Online health information seeking has become ubiquitous, with 58.5% of US adults using the internet for health and medical questions. However, this widespread access comes with significant challenges. People often lack the medical training to know what information is relevant to share, leading to incomplete queries that produce less useful results.
For cause-of-symptom-intent questions, where someone wants to understand what might be causing their symptoms, laypeople typically do not know what contextual details matter most.
Large language models have shown impressive capabilities in encoding medical knowledge and performing well on medical exams (Singhal et al., 2023). Yet a critical gap exists between LLM performance on controlled medical scenarios and their effectiveness when laypeople use them for real health questions.
One study found that while LLMs achieved high accuracy when given complete medical scenarios directly, performance plummeted by more than half when laypeople tried to communicate those same scenarios through conversation (Bean et al., 2025). This dramatic decline stemmed from users' difficulty in providing necessary context.
Healthcare professionals receive extensive training in history-taking and are evaluated through examinations like the objective structured clinical examination. They learn to ask targeted questions to gather relevant context for differential diagnosis.
Key Takeaways
- Participants consistently preferred context-seeking AI over baseline AI, rating it higher on helpfulness, relevance, and tailoring to individual circumstances
- Conversations with Wayfinding AI averaged 4.51 turns compared to 3.69 turns for baseline AI, with significantly longer interactions for cause-of-symptom questions
- 96% of Wayfinding AI conversations included specific clarifying questions, compared to rarely asking questions in baseline AI responses
- Users were much more likely to directly answer clarifying questions when using Wayfinding AI, creating more focused and productive conversations
- A two-column interface design that separated answers from context-seeking questions improved user engagement with the clarification process
- The research highlights critical gaps in current LLM evaluation methods, which assume users know what context to share
Why Context-Seeking Matters
The research demonstrates that AI design choices profoundly impact the quality of health information conversations. When AI systems proactively engage in context-seeking, they align more closely with how human experts interact with laypeople. Medical professionals naturally employ strategies like zooming in to gain specific details, zooming out to understand broader goals, and reframing when questions rely on incorrect assumptions (Freeman et al., 2025).
Context-seeking addresses a fundamental limitation in current AI evaluation approaches. Most benchmarks for medical AI focus on single-turn responses to well-formed questions or performance on medical licensing exams. These evaluations assume the questioner knows what relevant context to provide.
In reality, laypeople often do not know what details matter, what symptoms are connected, or what background information could be crucial. By proactively soliciting this information, Wayfinding AI helps users surface details they might not have thought to share.
The impact extends to broader questions about health information access and equity as well. AI tools that require users to already know how to frame quality queries may perpetuate existing health disparities, favoring those with more health literacy or prior medical knowledge. Context-seeking AI systems can help level this playing field by guiding users through the information-gathering process regardless of their starting knowledge.
Additionally it lays the ground work for many other types of informed conversational AI. Industries from drug discovery to construction and eLearning can benefit from an AI that is well versed in extracting critical information from well guided Q&A.
How the Research Was Conducted
The research team conducted three qualitative studies and one quantitative study to iteratively develop and validate their Wayfinding AI approach. In the qualitative studies, 33 participants engaged in hour-long sessions where they discussed their actual health questions, interacted with different AI prototypes, and provided detailed feedback. Researchers observed how participants formulated queries, responded to AI questions, and perceived the conversation quality.
- Study 1 focused specifically on cause-of-symptom-intent questions and compared an AI that provided immediate answers with one that deferred answers for at least four turns while gathering context.
- Study 2 expanded to include both symptom-related and other health questions, testing a refined Wayfinding AI against a baseline model.
- Study 3 explored user interface considerations, comparing a single-column layout where answers and questions appeared together versus a two-column design that visually separated clarifying questions from substantive answers.
- The final quantitative study involved 130 US-based participants recruited through Qualtrics. Each participant used both the Wayfinding AI and a baseline AI powered by Gemini 2.5 Flash (Comanici et al., 2025) to explore their own health questions, with the order randomized.
After each interaction, participants rated their satisfaction across six dimensions including helpfulness, relevance of questions asked, tailoring to their situation, goal understanding, ease of use, and efficiency. At the end, participants directly compared the two systems.
Results: Wayfinding AI Significantly Outperforms Baseline
The study revealed clear preferences for Wayfinding AI. When asked about satisfaction with each system separately, participants reported significantly higher satisfaction with Wayfinding AI on helpfulness, relevance of questions asked, tailoring of responses, understanding of user goals, and efficiency. In direct comparisons between the two systems, Wayfinding AI was significantly preferred on helpfulness, relevance of questions, tailoring, and goal understanding.
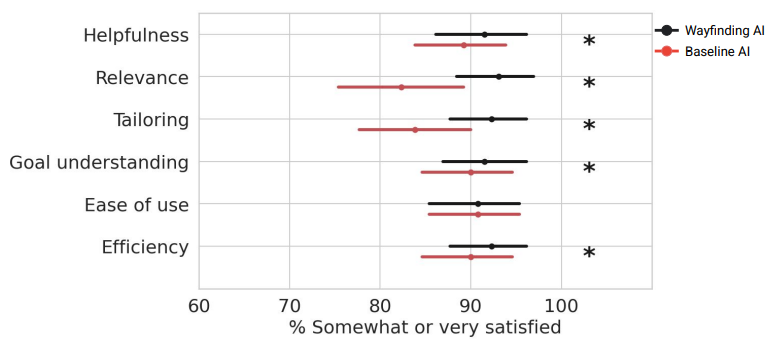
Fig. 3. Summary of satisfaction measures for Wayfinding AI and Baseline AI. Values reflect the percent of respondents who report being somewhat or very satisfied with each agent. Error bars represent 95% confidence intervals determined by bootstrap. Asterisks indicate significant difference by a Wilcoxon test, at p < 0.05, with Bonferroni correction for multiple comparisons.
Figure 3 shows the satisfaction measures, with Wayfinding AI receiving approximately 70-80% satisfaction ratings on most dimensions compared to 50-65% for the baseline AI. The differences were statistically significant even after Bonferroni correction for multiple comparisons.

Table 3. Breakdown of first responses by each AI in Study 4 based on the type of questions it asked of users. The visualization for question types for 13 turns are presented in Appendix Figure S3.
The conversational dynamics differed markedly between the two systems. Table 3 shows that Wayfinding AI asked specific clarifying questions in 96% of initial responses, while the baseline AI rarely did so.
When it did ask questions, the baseline often posed open-ended questions like "Let me know what you're aiming for, and we can build from there" rather than targeted inquiries. For example, when a participant asked about a test result, Wayfinding AI asked "Have you had any recent infections, surgeries or injuries?" providing clear direction for the conversation.
Conversation lengths revealed interesting patterns. Overall, Wayfinding AI conversations averaged 4.51 turns versus 3.69 for baseline AI. However, this difference was driven entirely by cause-of-symptom-intent questions, where Wayfinding AI conversations averaged 4.96 turns compared to 3.29 for baseline. For non-symptom questions, conversation lengths were similar, suggesting the context-seeking approach is particularly valuable when diagnostic reasoning is involved.
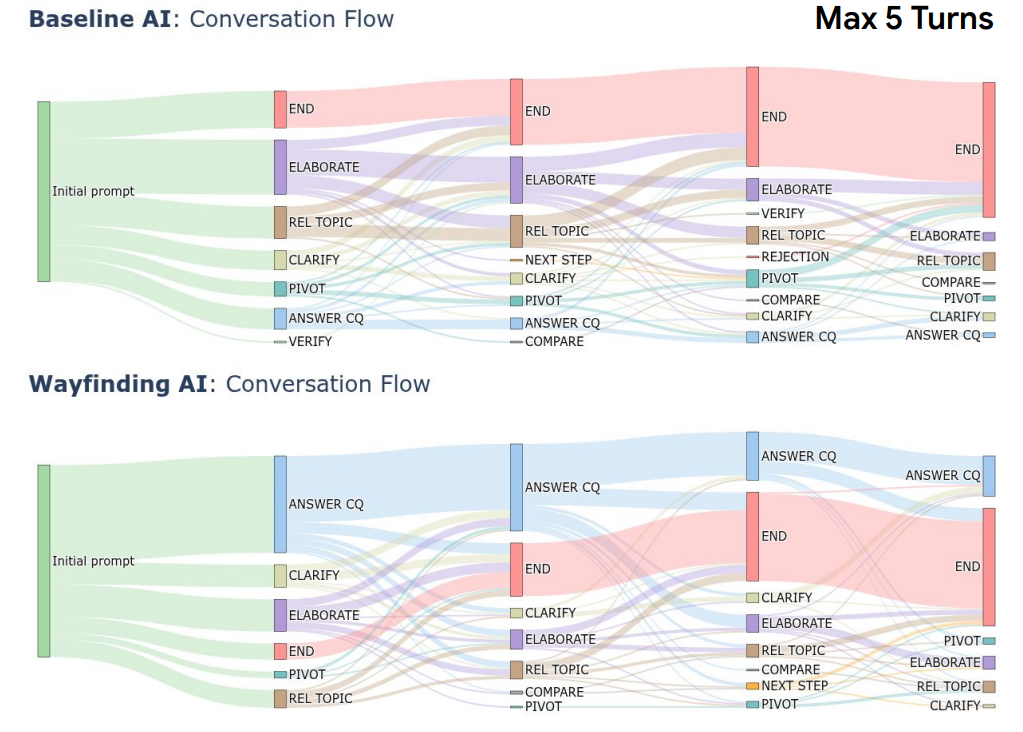
Fig. 5. Sankey flow diagrams illustrating distributions of user prompt types across conversations in Study 4. Top, summary of all conversations with Baseline AI. Bottom, summary of all conversations with Wayfinding AI. Nodes indicate different user prompt types. Thickness of lines connecting two nodes indicates relative proportion of conversations with the first prompt type followed by the second prompt type. The first 5 turns are shown. The abbreviations describing each turn type are described in more detail in the Appendix. Abbreviations: ANSWER_CQ: Answering clarifying questions asked by the AI; ELABORATION: Request for AI to elaborate on an aspect of its response; REL_TOPIC: Related topic exploration; CLARIFY: user provides refinement or clarification of their need without prompting; PIVOT: User pivots to a new topic; COMPARE: user asks AI to compare two entities related to the question; NEXT_STEP: User asks about a task-related next step; VERIFY: User expresses uncertainty or seeks confirmation of information provided. Details on how labels were applied to conversations are in the Appendix.
Figure 5 presents Sankey flow diagrams showing how conversation patterns evolved across turns. With Wayfinding AI, users predominantly answered clarifying questions that the AI asked.
With baseline AI, users more often elaborated on their own, pivoted to different topics, or ended conversations earlier. This demonstrates that the AI's behavior shapes user behavior in fundamental ways. When the AI asks specific questions, users respond to them. When it does not, users must guess what information to provide next.
The Role of Interface Design
Study 2 revealed an unexpected challenge, despite being designed to ask clarifying questions, only 1 of 10 participants directly answered them. Researchers discovered that participants often missed the questions buried within long AI responses, or did not perceive them as essential to getting relevant answers. One participant commented that the questions seemed like "rhetorical questions to consider" rather than necessary inputs.
This finding led to Study 3's exploration of interface designs. The two-column layout placed substantive answers in a right-side panel while keeping clarifying questions visible in the main conversation column below user prompts.
This visual separation helped participants recognize that answering questions would improve subsequent responses. However, participants unanimously preferred having answers expanded by default rather than collapsed behind clickable buttons, even though this meant more scrolling.
The interface evolution demonstrates that effective context-seeking requires alignment between model behavior and user interface design. Even a well-trained model that asks excellent questions can fail if the UI does not make those questions salient and actionable.
The final two-column design with expanded answers proved most effective at encouraging user engagement with the clarification process while still providing immediate value through quality responses.
What Participants Said
The qualitative studies provided rich insights into participant perceptions. Multiple participants noted that context-seeking made the interaction feel more human and trustworthy.
One participant stated, "I feel like I'm having real conversations with someone, as opposed to me trying to figure out the level of information that I need to give."
Another commented, "This one feels more like the way it would work if you talk to a doctor. Conversational... it does make me feel a little more confident that it wants to know more before jumping right into an answer."
Participants valued the clarifying questions even when they resulted in longer conversations. The questions helped them think through aspects of their situation they had not considered and provided structure for complex health concerns.
This contrasts with concerns that users always want the fastest possible answer. The research shows that when context-seeking is perceived as helpful rather than obstructive, people willingly invest more time for better outcomes.
Some participants who preferred the baseline AI in Study 2 did so because their questions required less diagnostic reasoning. For instance, someone asking "what is the prevnar vaccine" has a straightforward informational need that benefits less from extensive context-gathering. This highlights the importance of AI systems recognizing different question types and adapting their interaction strategies accordingly.
Implications for AI Development and Evaluation
The research reveals critical limitations in current approaches to evaluating medical AI systems. Most benchmarks assess LLM performance on closed-form question sets like medical licensing exams or evaluate single-turn responses to well-formed queries. These approaches assume users know what context to share and can formulate complete questions. The Wayfinding AI research demonstrates that this assumption is often false, and that multi-turn context-seeking is essential for real-world effectiveness.
Evaluation methods that rely solely on expert raters reviewing AI responses may miss crucial aspects of user experience. The study shows that user-perceived relevance, tailoring, and helpfulness depend heavily on conversational dynamics and context-gathering. An AI that provides technically accurate but poorly tailored information because it failed to gather relevant context would score well on accuracy metrics but poorly on user satisfaction.
The findings also suggest that developing effective context-seeking is technically non-trivial. Prior work found that simply prompting LLMs to ask clarifying questions actually degraded performance (Li et al., 2024), indicating that naive approaches fail.
The Wayfinding AI required careful development using prompt tuning and reinforcement learning to achieve effective context-seeking behavior. This level of sophistication goes beyond what system prompts alone can accomplish.
Limitations and Future Directions
The authors acknowledge several limitations. The study focused on text-only interactions, while many real health questions involve images, audio, or video. Multimodal context-seeking presents additional challenges and opportunities that warrant investigation. The participant pool was limited to US-based adults, and preferences may differ across cultures and healthcare systems.
Participants conversed with AI twice as part of a study, which may not perfectly reflect behavior when people first encounter a health question in daily life. The study design also combined both model behavior differences and UI differences, making it challenging to isolate the separate contributions of each factor. Future research could systematically vary these elements independently.
Perhaps most importantly, the research measured user satisfaction and preferences but did not directly assess health outcomes. Does more effective context-seeking lead to better health decisions, more appropriate care-seeking behavior, or improved health literacy? These questions require longitudinal studies that follow users beyond individual conversations to understand downstream impacts.
The Path Forward
Wayfinding AI represents a significant advance in making AI-powered health information tools more effective for laypeople. By proactively gathering context through targeted questions, these systems can provide more relevant, personalized, and helpful information.
The researchers demonstrated that users value this approach, perceiving it as more aligned with expert human communication patterns and more respectful of their individual circumstances.
The work highlights critical considerations for AI developers working on health applications. Context-seeking behavior must be carefully designed and tuned, not simply prompted.
User interfaces need to make clarifying questions salient and actionable. Evaluation approaches should assess multi-turn conversational effectiveness and user-perceived relevance, not just single-turn accuracy on expert-curated questions.
As AI systems become increasingly common tools for health information seeking, design patterns like those explored in this research become essential. The question is not whether people will use AI for health questions, but whether those AI systems will be designed to gather the context necessary to provide truly helpful, safe, and relevant information. Wayfinding AI points toward how that can be achieved.
Key Terms and Concepts
Wayfinding AI: An AI system designed to proactively seek context through targeted clarifying questions before providing substantive answers to health-related queries. The term reflects the system's role in helping users navigate complex health information needs.
COSI (Cause-of-Symptom-Intent): Questions where a person wants to understand what might be causing a set of symptoms they or someone else is experiencing. These questions particularly benefit from context-seeking because laypeople often do not know what information is diagnostically relevant.
NCOSI (Non-Cause-of-Symptom-Intent): Health questions that do not involve symptom diagnosis, such as understanding a medical condition, treatment options, or general health information.
OHIS (Online Health Information Seeking): The phenomenon of people using internet resources including search engines, social media, and now AI chatbots to find information about health and medical topics.
Context-seeking: The practice of an AI system asking clarifying questions to gather relevant background information, symptoms, circumstances, and other contextual details that improve the accuracy and relevance of its responses.
Differential diagnosis: The process of distinguishing between multiple possible conditions that could explain a set of symptoms, a key task in clinical medicine that requires gathering detailed patient history and context.
Gemini 2.5 Flash: The large language model from Google used as the baseline AI in the study. The Wayfinding AI was built on top of this model using additional prompt tuning and reinforcement learning.
Wizard-of-Oz design: A research method where human experts power what participants believe is an AI system, allowing researchers to study ideal interaction patterns before the technology is fully developed.


Wayfinding AI: Transforming Health Conversations Through Context-Seeking
Towards Better Health Conversations: The Benefits of Context-seeking