Modern AI agents are learning to use computers like humans do. They can navigate websites, manage files, and even play games by controlling desktop and mobile interfaces directly. This paper introduces a new approach to training these "computer-use" agents.
Building on their previous UI-TARS-1.5 system, the team made four major improvements. First, they created a "data flywheel" that automatically sorts training examples by quality and routes them to the right training stage. Second, they built an integrated testing environment that combines GUI control with terminal commands and file operations. Third, they developed a more stable reinforcement learning approach for multi-step tasks. Finally, they introduced a technique to merge specialized models without retraining from scratch.
UI-TARS-2 stands out for two key innovations: a self-improving data pipeline that continuously refines training examples, and a reinforcement learning system designed for long, multi-step tasks. The researchers report strong performance across challenging benchmarks that test real-world computer use scenarios.
The system was evaluated on rigorous benchmarks including Online-Mind2Web ((Xue et al., 2025)), OSWorld ((Xie et al., 2024)), AndroidWorld ((Rawles et al., 2024)), and LMGame-Bench ((Hu et al., 2025)). These tests span web browsing, desktop operations, mobile interactions, and game playing.
Key Takeaways
- A practical data flywheel automatically improves training data quality over time by recycling model-generated examples and routing them to the most appropriate training stage.
- A hybrid testing environment combines virtual machines, web browsers, file systems, and terminals to create realistic computer-use scenarios for training and evaluation.
- Advanced reinforcement learning techniques including parallel training, value function pre-training, and adaptive reward shaping significantly improve training stability for long, multi-step tasks.
- Strong benchmark results: 88.2% on Online-Mind2Web, 47.5% on OSWorld, 50.6% on WindowsAgentArena, 73.3% on AndroidWorld, plus competitive performance on game-playing benchmarks.
- A novel parameter merging technique combines specialist models for different domains (web browsing, general GUI, games, terminal use) without requiring expensive joint retraining.
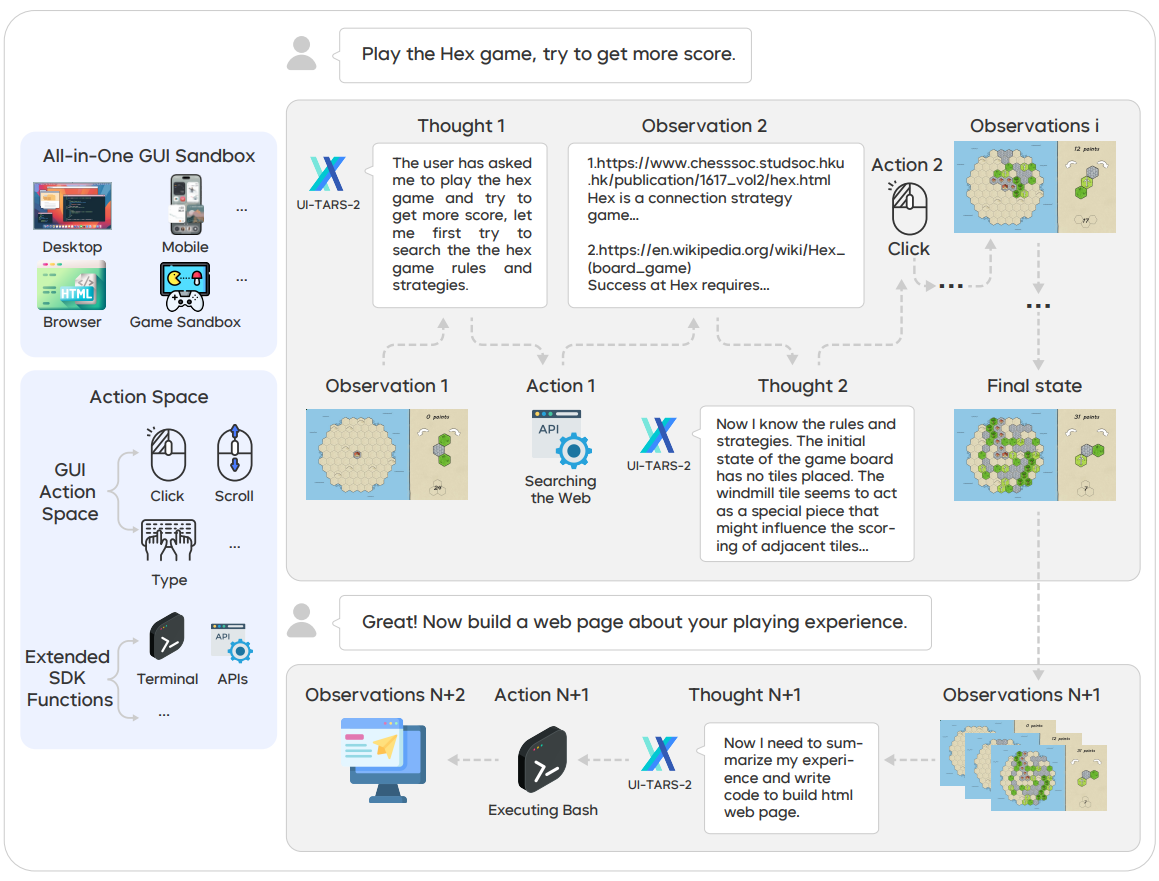
Figure 1 A demo trajectory of UI-TARS-2. Credit: Wang et al.
This figure visually illustrates a demonstration trajectory of UI-TARS-2, highlighting its ability to integrate different interaction modalities and reasoning steps. It serves to introduce the methodology of UI-TARS-2 as a unified framework for advanced GUI-centered agents. This visually represents the ReAct paradigm (Reasoning, Action, Observation) that the agent follows and the broad "Action Space" including GUI actions (Click, Scroll, Type) and pre-defined SDK functions.
How UI-TARS-2 Works
The Core Agent Design of UI-TARS-2 operates as a "native" agent, meaning it directly controls computer interfaces through a continuous loop of reasoning, action, and observation. Unlike agents that rely on intermediate APIs, UI-TARS-2 sees screenshots and performs actions like clicking, typing, and scrolling just as humans do.
It can also execute terminal commands and file operations when needed. Each step in this reasoning-action cycle maintains both working memory (for the current task) and episodic memory (for learning from past experiences).
The Integrated Testing Environment provides extensive and efficient encapsulation for running OS and Web actions. The researchers built a comprehensive testing infrastructure that combines two major components.
One for graphical interfaces, where cloud-based virtual machines running Windows, Ubuntu, and Android systems are used. These VMs provide a unified interface for allocating resources, capturing interactions, taking screenshots, and running evaluations.
Second for web-based tasks and games, they developed a specialized browser environment with hardware acceleration, time control for reproducible testing, crash recovery, and the ability to save and restore sessions.
At the heart of UI-TARS-2 is a Self-Improving Data Pipeline or "data flywheel" that continuously improves training data quality. The process works in cycles: the current model generates new interaction sequences, human evaluators or automated systems assess their quality, and the system automatically routes high-quality examples to supervised training while sending lower-quality examples to broader knowledge training. Over time, this creates a feedback loop where better models generate better training data, which leads to even better models.
To facilitate this data pipeline human expertise is injected through two complementary approaches. For general knowledge training, researchers developed an unobtrusive annotation system that captures human reasoning while they naturally use their computers.
While for more targeted training, an interactive interface allows humans to observe the agent's actions in real-time, accepting good decisions, correcting mistakes, and providing alternative strategies.
Finally, the reinforcement learning component tackles three distinct domains.
For web browsing, the agent learns to navigate complex, multi-step information gathering tasks that are evaluated by specialized language models calibrated against human judgment.
For general computer use, it handles tasks with either automated verification systems or outcome prediction models.
For games, it uses JavaScript-based verifiers that can read game state directly. The training process includes sophisticated techniques like reward shaping, value function pre-training, and adaptive algorithms that adjust to sequence length.
Why This Research Matters
Building effective computer-use agents requires solving several challenging problems simultaneously. These agents need reliable memory systems, robust error recovery, flexible tool integration, and the ability to handle tasks that span multiple applications and interfaces. UI-TARS-2 addresses each of these challenges with practical engineering solutions that move the field beyond simple demonstrations toward production-ready systems.
The hybrid testing environment represents a significant advancement because real computer work rarely happens in isolation. Users typically combine web browsing with file management, terminal commands with graphical applications, and multiple tools to accomplish complex goals. By training and testing in this realistic environment, UI-TARS-2 develops more robust and transferable skills.
The data flywheel approach also solves a critical problem in AI agent development: how to continuously improve without manual data collection bottlenecks. Traditional approaches require expensive human annotation for every new task or domain. UI-TARS-2's self-improving pipeline allows the system to bootstrap from initial human guidance and gradually become more autonomous.
Perhaps most importantly, the evaluation benchmarks used in this work represent a new standard of rigor. Online-Mind2Web evaluates agents on live websites with automatic judges calibrated against human ratings and AndroidWorld provides dynamic, parameterized tasks in realistic mobile environments. These benchmarks test not just whether agents can perform scripted tasks, but whether they can adapt to the variability and complexity of real-world computer use.
Results and Analysis
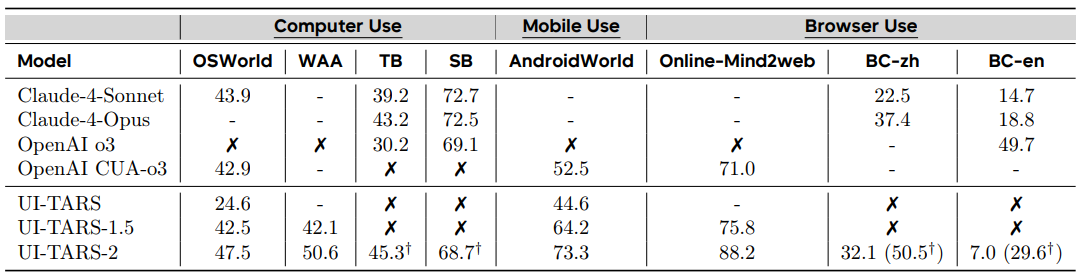
Table 1 Performance on computer use, mobile use, and browser use benchmarks. “-” indicates unavailable; ✗ denotes lack of ability; and † indicates results obtained with an extended action space that includes GUI-SDK. Terminal Bench results are reported on 75 out of 80 tasks due to compatibility issues with our internal environment. Abbreviations: WAA (WindowsAgentArena), BC-en (BrowseComp-en), BC-zh (BrowseComp-zh), TB (Terminal Bench), SB (SWE-Bench). Credit: Wang et al.
UI-TARS-2 demonstrates strong performance across diverse evaluation scenarios. The system achieved 88.2% success on Online-Mind2Web (web browsing), 47.5% on OSWorld (desktop operations), 50.6% on WindowsAgentArena (Windows-specific tasks), and 73.3% on AndroidWorld (mobile interactions). In gaming environments, it scored an average of 59.8 across 15 different web games and showed competitive performance on LMGame-Bench compared to leading proprietary models.
The research paper includes several revealing visualizations that demonstrate the system's learning process. The figures show how the agent alternates between reasoning and action in real scenarios, the technical architecture of the testing environment with its multiple components and safety features, and the continuous data improvement cycle that drives the flywheel approach.
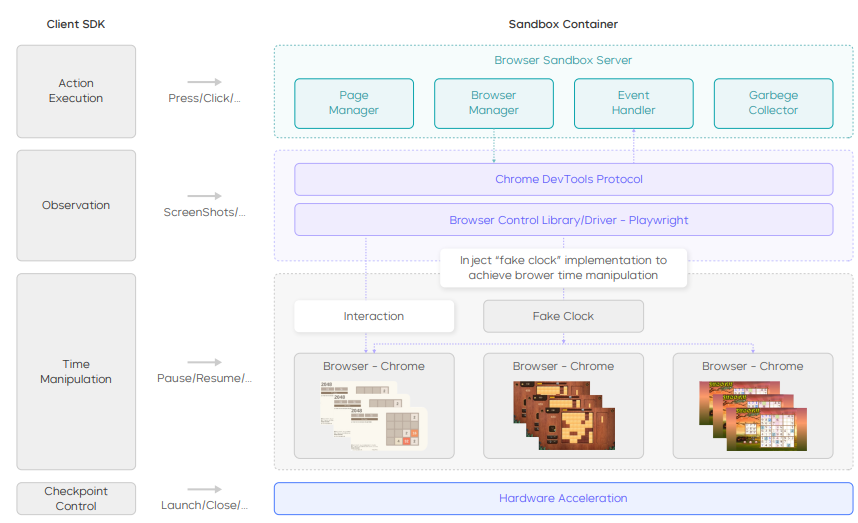
Figure 2: Browser sandbox (container) architecture. This diagram illustrates the architecture of the hardware-accelerated browser sandbox, which is designed to support high-throughput rollouts for multi-turn Reinforcement Learning (RL) on web-based mini-games. The figure clearly shows how the browser sandbox achieves concurrency by running multiple browser instances per container.
Figure 2 shows how the browser sandbox achieves concurrency by running multiple browser instances per container. Key components include a "Browser Sandbox Server" managing "Browser - Chrome" instances, a "Page Manager" for page creation/deletion and state tracking, and an "Event Handler" for reporting browser/page events. Hardware Acceleration is explicitly mentioned to reduce screenshot overhead. The architecture also includes "Time Manipulation" through a "Fake Clock" to accelerate time and pause at startup, improving sampling efficiency and reproducibility without altering game logic. Actions (e.g., Press/Click) and observations (e.g., ScreenShots) flow through this system, completing the standard action-to-state loop required for RL. The design ensures stability, reproducibility, and high-concurrency for web-stack environments.
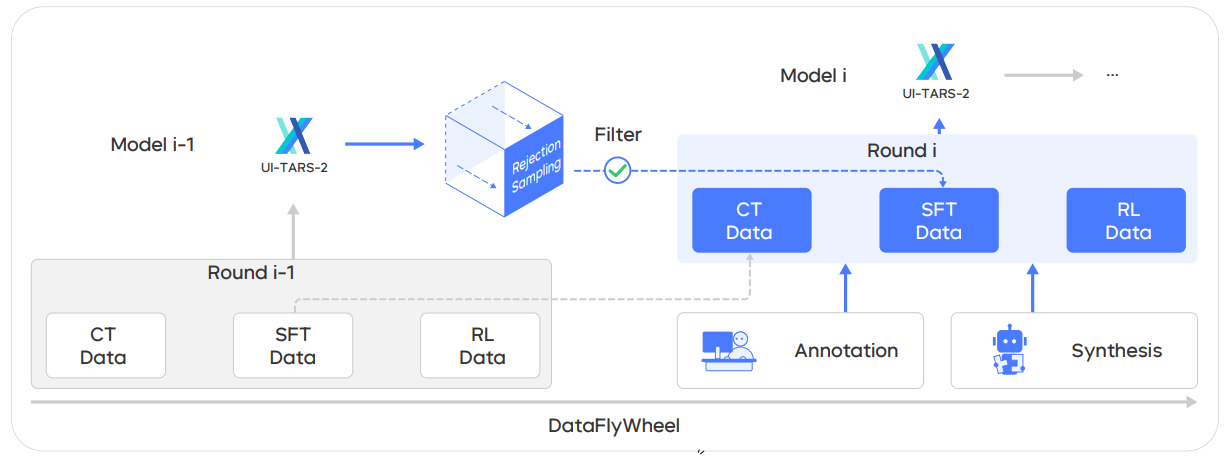
Figure 3: We curate a Data Flywheel for UI-TARS-2, establishing a self-reinforcing loop that continuously improves both data quality and model capabilities.
Figure 3 provides an overview of the "Data Flywheel" methodology, a key component designed to mitigate data scarcity and continuously improve UI-TARS-2's capabilities and data quality through iterative training cycles.
The diagram depicts a self-reinforcing loop where the "Model i-1" generates new "RL Data" (trajectories). This data then undergoes a "Filter" step. High-quality outputs are promoted to the "SFT Data" (Supervised Fine-tuning) dataset for the next iteration, while lower-quality outputs are recycled into the "CT Data" (Continual Pre-training) dataset. This dynamic reallocation ensures that each training stage (CT, SFT, RL) operates on optimally matched data, leading to a cycle where better models yield better data, and better data produces better models. The flywheel starts with "Cold-start Data Sources" for CT and SFT (Annotation, Synthesis). As iterations progress, the improved model ("Model i") generates a higher proportion of high-quality outputs, accelerating capability growth and ensuring no data is wasted.
Most importantly these learning curves demonstrate that reinforcement learning rewards increase over time, exploration behavior becomes more focused, and the agent requires fewer steps to complete tasks as training progresses. Comparisons between different training algorithms show that their chosen approach (PPO) provides more stable learning than alternatives.
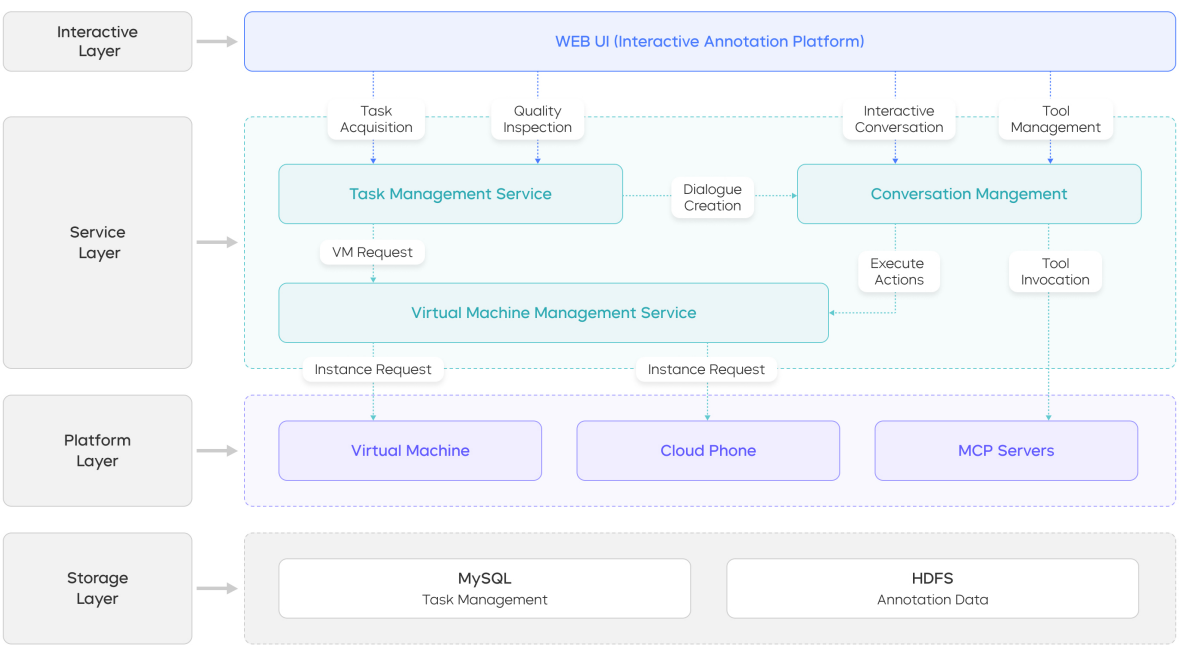
Figure 4: The four-layer architecture of the interactive annotation platform. Credit Wang et al.
This figure illustrates the system design of the interactive annotation platform, which enables human annotators to provide online supervision directly within the agent’s rollout.
The annotation architecture is divided into four modular layers:
- Interaction Layer (top): Presents the user interface for annotators to engage with the system in real-time.
- Service Layer: Processes annotation requests and orchestrates model-generated command execution and human interventions.
- Platform Layer: Provides scenario-specific execution environments (e.g., Computer Use, Phone Use, Tool Use) tailored for different task categories.
- Storage Layer (bottom): Securely logs annotation data and complete interaction trajectories for downstream training and analysis.
The overall design highlights the modular separation between layers and their control flow, supporting a human-in-the-loop framework for online, interactive data annotation to bridge the gap of off-policy human-generated SFT data.
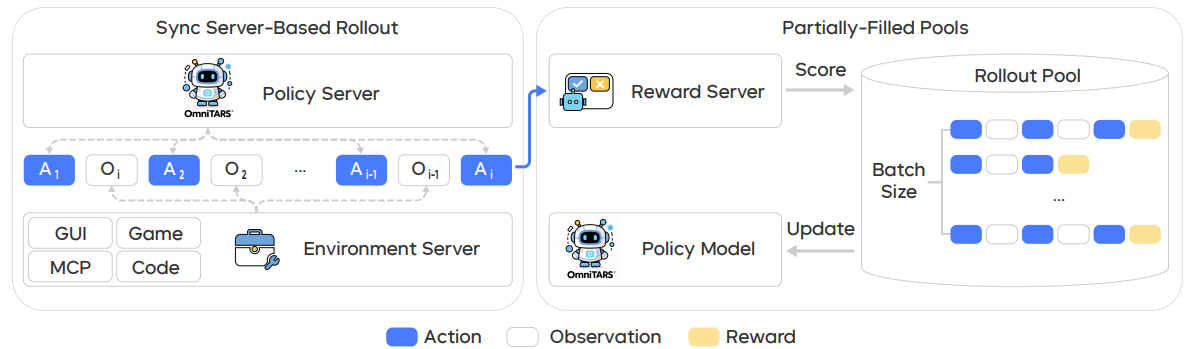
Figure 6: The multi-turn RL training infrastructure of UI-TARS-2. Credit Wang et al.
Figure 6 illustrates the core components of the multi-turn RL training infrastructure designed to enhance training stability and optimize efficiency in multi-turn rollout interactions and training sample organization.
The infrastructure shows a "Policy Server" sending policy models to "Code Policy Model". The "Environment Server" (supporting GUI, MCP, Game environments) interacts with the policy model through "Action" and "Observation" loops. A "Reward Server" provides "Score Reward" feedback. Key features highlighted are:
- Asynchronous Inference with Server-Based Rollout: Decouples agent reasoning from policy inference, improving usability and efficiency.
- Streaming Training with Partially-Filled Rollout Pools: "Rollout Pool" initiates training updates once completed traces reach a minimum batch size, avoiding bottlenecks from long-tail trajectories.
- Stateful Agent Environment Integration: Preserves execution states across multiple tool invocations and maintains context for complex, multi-step reasoning.
This design addresses challenges like traditional batch-based rollout bottlenecks and ensures continuous learning progress.
Technical Implementation
The underlying model combines a 532-million-parameter vision system with a 23-billion active parameter mixture-of-experts language model (230 billion total parameters). The training process mixes agent-specific data with general conversational and reasoning datasets, while reinforcement learning uses verifiable tasks and outcome prediction models for scoring.
Evaluation spans multiple domains including computer use, mobile interfaces, web browsing, and games. Notably, when the system is allowed to use both graphical interfaces and command-line tools, its performance on information-seeking and software development tasks improves significantly compared to GUI-only approaches.
Limitations and Open Questions
As a technical report, some implementation details are summarized rather than fully specified, which may make reproduction challenging. The outcome prediction models used for scoring sometimes produce false positives, though the researchers argue this still provides useful learning signals since intermediate steps are often correct.
The reported improvements are measured against previous UI-TARS versions and selected baselines, making direct comparisons with other systems potentially difficult due to differences in evaluation protocols. Finally, while parameter interpolation provides an efficient way to combine specialist models, it remains unclear whether joint multi-domain training might yield better results given sufficient computational resources.
Looking Forward
UI-TARS-2 represents a significant step toward practical computer-use agents by combining realistic testing environments, self-improving data pipelines, and stable reinforcement learning techniques. The system demonstrates consistent improvements across demanding benchmarks that test real-world computer use scenarios, from web browsing and mobile interactions to desktop operations and game playing.
Beyond the performance results, the research contributes valuable engineering patterns that other teams can adopt: stateful testing environments, asynchronous training architectures, and outcome-based verification systems.
Two approaches for scaling these systems stand out from this work. Parameter interpolation offers an efficient way to combine specialist models without expensive retraining, while hybrid reinforcement learning that trains a single policy across multiple interfaces provides more direct knowledge transfer. Both strategies have merit, with the former optimizing for computational efficiency and the latter maximizing learning transfer.
For researchers and practitioners interested in building similar systems, the UI-TARS codebase provides a solid foundation (UI-TARS; UI-TARS-desktop). For those focused on evaluation, benchmarks like Online-Mind2Web and LMGame-Bench offer more rigorous testing than traditional static evaluation suites ((Xue et al., 2025); (Hu et al., 2025)). The key insight from this research is clear: building robust computer-use agents requires robust training environments and careful engineering of the learning process itself.
Definitions
Online-Mind2Web: A live web evaluation of 300 tasks across 136 sites with an automatic judge calibrated to human ratings ((Xue et al., 2025)).
OSWorld: Desktop OS agent benchmark with execution-based evaluation scripts across Windows, Ubuntu, and macOS; widely used in computer-use agent research ((Xie et al., 2024)).
GUI-SDK: An extended action space that augments GUI clicks/keys with terminals, files, and tool calls; used to evaluate information-seeking and software engineering tasks in the paper.
Outcome Reward Model (ORM): A learned judge that predicts task success from trajectories and screenshots to supply scalar rewards when ground-truth verifiers are not available.
Decoupled/Length-Adaptive GAE: Variants of generalized advantage estimation that reduce bias/variance issues in long sequences by tuning λ for the policy and value heads and adapting λ to sequence length.
Parameter Interpolation: A post-training merge of specialist checkpoints via convex combination of weights to recover cross-domain competence without joint RL.


UI-TARS-2: Scaling GUI-Centered Agents With Multi-Turn RL
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning