Developing highly capable Large Language Models (LLMs) typically demands immense computational resources. This poses a significant barrier to entry and innovation for many researchers and organizations.
Model merging has emerged as a promising, cost-effective alternative, allowing the creation of new models by combining existing ones without requiring extensive additional training.
However, the current practice of model merging often relies heavily on human intuition, domain knowledge, and a degree of trial-and-error, which limits its full potential.
This research introduces a novel paradigm that leverages evolutionary algorithms to automatically discover effective strategies for combining diverse open-source models, aiming to harness their collective intelligence and create models with new, enhanced capabilities more systematically and efficiently.
Key Takeaways
- Automated Model Composition
Researchers propose and demonstrate a general evolutionary method to automatically find effective combinations of selected models, enabling the creation of new merged models with desired capabilities specified by the user.- Dual-Space Optimization
The evolutionary approach operates in two distinct, orthogonal configuration spaces: the parameter space (PS), focusing on optimizing the weights of the combined models, and the data flow space (DFS), optimizing the sequence in which layers from different models are used during inference.- Cross-Domain Merging Success
The method successfully demonstrates the ability to merge models from vastly different domains, such as combining a Japanese LLM with English math LLMs or an English Vision-Language Model (VLM) to create models with novel combined abilities.- State-of-the-Art Performance
The automatically generated models, including a Japanese LLM with math reasoning capabilities (EvoLLM-JP) and a culturally aware Japanese VLM (EvoVLM-JP), achieved state-of-the-art performance on various established benchmarks, even surpassing larger or previously leading models in some cases.- High Efficiency and Generalizability
The resulting 7B parameter LLM demonstrated surprising generalizability, outperforming some previous 70B parameter Japanese LLMs on benchmarks it was not explicitly optimized for. The merging process itself is highlighted as being efficient.- Open Contribution
The developed state-of-the-art Japanese models, EvoLLM-JP and EvoVLM-JP, are being open-sourced to the community to facilitate further research and development. An Apache 2.0-licensed version of the math LLM (EvoLLM-JP-A) was also created and released.- Democratization of AI
The evolutionary model merging approach offers a path towards democratizing access to advanced AI capabilities by enabling the creation of capable models at lower costs and potentially reducing the environmental footprint of AI development.
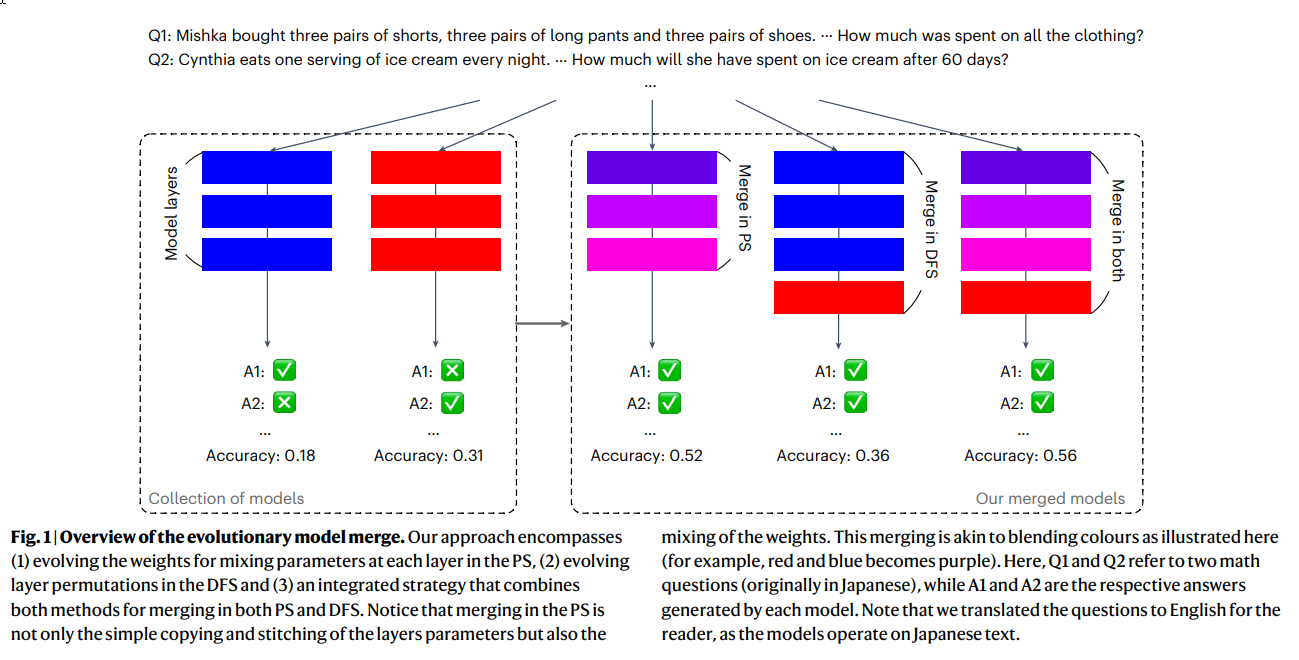
Overview
The development of highly capable Large Language Models (LLMs) has traditionally demanded significant computational resources. While model merging, combining existing models, has emerged as a cost-effective alternative, it has largely relied on human intuition and domain-specific knowledge, thereby limiting its full potential.
Instead of training a new model from scratch or extensively fine-tuning a single model, merging allows researchers to leverage the strengths inherent in multiple source models. This accessibility has contributed to the dominance of merged models on platforms like the Open LLM Leaderboard.
Despite its potential, model merging often relies heavily on the model maker's intuition and expertise in selecting models and devising "recipes" for combining them effectively for specific tasks. This human-driven approach becomes increasingly challenging given the vast and growing diversity of open-source models and benchmark tasks.
This research proposes overcoming this limitation by introducing an evolutionary approach to automate the discovery of effective model merging solutions. Evolutionary algorithms are a class of optimization algorithms inspired by biological evolution, using processes like selection, mutation, and recombination to find optimal solutions within a search space. In this context, the "solutions" are the configurations or "recipes" for merging models.
The proposed framework dissects the merging process into two key, orthogonal configuration spaces for optimization:
- Parameter Space (PS) Merging: This involves integrating the weights (parameters) of multiple foundational models into a single model with the same neural network architecture. Existing methods like simple weight averaging (Model Soups), Task Arithmetic, TIES-Merging, and DARE fall under this category. The research's PS merging approach enhances TIES-Merging with DARE, allowing for more granular, layer-wise optimization of merging configuration parameters like sparsification and weight mixing using evolutionary algorithms.
- Data Flow Space (DFS) Merging: Unlike PS merging, which alters weights, DFS merging keeps the original layer weights intact but optimizes the inference path. This means determining which layers from which source models a token (a piece of text or data processed by the model) should pass through sequentially during inference. The search space for optimal layer sequences is astronomically large, requiring modifications like including indicator arrays and scaling parameters to make it tractable for evolutionary search. The research limited its initial DFS efforts to serial connections and non-adaptive configurations.
These two approaches can be applied independently or integrated into a hybrid strategy, for example, by first applying PS merging to create initial combined models and then using DFS merging on a collection that includes these newly merged models. This integrated strategy is particularly useful for multi-objective merging tasks.
Why it's Important
The computational cost and resource requirements for training large foundation models are continuously increasing. This makes state-of-the-art AI development inaccessible to many and contributes to a significant environmental footprint. Model merging offers a viable alternative for creating new models cost-effectively. However, the reliance on human expertise limits the discovery of truly novel and potentially more effective combinations.
The evolutionary approach presented in this research is important because it provides a systematic and automated method to overcome these limitations. By automating the discovery of merging "recipes," it has the potential to uncover non-intuitive combinations of models, even from vastly different domains, that human experts might miss.
This cross-domain merging capability is particularly significant, enabling the creation of models with entirely new combined abilities, such as language understanding paired with specific domain expertise like math or vision, in non-English languages.
The empirical results demonstrating state-of-the-art performance and surprising generalizability of the generated models, especially the 7B parameter Japanese LLM outperforming previous 70B models, highlight the efficiency and power of this automated approach.
This suggests that sophisticated capabilities can be achieved with smaller, more efficient models by cleverly combining existing ones, rather than solely relying on scaling model size and training data.
The research opens up avenues for democratizing foundation model development. By reducing the need for massive compute and specialized human intuition for merging, it makes advanced AI development more accessible to institutions, researchers, and even regions or languages with limited resources.
The successful application to other model types like diffusion models (EvoSDXL) suggests the method's versatility beyond LLMs and VLMs. Future potential applications include using evolution to select the best source models themselves or to create diverse "swarms" of models.
While the approach is promising, it is important to note that merged models can inherit limitations or biases from their source models. The complexity of these merged models might also affect their interpretability. The authors emphasize that their current models are proof-of-concept, and further verification and refinement are necessary for mission-critical or wide public use applications.
Summary of Results
The researchers demonstrated their evolutionary model merge approach by evolving two types of models: a Japanese LLM with math reasoning capabilities and a culturally specific content-aware Japanese VLM.
Evolving a Japanese Math LLM:
- Experimental Setup: The goal was to create an LLM capable of solving math problems in Japanese. Source models included a Japanese LLM (shisa-gamma-7b-v1) and two English math-specialized models (WizardMath-7B-V1.1 and Abel-7B-002), all based on Mistral-7B. Evaluation was performed on the Japanese test set of the MGSM dataset (250 problems translated from GSM8k), requiring both correct numerical answers and Japanese reasoning steps. Optimization for the evolutionary search used translated GSM8k problems that were disjoint from the test set.
- Performance Comparison: Table 1 shows the performance of the source models and the merged models on the MGSM-JA and Japanese Language Model Evaluation Harness (JP-LMEH) benchmarks.

Table 1 show a performance comparison of the LLMs (Table content showing performance scores for source models (Japanese LLM, Math LLM 1, Math LLM 2), PS-merged, DFS-merged, and Hybrid merged models on MGSM-JA (accuracy) and JP-LMEH (average) benchmarks. Source models have low MGSM-JA scores (<30), while merged models show significant improvements, especially hybrid.)
The source models, while strong in either Japanese or math, scored low on MGSM-JA (<30.0 accuracy) due to lacking proficiency in both areas simultaneously. The merged models showed a substantial performance increase. The PS-merged model achieved 52.0 accuracy on MGSM-JA. The DFS-merged model also improved performance by over 6% compared to source models. The hybrid model, combining both strategies, showed further enhancements.
Figure 2 provides a visual performance overview on the MGSM-JA test set.

Fig. 2: Performance overview. (Figure showing success rate per problem ID for various models on MGSM-JA task. Merged models show similar performance patterns to source models on initial problems but succeed on later problems where source models fail.)
This figure illustrates that the merged models retain the foundational knowledge of the source models but also exhibit emergent capabilities to solve problems that stumped the individual source models. The combined models were proficient in both Japanese language understanding and mathematical problem-solving.
On the JP-LMEH benchmark, the merged models achieved high scores (70.5 and 66.2), surpassing all existing models with <70B parameters and even the previous state-of-the-art 70B parameter Japanese LLM (Japanese StableLM 70B), despite having only 7B–10B parameters.
- Analysis of Evolved Configurations (PS): In PS merging, the evolutionary algorithm (CMA-ES) optimized merging parameters. Figure 3 illustrates the evolved parameter configurations.

Fig. 3: Evolved configurations for PS merging. (Figure showing density/weighting parameters for three source models after PS merging optimization. Shows pronounced density from the Japanese LLM.)
The analysis revealed that all three source models were important. The pronounced density from the Japanese LLM underscored its pivotal role, potentially due to its more extensive fine-tuning on a large Japanese text corpus. The sum of optimized weights exceeding 1 suggested that an amplifying combination method was more effective than simple interpolation.
- Analysis of Evolved Configurations (DFS): In DFS merging, the evolutionary process optimized the sequence of layers used from different models and scaling parameters. Figure 4 visualizes the evolved inference path.

*Fig. 4: Evolved configurations for DFS merging of models A and B. (Figure showing the sequence of layers used from Model A (blue) and Model B (red) over inference steps, with colour intensity indicating scaling factor magnitude. Shows initial steps using layers from model A, then alternating between both models.)
The evolved inference path initially favored layers from the first model (the PS-merged model in the hybrid case). As inference progressed, the method refined the selection, strategically alternating between layers from both contributing models. Crucially, the scaling parameters emerged as vital, with ablation studies showing a significant performance drop (over 20%) if they were eliminated.
An Apache 2.0-licensed version, EvoLLM-JP-A, was created using only open-source licensed models (shisa-gamma-7b-v1, Arithmo2-Mistral-7B, and Abel-7B-002). It achieved a respectable MGSM-JA score of 52.4 and a JP-LMEH score of 69.0, demonstrating the method's applicability within open-source constraints.
Evolving a Japanese VLM:
- Experimental Setup: The goal was to extend the method to multimodal models and evolve a culturally specific content-aware Japanese VLM. The LLM component of a VLM can be treated as a standalone LLM for merging purposes. The experiment merged a Japanese LLM (shisa-gamma-7b-v1) with the LLM component of an English VLM (LLaVA-1.6-Mistral-7B), both based on Mistral-7B. New Japanese VLM benchmarks were created for evaluation: JA-VG-VQA-500 (from Japanese Visual Genome VQA) and JA-VLM-Bench-In-the-Wild (culturally specific questions). Evaluation used ROUGE-L score with Japanese language detection.
- Performance Comparison: Table 2 compares the performance of the evolved VLM with baseline models.

Table 2 Performance comparison of the VLMs (Table content showing ROUGE-L scores for baseline models (LLaVA-1.6-Mistral-7B, Japanese Stable VLM) and evolved merged models on JA-VG-VQA-500 and JA-VLM-Bench-In-the-Wild benchmarks. Merged models outperform baselines on these tasks.)
The merged VLMs showed enhanced performance on both Japanese VLM benchmarks compared to baselines. This highlights the successful integration of the Japanese language capabilities from the source LLM. Simple merging without evolutionary search did not yield strong performance. Qualitatively, the evolved model handled Japanese culture-specific content remarkably well, producing more detailed and correct responses.
In summary, the experiments successfully demonstrated that evolutionary algorithms can effectively discover merging strategies in both parameter and data flow spaces to create cross-domain models that achieve state-of-the-art performance, surprising generalizability, and high efficiency, even with smaller parameter counts.
Conclusion
This research successfully demonstrated that leveraging evolutionary algorithms provides a powerful and systematic approach to optimize model merging. By exploring combinations in both parameter space and data flow space, the method overcomes the limitations of human intuition-based merging, enabling the creation of novel, cross-domain models with significantly enhanced capabilities.
The creation of a state-of-the-art Japanese math LLM and a culturally aware Japanese VLM, both achieving high performance and surprising generalizability, even surpassing much larger models, serves as compelling evidence of the effectiveness and efficiency of this approach.
The open-sourcing of the resulting models and the successful application of the method to other domains like image diffusion models underscore its versatility and potential impact on the broader AI community. This work introduces a new paradigm that challenges the conventional, expensive route of foundation model development, paving the way for more accessible, efficient, and potentially innovative AI solutions.
While acknowledging limitations such as inheriting source model issues and the need for further refinement for critical applications, the findings suggest that evolutionary model merging is a promising direction for future AI development, facilitating the harnessing of collective intelligence from existing models to unlock new emergent capabilities.


Automated Model Merging Through Evolutionary Optimization: Unlocking New AI Capabilities
Evolutionary optimization of model merging recipes