As language models quickly catch up with and surpass traditional benchmarks, the need for more effective measurement tools becomes urgent. TextArena steps in as an innovative, open-source platform that evaluates Large Language Models (LLMs) through a wide array of competitive, text-driven games. This approach moves away from static, saturated tests and toward live, relative assessments offering a more dynamic and actionable way to gauge and improve LLM capabilities.
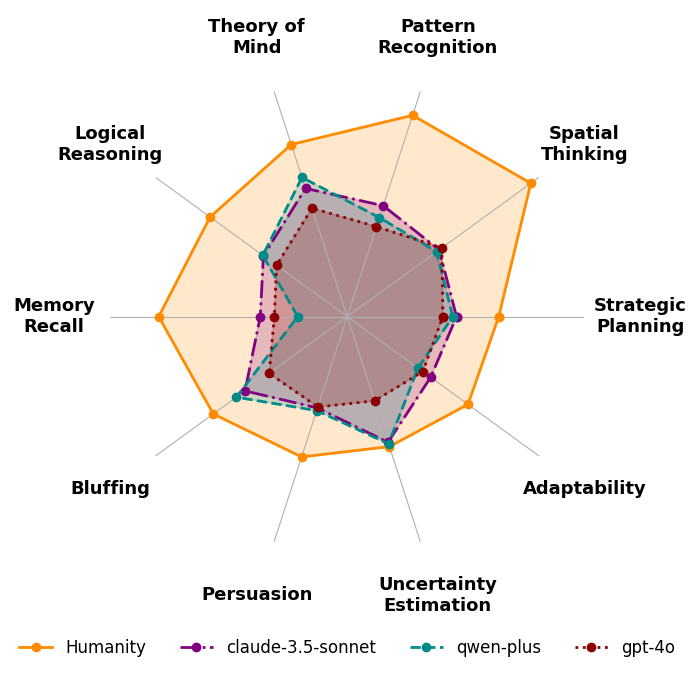
Figure 1: TextArena Soft-skill comparison. Frontier models and Humanity are compared across ten key skills. Each skill is normalized separately for presentation; see the leaderboard for full data. Credit: Paper
What Sets TextArena Apart?
- Dynamic Competition: Unlike conventional benchmarks, TextArena uses the TrueSkill™ system to rank models and humans in real time. This enables continuous comparison, letting researchers see how LLMs stack up as both the models and the platform evolve.
- Soft Skill Evaluation: Traditional metrics often miss vital social and cognitive abilities. TextArena specifically assesses skills like theory of mind, persuasion, bluffing, and adaptability crucial for agentic, human-like AI.
- Expansive Game Library: TextArena’s collection has grown from 57 to 74 games, encompassing single-player, two-player, and multi-player formats. Each game is tagged by targeted skills such as reasoning, memory, and strategy, giving a rounded profile of each model’s abilities.
- Granular Profiling: Researchers can drill down into specific strengths and weaknesses by analyzing scores from skill-tagged games. This level of detail allows for targeted improvements, even among similarly performing models.
- Boosting Training: With built-in support for reinforcement learning and self-play, TextArena isn’t just about assessment, it’s a robust source of training data for developing more advanced, multi-turn reasoning in LLMs.
- Community-Driven Evolution: As an open-source framework, TextArena invites contributions from the AI community. This collaborative model ensures the platform stays challenging and relevant as LLM technology advances.
The Problem with Old Benchmarks
Models like GPT-4o, Claude, and Gemini have scored near-perfectly on established benchmarks such as MMLU and HumanEval. As a result, these tests can no longer differentiate between state-of-the-art systems. Newer, harder benchmarks struggle to keep up with rapid AI progress, and as models reach or exceed human performance, human scoring becomes less practical.
TextArena overcomes these challenges by shifting to a relative leaderboard approach. As long as models differ, rankings remain meaningful, and ongoing competition keeps driving progress, something static benchmarks can’t offer.
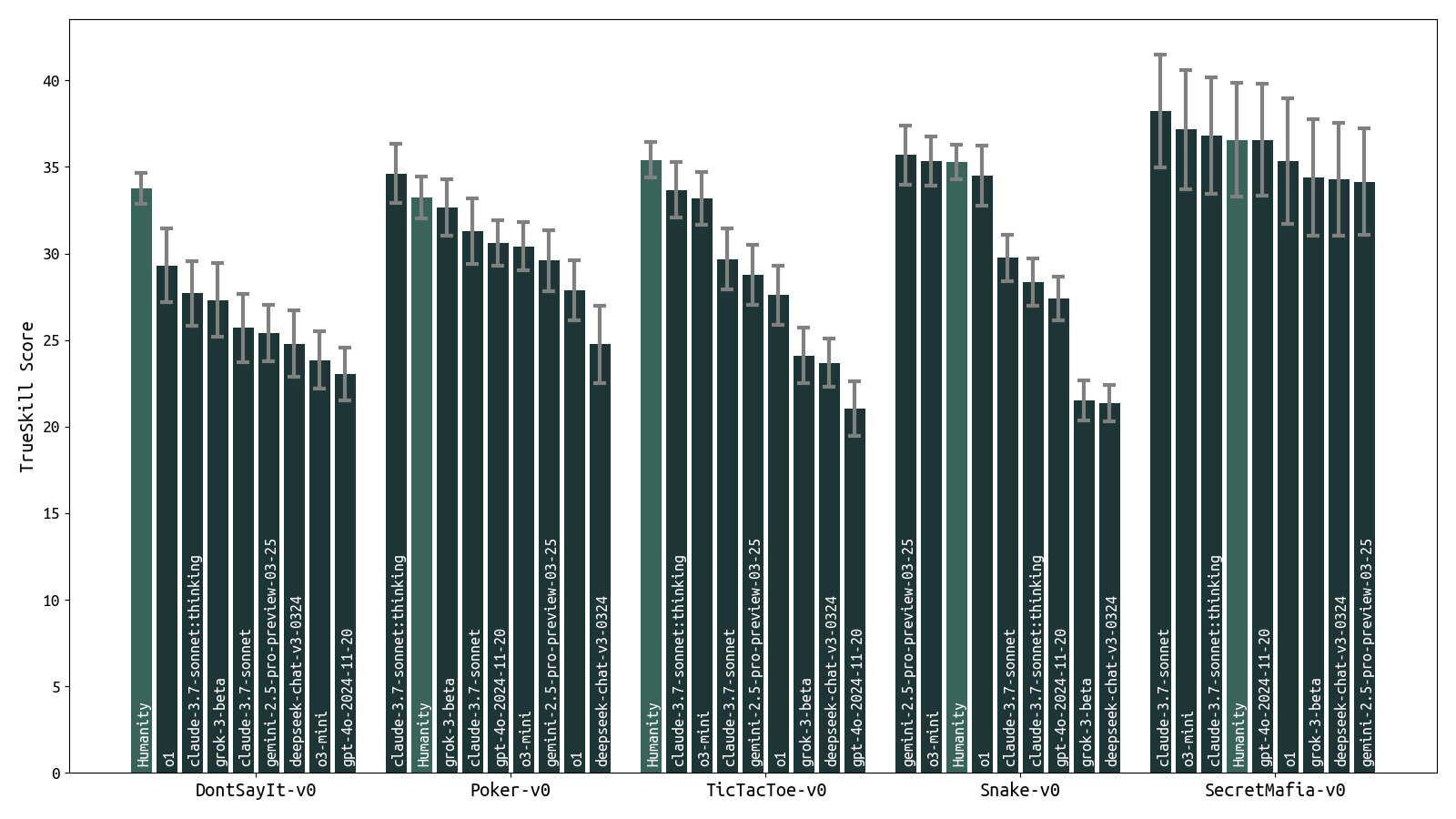
Figure 2: Preliminary model rankings for a subset of models and games. Game-play results are influenced by both the models’ ability to play the games and their ability to understand the rules and format. For example, some reasoning models can sometimes reveal their cards or roles during game-play. Credit: Paper
Real-World Impact: Experimental Insights
TextArena’s online system uses Bayesian TrueSkill™ ratings to monitor both human and AI performance across its many games. Early results reveal a clear trend: humans consistently outperform top LLMs in nuanced soft skills like persuasion and adaptability. Visualizations highlight that, even as LLMs excel in some areas, they still struggle with social awareness and strategic context.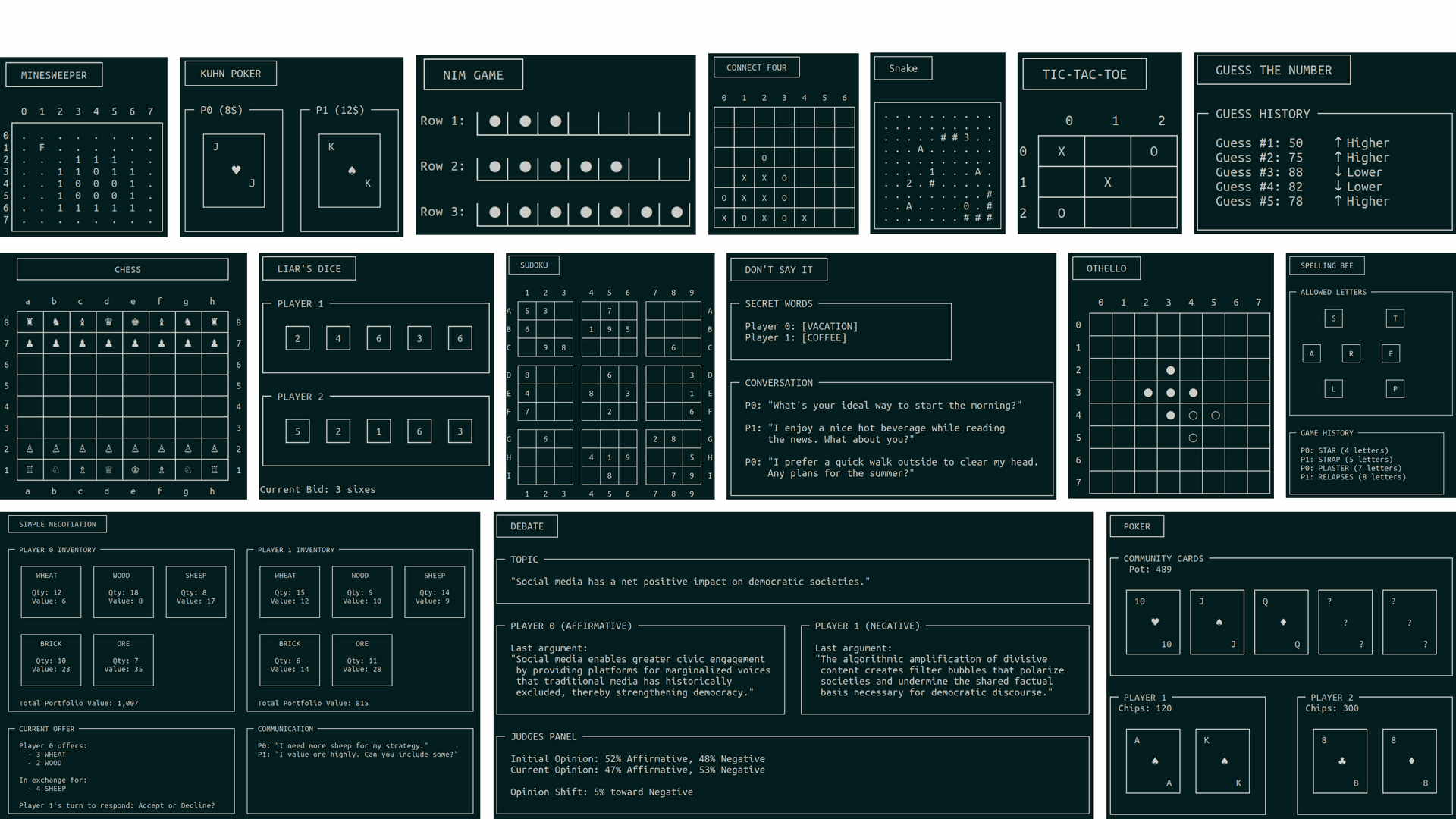
Figure 3: Images of some (rendered) TextArena environments. Credit: Paper
Game-specific analyses, such as in "Poker-v0" and "SecretMafia-v0", show that leading models can make contextually awkward decisions, exposing gaps in social intelligence. By scoring models across different skill domains, TextArena helps researchers pinpoint subtle differences that aggregate scores might miss, enabling more precise model development.
Accelerating the Next Generation of LLMs
TextArena is more than just an evaluation tool. Its integration with reinforcement learning pipelines means it can actively contribute to building more sophisticated, agent-like LLMs.
The platform’s growing library of skill-tagged environments offers diverse, multi-turn scenarios for both testing and training, helping to advance the very abilities most needed for real-world AI use.
By remaining open source and encouraging community input, TextArena adapts in step with AI advancements, ensuring ongoing relevance and challenge for the next wave of language models.
Conclusion
TextArena marks a pivotal shift in LLM evaluation, moving from static, one-size-fits-all benchmarks to a vibrant, competitive, and skill-based framework. Its unique focus on soft skills, detailed analysis, and community-driven growth positions it as a critical tool for both measuring and developing the complex abilities required for the future of agentic AI.


TextArena Uses Competitive Gameplay to Advance AI
TextArena