UItron is an open-source foundation model for GUI agents that tackles a hard problem in computer use automation: understanding complex interfaces and turning natural language goals into precise on-screen actions.
Developed by a team at Meituan and released as a 24-page technical report, the work proposes a data-first and infrastructure-first approach to build perceptual and planning capabilities that generalize across mobile and desktop environments.
The authors release two model variants and emphasize rigorous evaluation across perception, grounding, offline planning, and online planning benchmarks, with a dedicated focus on Chinese mobile apps where many systems underperform.
At its core, UItron integrates three supervised stages for perception and planning, and adds a curriculum reinforcement learning stage that mixes dense step-level rewards (offline) with trajectory-level rewards (online).
It builds an interactive stack spanning Android cloud devices and real-computer environments to collect trajectories, run evaluations, and support online RL. UItron also consolidates multi-source UI data, unifies task formats, and studies reasoning templates and backtracking to make agents more reliable and human-like in their decision-making (UITron-hub/UItron).
Key Takeaways
- Foundational framing: UItron positions robust GUI agents as a foundation model problem that requires systemic data engineering and interactive infrastructure, not just bigger backbones.
- Unified capabilities: The system covers perception, grounding, multi-step planning, and reinforcement learning with curriculum design to reduce sparse rewards.
- Interactive stack: A cloud Android device farm plus a real PC environment enables automated logging, online evaluation, and RL rollouts. For PC, the authors build on OSWorld's verified environment (Xie et al., 2024; OSWorld site).
- Data engineering: UItron scales by unifying multi-turn perception data, cross-platform grounding corpora, reasoning formats, backtracking, and distilled trajectories.
- Chinese app focus: UItron reports substantial gains on top Chinese apps using more than one million manually labeled action steps and a cloud-device testbed.
- Competitive results: On widely used benchmarks, UItron's perception and grounding results are state of the art or competitive; online agent performance is close to or better than top GUI baselines (Qin et al., 2025; Wu et al., 2024; Xu et al., 2025).
Overview
UItron addresses an end-to-end problem: given a natural language task and a current screen, predict the next action while maintaining context coherence over a trajectory. The authors formulate the agent's next-action prediction over history and the current observation, and also introduce a backtracking formulation that teaches the model to infer what sequence of actions must have led to the current state. This bi-directional perspective improves temporal coherence in long tasks.
Perception is treated as a first-class capability. The team aggregates UI-grounded visual understanding across OCR, VQA, element captioning, and grounding tasks, organizing multi-turn conversations around a single screenshot to reduce redundant image loads. They unify perception and agentic data into one format, and stitch together cross-platform grounding corpora from major recent works to improve generalization across mobile, desktop, and web settings.
Representative benchmarks include VisualWebBench for web page understanding and grounding (Liu et al., 2024) and ScreenSpot/ScreenSpot-V2 for GUI element grounding across platforms (Cheng et al., 2024).
For planning, UItron uses a tiered L1/L2/L3 structure: from action-only predictions to reasoning-augmented and screen-context-aware reasoning. During inference, the system favors L2-style descriptions to balance performance and efficiency.
The model outputs are explicitly segmented to separate reasoning from function calls, easing integration with action execution APIs. Backtracking augments learning with reflective reconstruction of the steps that produced the current state, encouraging consistency between thought and action.
Finally, the curriculum reinforcement learning stage applies group relative policy optimization, using dense rewards offline (per step) and trajectory-level rewards online. To improve reward reliability, UItron ensembles multiple scoring models and only retains trajectories that receive consistent success signals across models.
The OSWorld-verified environment is used for PC-side rollouts and evaluation (Xie et al., 2024; OSWorld site), and an Android cloud device farm serves the mobile side.
Why It Matters
Many GUI systems either specialize in static perception or rely heavily on proprietary models and toolchains. UItron aims to be a reusable foundation with open data practices, unified formats, and scalable infrastructure. This direction matters because practical computer-use agents need:
1) strong spatial understanding of UI layouts across platforms;
2) reliable grounding for icons, widgets, and text under varied resolutions;
3) robust planning over longer horizons with reflection and error correction; and
4) an evaluation and training loop that connects model predictions with real environments.
The combination of perception-first training, structured planning, and curriculum RL is a plausible recipe for pushing agents closer to trustworthy deployment in productivity, support, and accessibility scenarios.
The focus on Chinese apps is also pragmatic since benchmark ecosystems can be skewed to English. By constructing a large-scale Chinese interaction dataset and an online test harness, the authors showcase how foundational agents can close gaps for users who rely on non-English mobile experiences.
Discussion
Results Summary.
Across perception and grounding, UItron reports top or near-top performance on VisualWebBench and ScreenSpot/ScreenSpot-V2, and strong grounding and step success rates on AndroidControl and GUI-Odyssey. On OSWorld's verified setup, UItron reaches competitive success rates among GUI agents while specialized computer-use systems still lead overall, which is consistent with OSWorld's broader findings that end-to-end GUI agents lag on long-horizon tasks (Xie et al., 2024).
Figures and Tables.
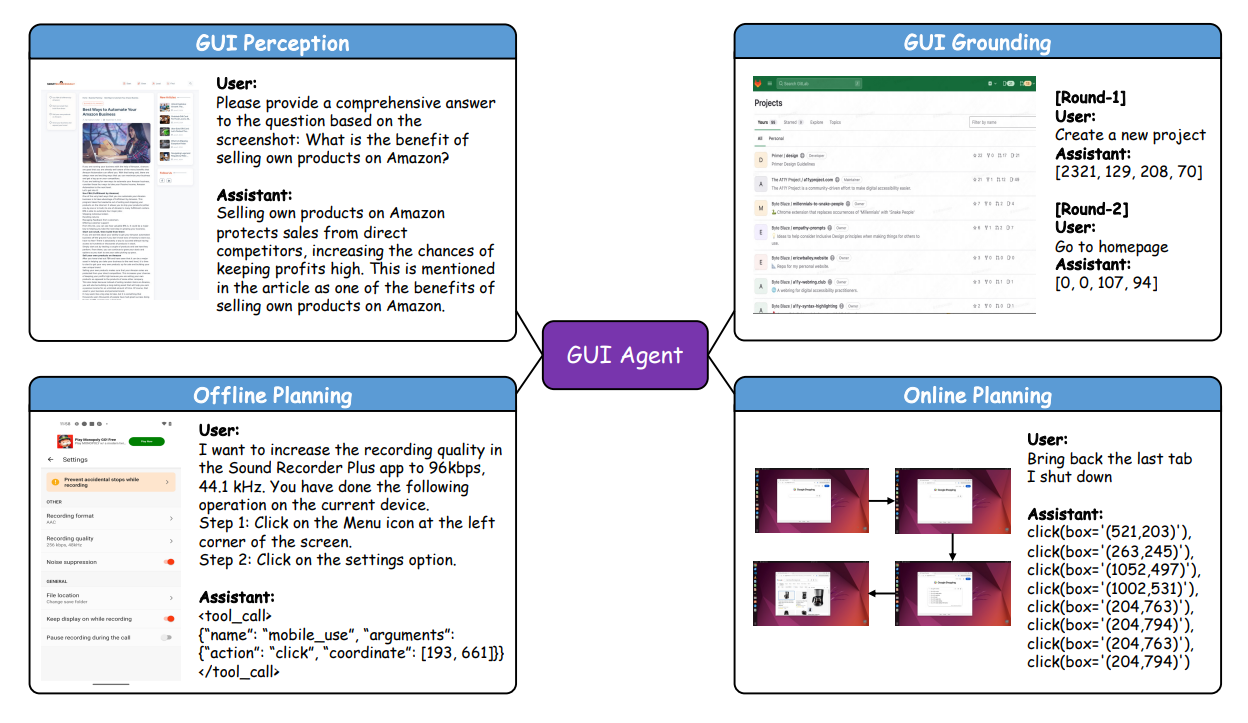
The paper's Figure 2 distills UItron's four core capabilities: GUI perception, grounding, offline planning, and online planning. It also illustrates two example rollouts: an offline planning trace with stepwise actions on an Android app, and an online PC recovery scenario requiring multiple clicks and confirmations. This directly supports the claim that combining perception, grounding, and planning is necessary for real-world tasks.
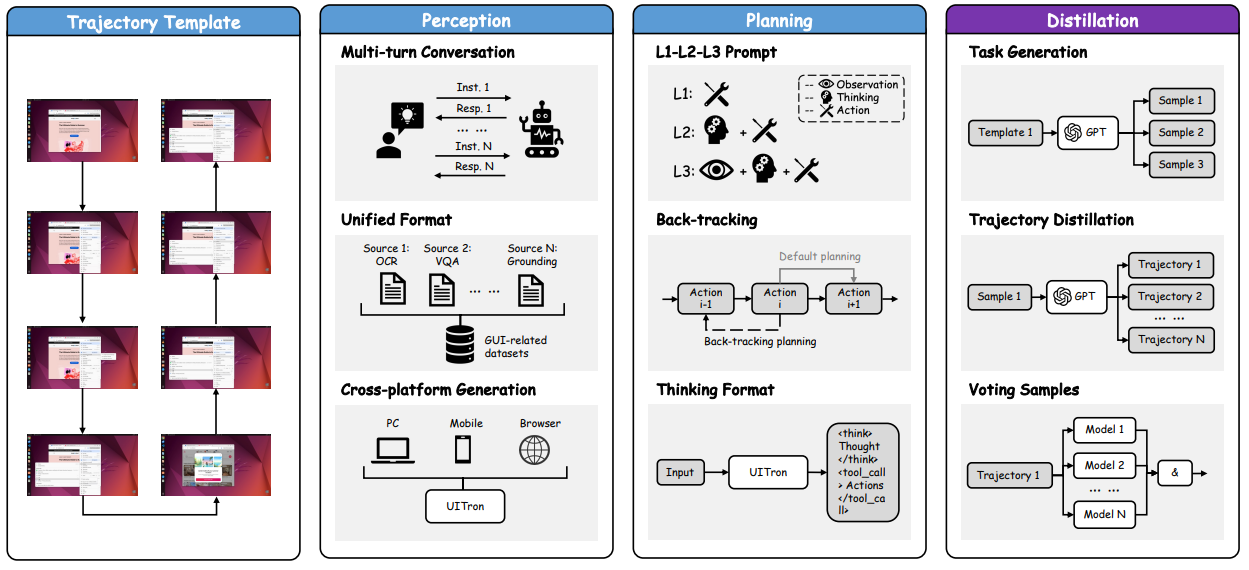
Figure 3 summarizes the data engineering pipeline and shows how perception data, planning data, and distillation converge into a unified trajectory template. Importantly, it emphasizes multi-turn consolidation for screenshots and cross-platform generalization by unifying multiple grounding datasets. This is central to the generalization claims on ScreenSpot/ScreenSpot-V2 (Cheng et al., 2024).
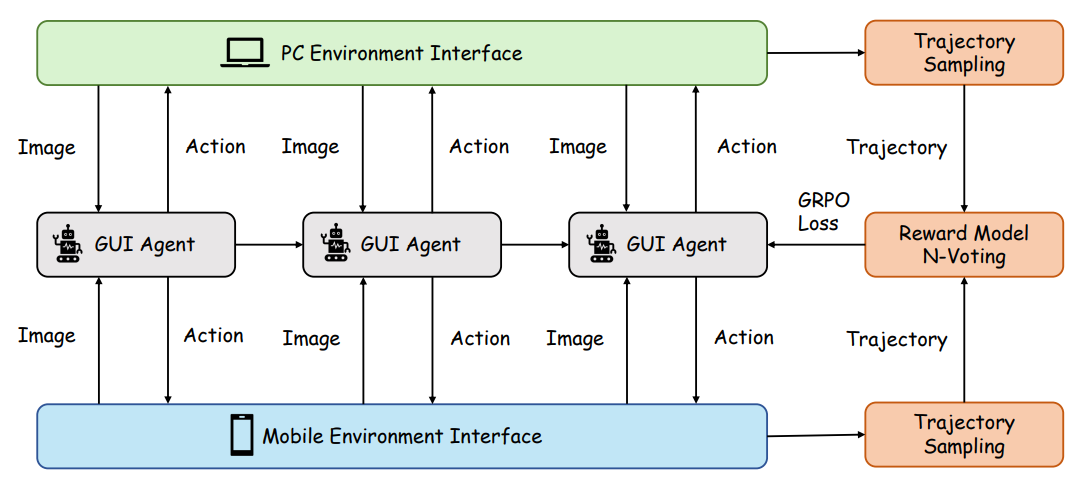
Figure 4 depicts the interactive infrastructure, with the mobile cloud device stack on the left and PC environment on the right. The mobile stack combines scrcpy-based streaming, an input translation service, and a device-agent that exposes HTTP endpoints for install and device management, enabling automated collection and online evaluation. For PC, UItron leverages OSWorld's real-computer environment, which supports cross-OS tasks and verified evaluation (OSWorld site).
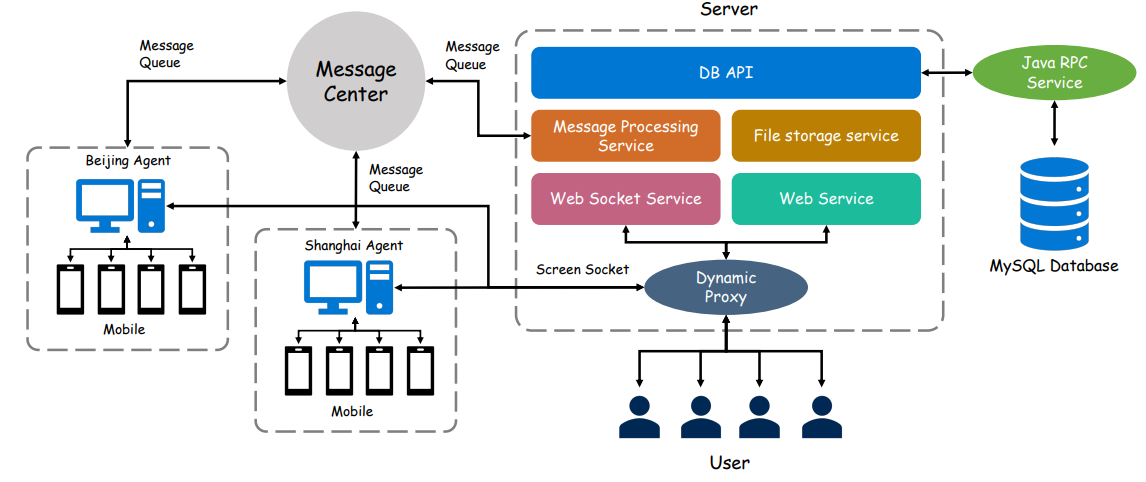
Figure 5 zooms into the mobile infrastructure architecture, detailing the Agent/Server pattern and realtime communication, which is key for collecting reliable ground-truth trajectories at scale in Chinese app scenarios.
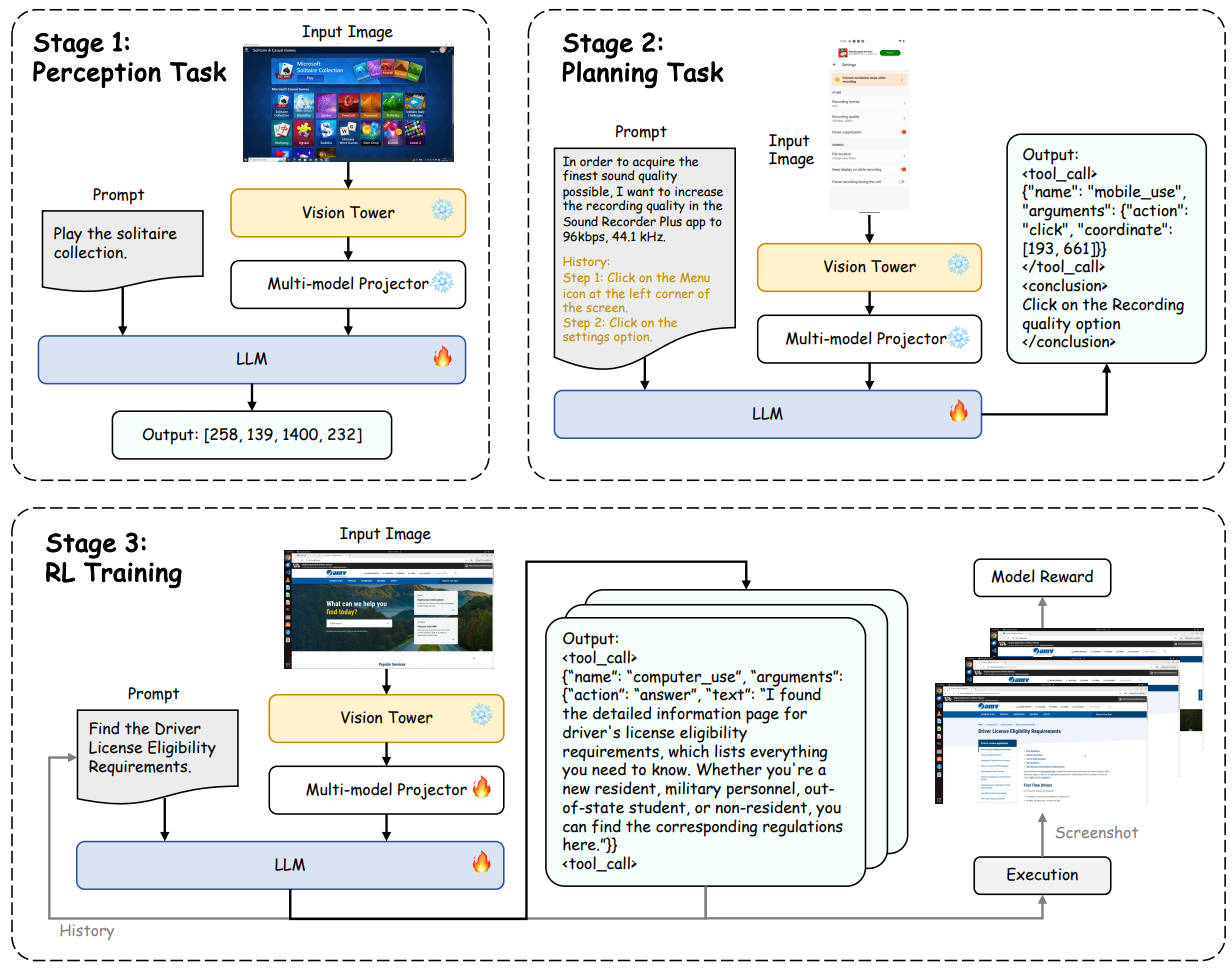
Figure 6 lays out the three-stage training paradigm: perception SFT, planning SFT, and curriculum RL with GRPO. The figure makes clear where dense step rewards versus trajectory-level rewards apply, and how the group-normalized advantage stabilizes RL updates.
Benchmarks and Context
The reported benchmarks are widely used in this domain and have active communities and open resources.
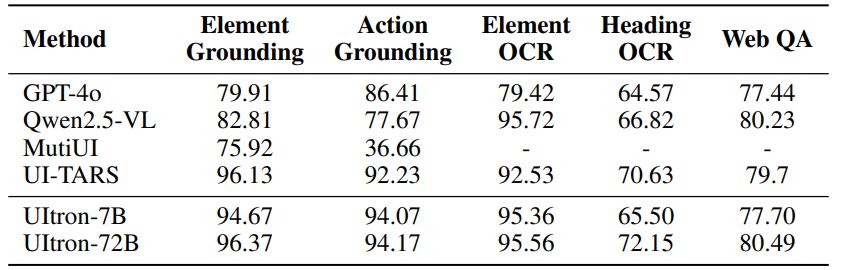
Table 3: Comparative results on VisualWebBench. VisualWebBench targets web UI understanding and grounding on real sites (Liu et al., 2024).
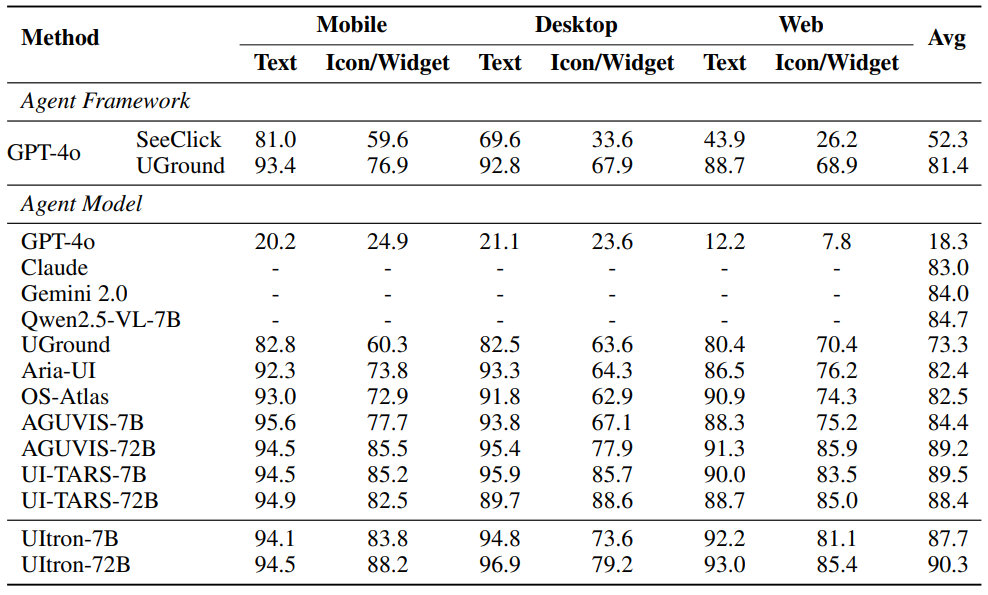
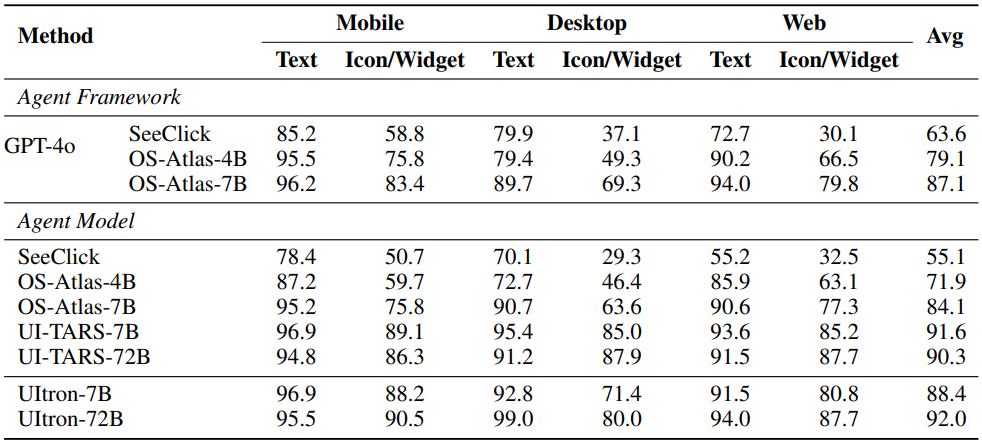
Table 5: Comparison of different baseline methods on ScreenSpot and ScreenSpot-V2 respectively. ScreenSpot and ScreenSpot-V2 provide cross-platform grounding tasks across text and icon/widget targets (Cheng et al., 2024).
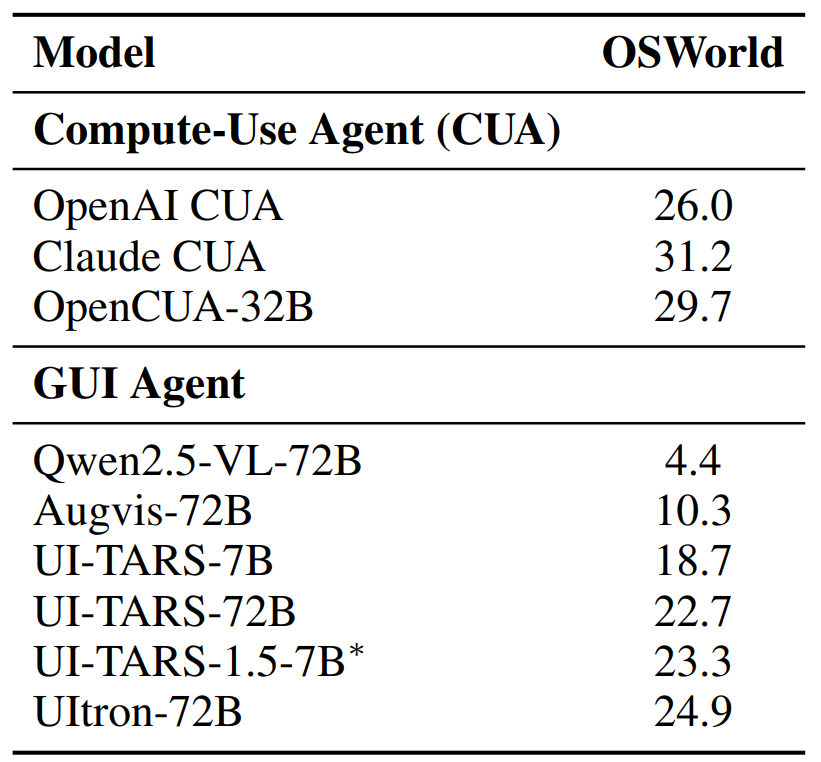
Table 8: Task Success Rates (SR) on OSWorld [70]. We report results on their official verified environment (i.e., OSWorld-verified) that fix several issues. ∗ denotes our reproduction within the same environment. OS-Atlas offers a synthesis toolkit and a large cross-platform grounding corpus that multiple agents now use for training and evaluation (Wu et al., 2024).
AGUVIS separates grounding from planning and adds structured reasoning via inner monologue to improve long-horizon tasks (Xu et al., 2025).
UI-TARS is a leading native GUI agent, offering a useful point of comparison for UItron in both perception and end-to-end tasks (Qin et al., 2025).
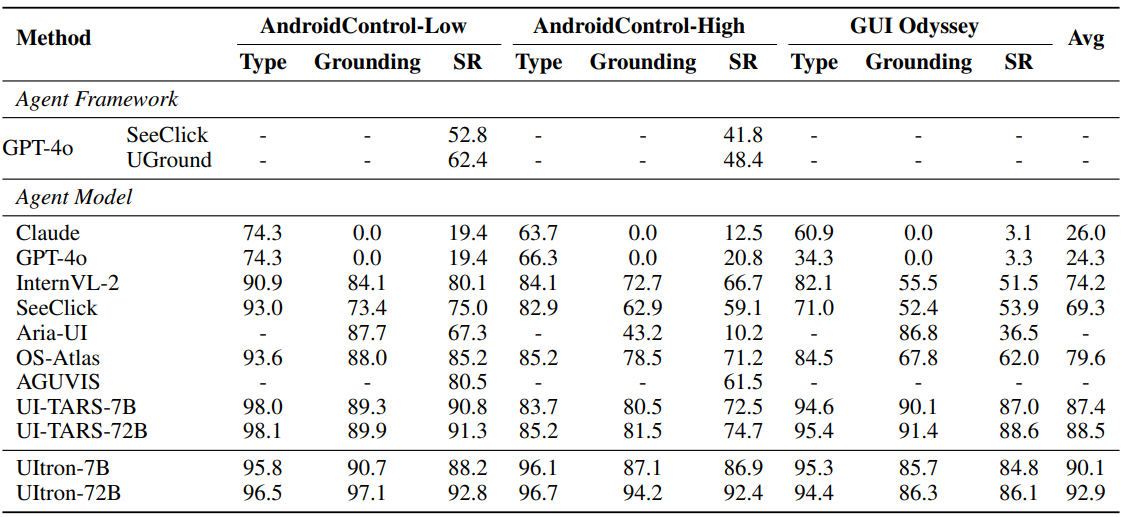
Table 7: Comparative results on AndroidControl-Low [30], AndroidControl-High [30] and GUIOdyssey. While the AndroidControl benchmark is frequently referenced for step-level planning evaluation, the official proceedings page is not consistently accessible at the time of writing; the paper cites it as a NeurIPS 2024 contribution by Li et al. I recommend readers consult the NeurIPS 2024 proceedings index or author repositories for canonical links when available.
Interpretation
UItron's strongest contributions are architectural and infrastructural. The authors show that careful unification of multimodal UI data, reasoning formats, and backtracking, combined with an interactive stack and staged RL, can move the needle across diverse benchmarks. The explicit focus on Chinese apps highlights a persistent gap in many GUI agents and demonstrates that targeted data collection plus infrastructure can yield large practical gains.
Limitations and Future Directions
The authors note occasional misalignment between generated thoughts and actions. Backtracking and GRPO help, but a robust correction loop for thought-action consistency is an open problem.
Multi-agent collaboration, explicit reflection scheduling, and tighter coupling between reasoning and execution are sensible next steps. The OSWorld team's analysis suggests higher-resolution screenshots and longer text histories often help but carry efficiency costs; UItron's choice to omit historical images in many cases to save compute is pragmatic, but richer temporal context may still matter for some tasks (Xie et al., 2024).
Conclusion
UItron offers a realistic blueprint for building general-purpose GUI agents: unify the data, build the infrastructure, stage the training, and validate on both offline and online pathways. The paper is a thorough consolidation of best practices with a few targeted innovations, and the results across web, desktop, and mobile benchmarks show the approach scales. If you are building GUI agents, treat UItron as a pattern library for data, infra, and evaluation. Read the paper, inspect the repository, and adapt the multi-stage training flow to your environment.
Definitions
GUI grounding: Mapping a natural language reference to the precise on-screen region corresponding to a UI element (text, icon, widget).
Offline planning: Next-step action prediction from logged trajectories, evaluated stepwise against ground truth.
Online planning: Executing actions in an environment until success or termination without access to ground-truth steps; success is judged at the trajectory level.
Curriculum RL: A staged RL process that starts with simpler or denser reward signals and progresses to harder, sparser ones.
GRPO: Group Relative Policy Optimization, which normalizes per-group advantages to stabilize updates during RL.
References
(Zeng et al., 2025) UItron: Foundational GUI Agent with Advanced Perception and Planning. arXiv:2508.21767. DOI: 10.48550/arXiv.2508.21767.
(UITron-hub/UItron) Repository homepage.
(Xie et al., 2024) OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. arXiv:2404.07972. See also the OSWorld site.
(Cheng et al., 2024) SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents. arXiv:2401.10935.
(Liu et al., 2024) VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding? arXiv:2404.05955.
(Wu et al., 2024) OS-ATLAS: A Foundation Action Model for Generalist GUI Agents. arXiv:2410.23218.
(Xu et al., 2025) AGUVIS: Unified Pure Vision Agents for Autonomous GUI Interaction. arXiv:2412.04454.
(Qin et al., 2025) UI-TARS: Pioneering Automated GUI Interaction with Native Agents. arXiv:2501.12326.



UItron Sets a Higher Bar for GUI Agents
UItron: Foundational GUI Agent with Advanced Perception and Planning