macro-average of 0.73.
- Other models, including GPT-4o, Gemini 2.0 Flash, GPT-4o mini, and Llama 3.3 Instruct, showed varied, generally lower performance.
- Gemini 1.5 Pro had the lowest win-rate but exhibited the most consistent competitive performance (lowest win standard deviation).
Performance by Benchmark (Figure 3) The heatmap of normalized scores illustrates performance across individual benchmarks: Figure 3: Heatmap of Normalized Scores Across 35 Benchmarks
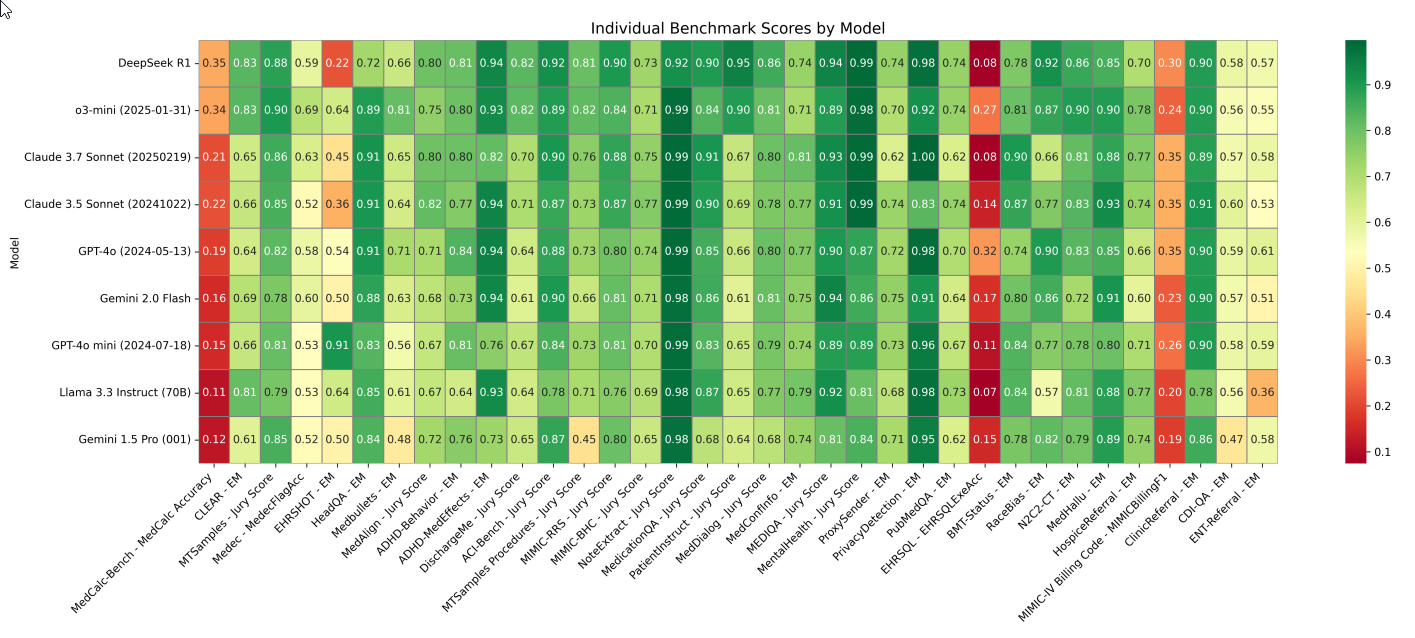
Fig. 3 Heatmap of normalized scores (0–1) for each model (rows) across 35 benchmarks (columns). Scores are normalized for visualization purposes; the official leaderboard reports the original (unnormal-ized) scores. Dark green indicates high performance; dark red indicates low performance. The statistical significance of model differences varies by benchmark, with an analysis of minimum detectable effects shown in Appendix E. Metrics include EM as exact match, Jury Score as the average normalized score from three frontier LLMs, MedCalc Accuracy as exact match or thresholded match depending on question type, MedFlagAcc as binary accuracy for detecting presence of errors, EHRSQLExeAcc as execution accuracy of generated code against a target output, and MIMICBillingF1 as the F1 score on ICD-10 codes extracted from a medical note.
Performance by Category (Figure 4) Analysis by the five top-level categories revealed distinct performance patterns:
Figure 4: Mean Normalized Scores Across the Five Categories
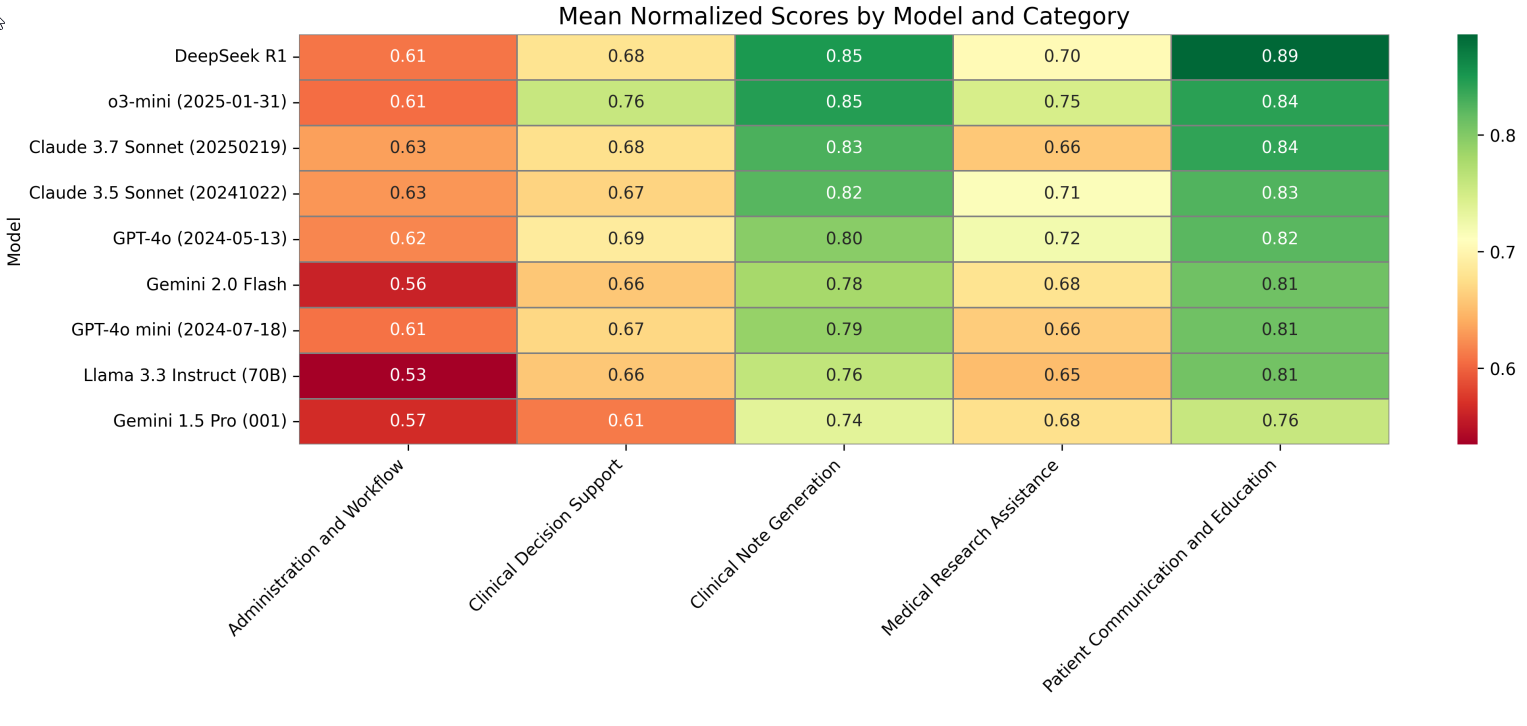
Fig. 4 Mean normalized scores (0-1 scale) across the five categories for all evaluated models. Darker green represents higher scores. Models are ordered by mean win rate from top (highest) to bottom (lowest), while categories are arranged left to right.
4. Evaluation of Open-Ended Benchmarks (LLM-Jury)
For the 13 benchmarks requiring free-text generation, an LLM-jury approach was implemented, using three different LLMs (GPT-4o, Claude 3.7 Sonnet, LLaMA 3.3 70B) to evaluate responses on a 1-5 Likert scale across three axes: accuracy, completeness, and clarity. To validate this method, clinician ratings were collected on subsets of outputs from two benchmarks (ACI-Bench and MEDIQA-QA).
Table 2: Agreement of LLM-Jury and Automated Metrics with Clinician Ratings

Table 2 shows the Intraclass Correlation Coefficient (ICC) values for agreement with clinician ratings. Higher ICC indicates better agreement. The last column gives the average clinician–clinician agreement.
Key findings from Table 2:
- The LLM-jury achieved an overall ICC of 0.47, which surpassed the average clinician-clinician agreement (ICC = 0.43).
- It also outperformed automated baselines like ROUGE-L (0.36) and BERTScore-F (0.44). This demonstrates that the LLM-jury can reliably mirror clinician judgment, providing a valid and scalable evaluation method.
Cost-Performance Analysis (Figure 5 & Table 3) The cost of evaluating each model was estimated based on publicly listed pricing, considering total input tokens and maximum output tokens consumed during benchmark runs and LLM-jury evaluation. Token usage refers to the basic units of text processed by an LLM.
Figure 5: Scatter Plot of Mean Win-Rate Versus Estimated Computational Cost
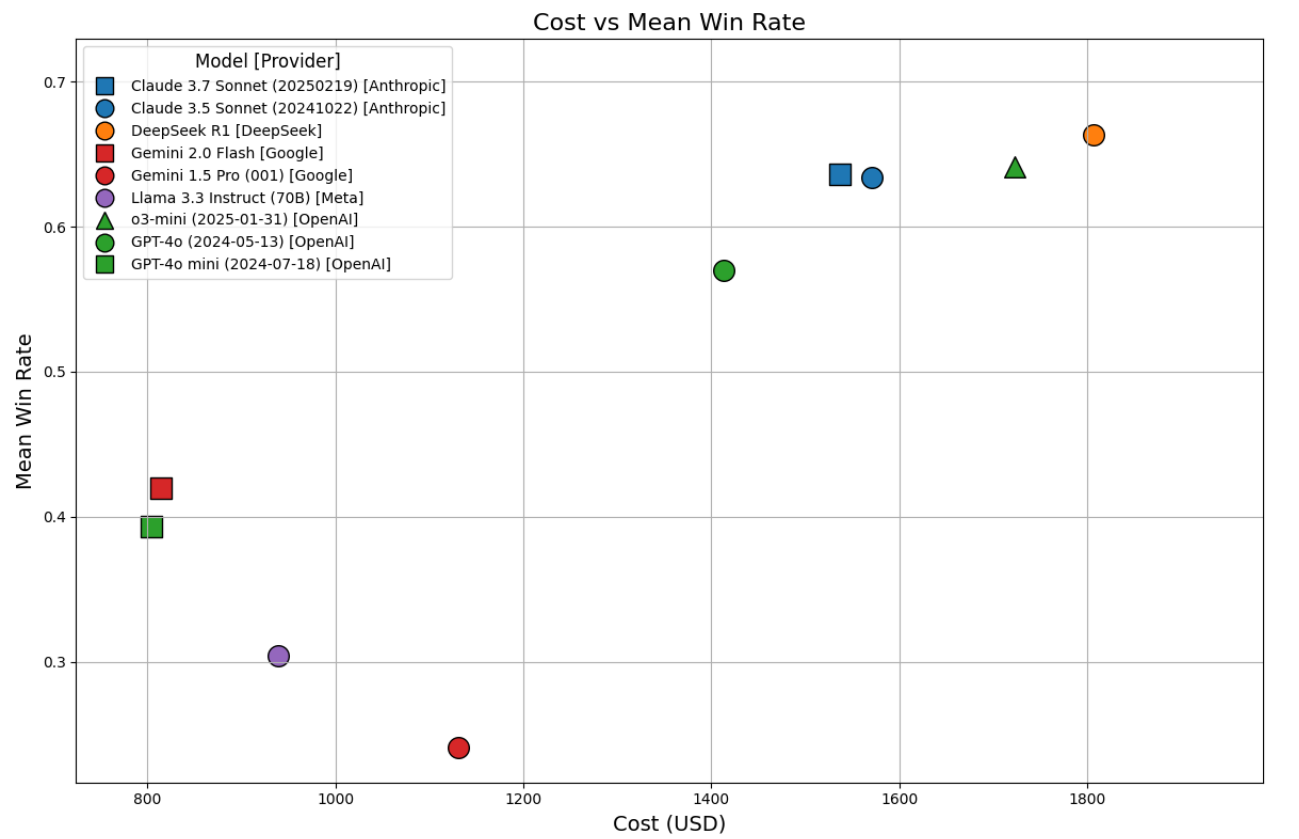
Fig. 5 Scatter plot of mean win-rate (y-axis) versus estimated computational cost (x-axis) for each of the nine models across 35 benchmarks. Each point represents a model, with the position indicating the relationship between performance (y-axis) and total cost of evaluation, including benchmark runs and evaluation by LLM-jury (x-axis). Costs represent upper-bound estimates based on maximum output token usage.
Table 3: Comparison of LLMs by Architecture, Access Type, and Token Usage Metrics Across MedHELM

Table 3 presents a comparison of LLMs based on their architecture, access type, and token usage metrics in MedHELM. It details benchmark and jury token usage, along with their estimated costs, providing an upper-bound estimate for total evaluation expenses.
Key findings from Table 3 and Figure 5:
- Non-reasoning models like GPT-4o mini ($805) and Gemini 2.0 Flash ($815) incurred the lowest costs, but also achieved lower win-rates (0.39 and 0.42, respectively).
- Reasoning models, DeepSeek R1 ($1,806) and o3-mini ($1,722), incurred higher costs but delivered superior win-rates (0.66 and 0.64).
- Claude 3.5 Sonnet ($1,571) and Claude 3.7 Sonnet ($1,537) offered a favorable cost-performance balance, achieving win-rates around 0.63 at notably reduced costs compared to the top reasoning models. This suggests they could be optimal choices in resource-constrained healthcare settings.
Conclusion
MedHELM represents a significant advancement in the evaluation of Large Language Models for medical applications, shifting the focus from idealized exam performance to the complexities of real-world clinical tasks.
By introducing a clinician-validated taxonomy, a comprehensive benchmark suite that incorporates real-world data, and sophisticated evaluation methods like the LLM-jury, the framework offers a more realistic and nuanced assessment of LLM capabilities.
The research clearly demonstrates that while advanced reasoning models like DeepSeek R1 and o3-mini deliver superior overall performance, models such as Claude 3.5 Sonnet provide a compelling balance of high performance at a lower computational cost, which is a crucial consideration for practical deployment in healthcare.
The consistent strengths of LLMs in Clinical Note Generation and Patient Communication & Education tasks highlight their immediate potential in areas leveraging natural language processing. Conversely, their relatively weaker performance in Administration & Workflow tasks signals critical areas for future development and necessitates careful consideration before widespread deployment in such operations.
The validation of the LLM-jury approach as a reliable alternative to extensive clinician time for open-ended evaluations is a pivotal insight, offering a scalable solution to a significant bottleneck in AI development.
By providing an open-source framework, including a public leaderboard and codebase, MedHELM fosters a collaborative environment for continuous improvement and reproducible evaluation as medical AI continues to evolve. This comprehensive approach moves beyond mere summary, offering detailed insights into LLM performance across diverse medical tasks, thereby laying a robust foundation for the responsible and effective integration of AI into healthcare.


Evaluating LLMs for Real-World Healthcare: The MedHELM Framework
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks