Introduction: The Dawn of Iterative Research AI
A groundbreaking paper from Google Cloud AI Research introduces Deep Researcher with Test-Time Diffusion (TTD-DR), a revolutionary research agent that fundamentally reimagines how AI systems approach complex research tasks.
Unlike traditional systems that follow rigid plan-search-write sequences, TTD-DR treats research report generation as an iterative diffusion-like process, where initial drafts are continuously refined through targeted retrieval and sophisticated self-evolution mechanisms.
This innovative approach emerges at a critical moment in AI research automation, as industry leaders race to develop increasingly sophisticated research agents. OpenAI's Deep Research emphasizes multi-step web browsing with advanced tool integration, while Perplexity's Deep Research mode focuses on iterative search and synthesis workflows.
TTD-DR distinguishes itself by introducing a principled architectural framework that combines draft-centric revision with retrieval-driven refinement and systematic self-improvement across all pipeline components.
The significance of this work extends beyond its impressive benchmark performance. By achieving win rates of 69.1% and 74.5% against OpenAI's Deep Research on long-form evaluations and demonstrating superior accuracy on complex multi-hop reasoning tasks, TTD-DR establishes new standards for what AI research agents can accomplish. More importantly, it provides a replicable framework that other researchers can build upon, contributing to the democratization of advanced research capabilities.
Key Takeaways
- Revolutionary Framework: TTD-DR introduces diffusion-style denoising for research report generation, treating initial drafts as "noisy" inputs that are iteratively refined through targeted retrieval.
- Dual-Component Architecture: The system combines (1) report-level denoising with retrieval guidance and (2) component-wise self-evolution for plans, questions, answers, and final reports.
- Superior Performance: Achieves 69.1% and 74.5% win rates against OpenAI Deep Research on long-form tasks, with higher correctness scores on HLE-Search (33.9% vs 29.1%), HLE-Full (34.3% vs 26.6%), and GAIA (69.1% vs 67.4%).
- Rigorous Evaluation: Employs calibrated LLM-as-a-judge methodology for long-form tasks and correctness metrics for short-form benchmarks, including Humanity's Last Exam and GAIA assessments.
- Current Limitations: Focuses exclusively on search tools without browsing or code execution capabilities, presenting opportunities for future enhancement.
The Diffusion Revolution in Research AI
The core innovation of TTD-DR lies in its adaptation of diffusion model principles to research synthesis. Traditional diffusion models start with random noise and iteratively refine it into coherent outputs (Ho, 2025). TTD-DR applies this same philosophy to research writing. Beginning with an initial "noisy" draft report and then progressively reducing uncertainty and incompleteness through cycles of retrieval, analysis, and revision.
Figure 1 | The method is inspired by the natural human writing process, which includes planning, drafting, and multiple revisions to the draft. Credit: Han et al.
This approach roughly mirrors how expert human researchers actually work. Rather than following a linear sequence of plan-execute-write, experienced researchers maintain evolving mental models of their topic, continuously updating their understanding as new evidence emerges. The diffusion framework captures this iterative refinement process, allowing the AI system to develop increasingly sophisticated and nuanced perspectives on complex research questions.
The technical implementation involves maintaining a living draft throughout the research process. At each iteration, the system generates focused search queries based on gaps or uncertainties in the current draft, retrieves relevant information, synthesizes findings into coherent answers, and then revises the draft to incorporate new insights. This creates a feedback loop where each piece of new evidence informs subsequent search strategies, leading to more targeted and effective information gathering.
Architectural Deep Dive: How TTD-DR Works
TTD-DR operates through a sophisticated three-stage architecture that seamlessly integrates diffusion-style refinement with systematic self-evolution.
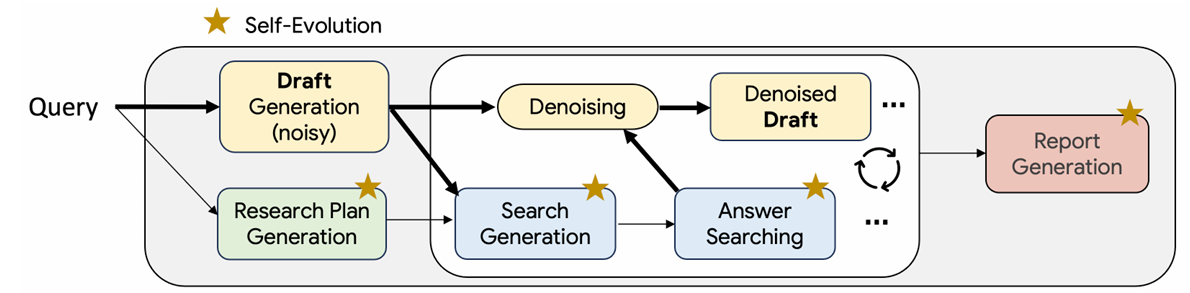
Figure 2 | Illustration of Test-Time Diffusion Deep Researcher (TTD-DR) framework, designed to mimic the iterative nature of human research through a draft. A user query initiates both a preliminary draft and a research plan. This evolving draft, along with the research plan, dynamically informs the generation of search questions and subsequent information retrieval to be timely and coherent, while reducing information loss. The retrieved information is then leveraged to denoise and refine the initial draft in a continuous feedback loop. The entire workflow is further optimized by a self-evolutionary algorithm to enhance the quality of the research plan, generated questions, answers, and the final report, demonstrating the synergistic power of diffusion and self-evolution in achieving superior research outcomes. Credit: Han et al.
- Stage 1 generates a structured research plan that serves as the skeleton for the final report. This isn't a static outline but a dynamic framework that evolves based on emerging insights during the research process.
- Stage 2 implements the core diffusion loop, alternating between generating targeted search questions and synthesizing retrieved evidence into coherent answers. Unlike traditional RAG systems that simply append retrieved content, TTD-DR actively integrates new information into the evolving draft, maintaining global coherence while deepening specific aspects of the analysis. (Lewis, 2020)
- Stage 3 produces the final research report by synthesizing the refined plan with the accumulated question-answer pairs. The system maintains complete traceability throughout this process, ensuring that every claim in the final report can be traced back to specific sources and reasoning steps.
The self-evolution component operates in parallel across all stages, continuously improving the quality of intermediate outputs. Multiple candidate responses are generated for each component (plans, questions, answers), automatically evaluated for quality metrics like helpfulness and comprehensiveness, critiqued for potential improvements, and then revised. A sophisticated cross-over mechanism combines the strongest elements from different variants, promoting both diversity and quality in the research process.
The Competitive Landscape: How TTD-DR Compares to Leading Systems
The deep research AI landscape has exploded with innovation over the past year, creating a rich ecosystem of competing approaches and philosophies. Understanding how TTD-DR fits within this context illuminates both its unique contributions and the broader trajectory of research automation technology.
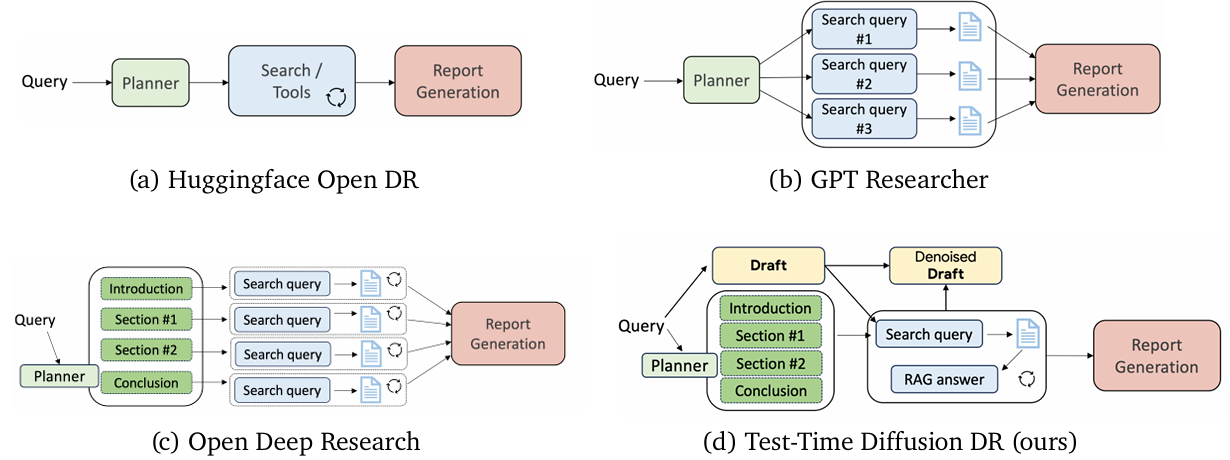
Figure 3 | A comparison of TDD method with other open-source deep researchers. (a) Huggingface Open DR (Roucher et al., 2025) utilizes a lightweight planner to determine subsequent actions, such as calling search or browse tools, and repeats these actions until an answer is found. (b) GPT Researcher (Researcher, 2025) also employs a lightweight planner to generate and execute multiple search queries in parallel before a generator synthesizes the retrieved documents into a report. (c) Open Deep Research (Research, 2025) uses a planner to outline the final report’s structure and then conducts iterative research for each section individually before combining them. (d) TTD-DR introduces a draft denoising mechanism. Unlike Open Deep Research, TTD-DR avoids separated searches for each section to maintain global context and uses a RAG-based answer generator to process retrieved documents before saving them for the final report generation Credit: Han et al.
OpenAI's Deep Research represents the current commercial gold standard, integrated directly into ChatGPT for millions of users. The system excels at multi-step web browsing, employing sophisticated tool use including Python code execution and real-time web interaction. However, its proprietary nature limits academic study and customization opportunities. TTD-DR's open research approach provides transparency into its methods while demonstrating competitive or superior performance across multiple evaluation frameworks.
GPT Researcher has emerged as the leading open-source research automation platform, with over 23,000 GitHub stars and a thriving community. Its multi-agent architecture delegates different research aspects to specialized agents, creating clear separation of concerns. While effective for rapid deployment and straightforward research tasks, GPT Researcher's linear pipeline can miss opportunities for the iterative refinement that TTD-DR's diffusion approach naturally incorporates. The key difference lies in TTD-DR's ability to continuously refine research outputs rather than following a fixed sequence of operations.
LangChain's Open Deep Research achieved impressive results on the Deep Research Bench leaderboard, ranking #6 with an overall score of 0.4344. Their implementation leverages LangGraph for workflow orchestration and supports multiple LLM providers. However, LangChain's approach requires significant boilerplate code and complex state management. TTD-DR's more integrated design offers cleaner abstractions while achieving superior performance metrics.
Hugging Face's Open Deep Research contribution focuses on code-based agents that express actions in Python rather than JSON, achieving 55.15% performance on GAIA validation sets. Their emphasis on systematic, reproducible research processes aligns philosophically with TTD-DR's principled approach, though TTD-DR's diffusion framework provides more sophisticated control over the research evolution process.
Microsoft AutoGen offers a fundamentally different paradigm, emphasizing conversational multi-agent systems for complex problem-solving. With over 50,000 GitHub stars, AutoGen provides powerful tools for agent orchestration and collaboration. While not specifically designed for research tasks, its conversational approach to agent coordination shares conceptual similarities with TTD-DR's iterative refinement. However, TTD-DR's diffusion-based approach provides more systematic control over research quality and coherence.
CrewAI represents another significant player in multi-agent orchestration, offering both autonomous agent crews and precise workflow controls through their Flows system. With 38,000+ GitHub stars and enterprise-grade features, CrewAI excels in production environments. Their approach to combining autonomous collaboration with precise control resonates with TTD-DR's balance of systematic refinement and adaptive research strategies.
Performance Analysis: Breaking Down the Results
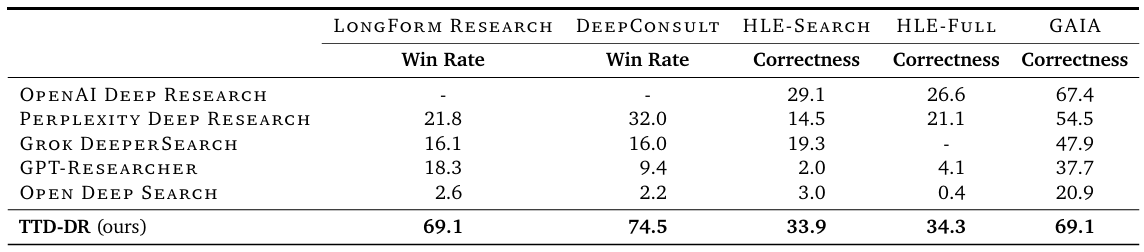
Table 1 | This table shows TTD-DR’s performances against different baseline systems for LongForm Research, DeepConsult, HLE and GAIA datasets. Win rate (%) are computed based on OpenAI Deep Research. Correctness is computed as matching between system predicted and reference answers. For Grok DeeperSearch on HLE-full, there is no public number provided, and we are not able to scrape the full 2K queries due to research budget and Grok DeeperSearch’s daily scrape limits. Credit: Han et al.
The empirical evaluation of TTD-DR reveals impressive performance gains across multiple research domains and task types. For example on long-form research tasks, the system achieved win rates of 69.1% on LongForm Research and 74.5% on DeepConsult when compared head-to-head with OpenAI's Deep Research. These results are particularly significant because long-form research represents the most challenging application of AI research agents, requiring sustained coherence, comprehensive coverage, and sophisticated synthesis capabilities.
The performance on short-form correctness tasks provides additional validation of TTD-DR's capabilities. On HLE-Search, which focuses on questions requiring search capabilities, TTD-DR achieved 33.9% accuracy compared to OpenAI Deep Research's 29.1%. This 4.8 percentage point improvement demonstrates the effectiveness of the diffusion-based refinement process for complex, multi-hop reasoning tasks.
Particularly noteworthy are the results on GAIA (General AI Assistants benchmark), where TTD-DR scored 69.1% compared to OpenAI's 67.4%. GAIA is specifically designed to evaluate real-world assistant capabilities, requiring sophisticated tool use and reasoning across diverse domains. The improvement on this benchmark suggests that TTD-DR's approach generalizes well beyond controlled research scenarios to practical applications.
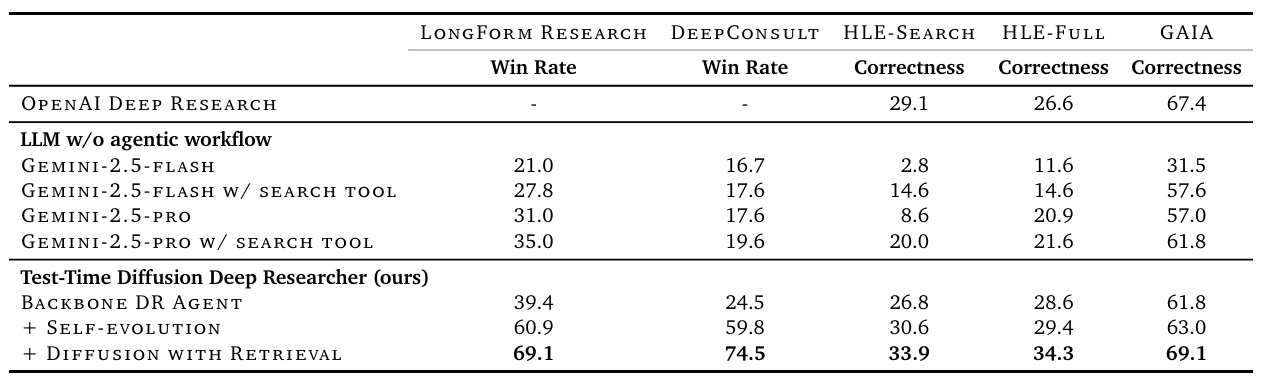
Table2 Credit: Han et al. ablation study of DR Agent’s performances across all benchmark datasets.
The ablation studies provide crucial insights into which components drive performance improvements. Base language models (Gemini-2.5-flash/pro) without agentic workflows significantly underperformed. Adding simple search tools improved results but still trailed proprietary baselines. The backbone Deep Research Agent narrowed the gap considerably, but the real breakthroughs came from adding self-evolution and diffusion-with-retrieval components. This progression demonstrates that TTD-DR's superior performance stems from the synergistic combination of its architectural innovations rather than any single technique.
Technical Innovations and Methodological Contributions
TTD-DR introduces several novel technical contributions that advance the state of the art in research automation. The denoising-with-retrieval mechanism represents a fundamental departure from traditional research pipelines. Instead of following predetermined search strategies, the system dynamically adjusts its information-seeking behavior based on the evolving state of the research draft. This creates a more responsive and adaptive research process that mirrors expert human behavior.
The component-wise self-evolution algorithm addresses a critical limitation in many existing systems. That is the tendency to generate suboptimal intermediate outputs that cascade into poor final results. By implementing separate improvement cycles for plans, questions, answers, and reports, TTD-DR ensures that each component reaches a high-quality threshold before contributing to the overall research process.
The cross-over mechanism for merging strong variants represents a sophisticated approach to maintaining diversity while promoting quality. Rather than simply selecting the highest-rated candidate, the system intelligently combines complementary strengths from different options, leading to more robust and comprehensive research outputs.
The calibrated evaluation framework addresses the challenging problem of assessing research quality at scale. By calibrating LLM-as-a-judge systems to human preferences for long-form tasks, the researchers created a more reliable and scalable evaluation methodology. This contribution extends beyond TTD-DR itself, providing a valuable tool for the broader research community.
Implications and Future Directions
The implications of TTD-DR extend far beyond the immediate performance improvements it demonstrates. The framework represents a new paradigm for human-AI collaboration in knowledge work, where AI systems become true research partners rather than simple information retrieval tools. This has profound implications for academic research, business intelligence, policy analysis, and numerous other domains that rely on systematic investigation and synthesis.
The current limitations of TTD-DR also point toward exciting future directions. The system's focus on search tools, while enabling controlled evaluation, leaves significant room for enhancement through integration of web browsing, code execution, and multimodal capabilities. Future versions could potentially match or exceed the tool diversity of systems like OpenAI's Deep Research while maintaining the systematic refinement advantages of the diffusion approach.
The success of TTD-DR's evaluation methodology suggests broader applications for calibrated LLM-as-a-judge systems in research assessment. This could revolutionize how we evaluate not just AI research systems but human research outputs as well, providing more consistent and scalable quality assessment mechanisms.
Perhaps most significantly, TTD-DR's open research approach contributes to the democratization of advanced AI research capabilities. By providing detailed architectural descriptions and evaluation frameworks, the work enables researchers worldwide to build upon and improve these methods, accelerating progress across the entire field.
Conclusion: A New Chapter in AI-Powered Research
TTD-DR represents a significant milestone in the evolution of AI research agents, demonstrating that principled architectural innovations can achieve substantial performance improvements over existing state-of-the-art systems. The framework's success validates the power of iterative refinement approaches and provides a compelling template for future research automation systems.
The broader significance of this work lies not just in its technical achievements but in its contribution to our understanding of how AI systems can most effectively augment human intelligence in complex cognitive tasks. TTD-DR's approach of systematic, iterative refinement guided by domain knowledge provides a blueprint for developing AI systems that truly collaborate with humans rather than simply automating routine operations.
As the field of AI research automation continues to evolve rapidly, TTD-DR establishes new benchmarks for performance, methodology, and evaluation rigor. Its open research approach ensures that these advances benefit the entire research community, accelerating progress toward more capable and reliable AI research assistants.
The future of knowledge work increasingly involves AI systems that can conduct sophisticated research autonomously while maintaining the transparency and reliability that human decision-makers require.
References and Further Reading
Han et al. (2025). Deep Researcher with Test-Time Diffusion - The original TTD-DR paper from Google Cloud AI Research.
OpenAI (2025). Introducing Deep Research - Official announcement of OpenAI's Deep Research capabilities.
Wei et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models - Foundational work on reasoning enhancement in language models.
Mialon et al. (2023). GAIA: A Benchmark for General AI Assistants - The GAIA benchmark used in TTD-DR evaluation.
GPT Researcher - Leading open-source research automation platform with 23,000+ GitHub stars.
LangChain Open Deep Research - LangChain's implementation achieving strong results on research benchmarks.
Hugging Face Open Deep Research - Community-driven implementation focusing on code-based agents.
Microsoft AutoGen - Multi-agent framework for collaborative AI systems with 50,000+ GitHub stars.
CrewAI - Production-ready multi-agent orchestration framework with enterprise features.
Deep Research Bench Leaderboard - Comprehensive benchmark for evaluating research automation systems.

google-research
Organization


Test-Time Diffusion for Deep Research: How Google's Breakthrough Approach Revolutionizes AI-Powered Research
Deep Researcher with Test-Time Diffusion