Introduction: The High Cost of AI Reasoning
Training large language models (LMs) to reason like humans is one of the biggest challenges in AI today. The current state-of-the-art method, reinforcement learning (RL), has proven effective but comes with significant drawbacks. Researchers Edoardo Cetin, Tianyu Zhao, and Yujin Tang from Sakana AI introduce a novel framework that addresses these challenges head-on.
The core problem with traditional RL is what's known as the "exploration problem": for an LM to learn, it must already have some initial ability to solve a problem to receive a learning signal. This makes it incredibly difficult and expensive to train models on complex reasoning tasks from scratch.
The most powerful reasoning LMs are often used as "teachers" to distill their knowledge into smaller, more efficient "student" models. This process is itself costly, requiring massive models and extensive, heuristic-driven post-processing of the teaching data.
The Sakana AI team argues that this entire paradigm is inefficient. Why train a teacher to solve problems from scratch when its real job is to explain existing solutions effectively? This insight led them to develop Reinforcement-Learned Teachers (RLTs), a new class of models trained specifically to be excellent educators.
Key Takeaways
- A New Framework for Training Reasoning LMs: The paper introduces Reinforcement-Learned Teachers (RLTs), a novel approach that sidesteps the "exploration problem" in traditional RL.
- Teaching, Not Just Solving: Instead of being tasked with solving problems from scratch, RLTs are given both the question and the solution and are trained to generate the most effective step-by-step explanation.
- Dense Rewards for Better Explanations: RLTs are trained with a dense reward function that measures how well a "student" model understands the explanation, leading to higher-quality teaching data.
- Smaller Models, Bigger Results: A 7-billion-parameter RLT was shown to produce better distillation results than much larger models (like the 671B DeepSeek-R1) that rely on traditional, expensive training and post-processing pipelines.
- Efficient and Reusable: RLTs are not only more efficient to train but are also highly reusable. They can effectively teach larger student models and can be applied to new, out-of-distribution tasks with zero-shot transfer, outperforming direct RL in some cases.
- Democratizing AI Reasoning: This new framework has the potential to significantly lower the cost and complexity of training powerful reasoning models, making advanced AI more accessible to a wider range of researchers and developers.
Why RLTs are a Big Deal
The RLT framework represents a significant step forward in the field of AI reasoning. By rethinking the role of the "teacher" model, Sakana AI has created a method that is not only more effective but also vastly more efficient. This has several important implications:
- Democratization of AI: By drastically reducing the cost and complexity of training reasoning models, RLTs could make this technology accessible to a much broader community of researchers and developers.
- More Powerful and Efficient Models: The ability to effectively distill knowledge from a small teacher to a large student opens the door to creating more powerful and specialized models with fewer resources.
- Increased Reusability: The zero-shot transfer capabilities of RLTs mean that a single teacher model could be used to create distillation datasets for a wide variety of tasks, saving significant time and computational resources.
The Old School: Why Traditional RL-based Teaching is Hard
To appreciate the innovation of RLTs, it's important to understand the limitations of the current approach. Traditionally, an LM is trained to reason using RL with a sparse reward system. The model is given a problem and generates a response. If the final answer is correct, it gets a positive reward; if not, it gets a negative one. This is the "one-hot correctness" reward system.
The problem is that for complex, multi-step reasoning tasks, the chances of stumbling upon the correct sequence of steps and the right answer are astronomically low for a model that isn't already highly capable. This is the exploration problem. The model rarely gets a positive reward, so it has very little signal to learn from. As a result, only massive, pre-existing models have shown significant improvement with this method.
Once these large models are trained, they are often used as teachers in a process called "supervised distillation." The teacher model generates reasoning traces (its "thinking process") for a set of problems, and these traces are used to train a smaller student model. However, the skills that make a model a good problem-solver aren't necessarily the same skills that make it a good teacher.
The reasoning traces from these models are often messy and require extensive, costly post-processing, sometimes involving other large, closed-source models, to be useful for a student. This makes the entire process inefficient and expensive.
The RLT Revolution: A New Way to Teach
The Sakana AI team flipped the problem on its head. Instead of asking the model to solve a problem, they gave it the solution from the start. The RLT's task is not to find the answer but to "connect-the-dots" between the question and the answer with a clear, instructive, step-by-step explanation. This simple change completely avoids the exploration problem.
The magic of the RLT framework lies in its reward function, which is designed to evaluate the quality of the explanation. The reward is composed of two main parts:
- Student Understanding (rSS): This measures how well a student model can predict the correct solution after being shown the RLT's explanation. A higher score means the explanation was effective in conveying the necessary information.
- Logical Coherence (rKL): This uses KL-divergence to ensure that the explanation is a logical continuation of the question from the student's perspective. This prevents the RLT from "cheating" by simply repeating the solution in the explanation. It forces the explanation to be a series of logical steps that a student could follow.
By optimizing for this dense, two-part reward, the RLT learns to generate explanations that are not only correct but also genuinely instructive. This creates a high-quality distillation dataset without the need for expensive post-processing.
A Landscape of Reasoning Techniques: How RLTs Compare
The RLT framework, while novel, builds on a rich history of research aimed at enhancing LLM reasoning. Understanding this context helps to appreciate its unique contribution. The field has largely focused on making models better autonomous problem-solvers.
Techniques like those used for DeepSeek-R1 (DeepSeek AI, 2024) and OpenAI's o1 (OpenAI, 2024) represent the mainstream RL approach: training a model to generate a step-by-step chain of thought to arrive at a correct answer. These methods have proven powerful but are computationally intensive and grapple with the "exploration problem," where a model struggles to learn without a good starting point.
Other methods have focused on making this process more efficient and scalable. The STaR (Self-Taught Reasoner) method (Zelikman et al., 2022) introduced a bootstrapping process where a model learns from its own generated rationales. It generates an explanation, and if the answer is correct, it keeps the rationale for future training. This was a key step toward self-improvement.
Its successor, Quiet-STaR (Zelikman et al., 2024), generalized this by teaching the model to "think" at each step of text generation, making reasoning a more intrinsic part of the model's behavior.
Similarly, Satori (Chen et al., 2025) introduced a "Chain-of-Action-Thought" to help models internalize an autoregressive search process, making them better at self-reflection and exploring different strategies.
All these methods share a common goal: to create a better autonomous reasoner that can solve problems from scratch. RLTs take a different path.
The framework acknowledges that a key use case for powerful reasoning models is to be teachers for smaller models. For this purpose, the most critical skill isn't solving, but explaining.
By providing the solution upfront, RLTs sidestep the exploration problem and reframe the task as "given the answer, what is the best explanation?" This potentially makes the RL problem easier and directly optimizes for the creation of high-quality distillation data, a clever and pragmatic shift in perspective that yields impressive results.
The Proof is in the Performance: RLTs in Action
The researchers conducted a series of experiments to test the effectiveness of RLTs, and the results are pretty impressive. They compared students trained with a 7B RLT against those trained with much larger models and more complex distillation pipelines.
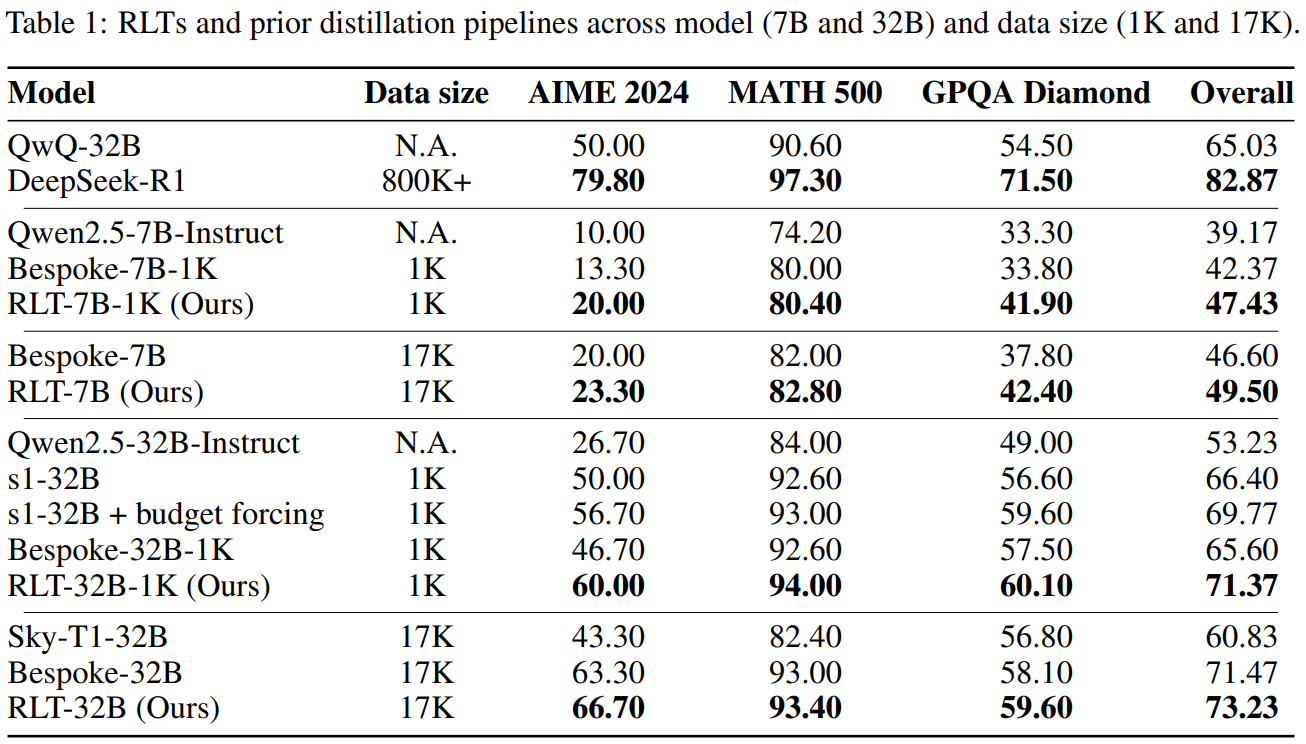
As shown in Table 1 of the paper, a student model trained on the raw outputs of a 7B RLT consistently outperformed students trained on the carefully post-processed reasoning traces of models like the 800K+ parameter DeepSeek-R1 and the 32B QwQ.
This was true across a range of challenging benchmarks, including AIME (American Invitational Mathematics Examination), MATH, and GPQA (Graduate-level Google-proof Q&A). Even when the student model was much larger than the RLT (a 32B student learning from a 7B teacher), the RLT-trained student still came out on top.
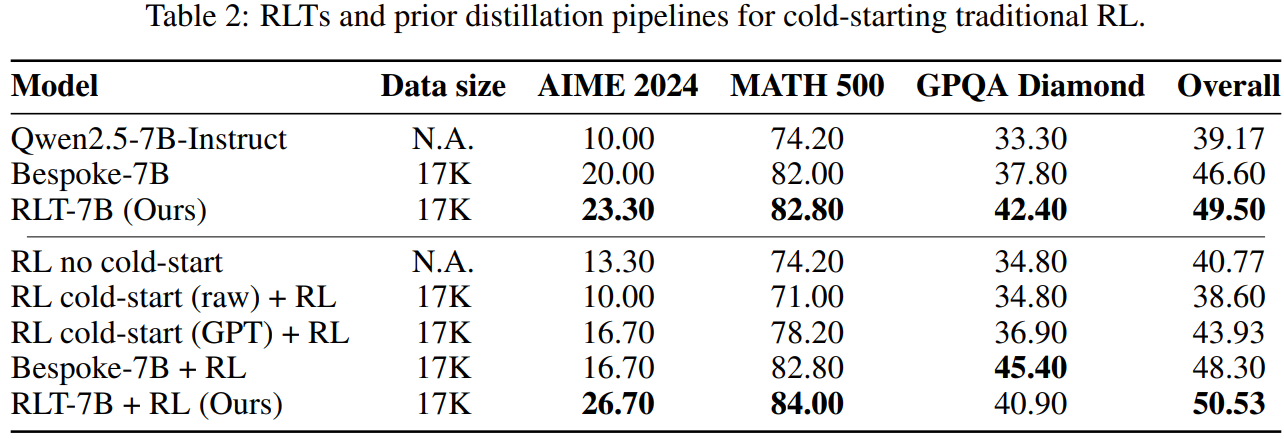
Table 2 demonstrates that RLTs are also superior for "cold-starting" traditional RL. A model pre-trained with RLT explanations provides a much better starting point for further RL training than models trained with other distillation methods.
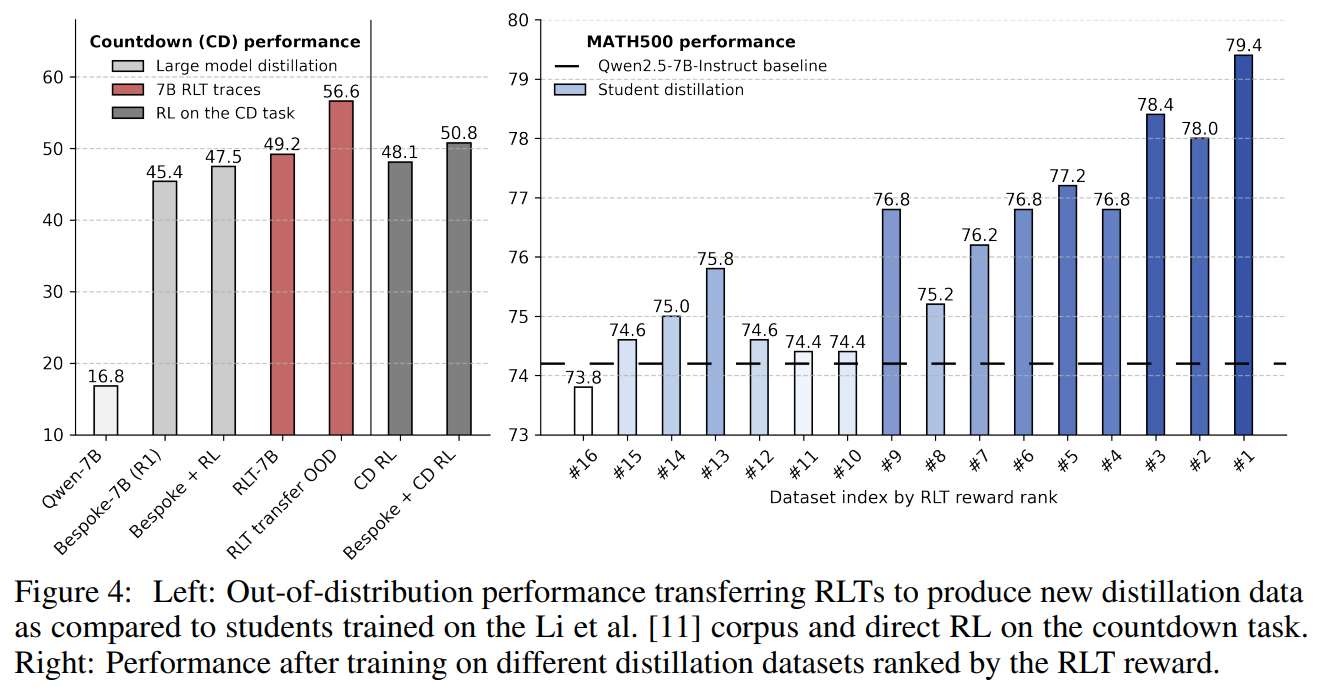
Perhaps the most striking result comes from the zero-shot transfer experiment, illustrated in Figure 4. The researchers tested the RLT on the "countdown" task, a problem it had never been trained on. The RLT was able to generate effective explanations for this new task, and the student trained on these explanations performed better than a model trained with direct RL on the countdown task itself. This suggests that the skill of creating good explanations is highly transferable.

A qualitative analysis, shown in Figure 5, reveals why RLT explanations are so much better. The RLTs produce more grounded, detailed, and logical explanations, even adding verification steps that larger models missed. In contrast, the reasoning traces from other models often contained artifacts from their training data or relied on external tools, making them less effective for teaching.
Dissecting the RLT Framework: What Makes it Work?
To understand why the RLT framework is so effective, the researchers conducted a series of ablation studies, which are detailed in Table 3 of the paper. These studies systematically removed key components of the RLT reward function to see how their absence affected performance. The results provide a clear picture of what makes the RLT model tick.
For these experiments, they trained entirely new 7B RLTs following the hyperparameters from Table 3 but setting λ = 0 (see Equation 5) or α = 0 (see Equations 4 and 3), respectively for the thought tokens KL reward and min/max reduction ablations.
The two main components of the reward function are Student Understanding (rSS) and Logical Coherence (rKL). The ablation studies showed that both are critical for success. When the Logical Coherence (rKL) term was removed, the RLT produced explanations that were less logical and harder for the student to follow, leading to a significant drop in performance. This confirms that simply providing a correct explanation is not enough; the explanation must also be logically sound from the student's perspective.
Similarly, when the Student Understanding (rSS) term was removed, the RLT was not as effective at generating explanations that were genuinely instructive. This highlights the importance of optimizing for the student's ability to learn from the explanation. The combination of both reward components is what makes the RLT framework so powerful. It ensures that the explanations are not only logically coherent but also tailored to be as helpful as possible for the student.
Background: Sakana AI and recent innovations
Sakana AI is a Tokyo-based research lab focused on nature-inspired approaches to foundation models and practical inference-time scaling. In the past year, the group has released a steady stream of research and systems that explore how to make models cooperate, self-improve, and transfer knowledge efficiently.
Highlights include evolutionary model merging, which combines existing models to create stronger ones (population-based quality-diversity search and merging) (Sakana AI, 2024; Sakana AI, 2024), the AI Scientist, a pipeline for automated end-to-end research (Sakana AI et al., 2024), an independent evaluation that outlines both promise and current limitations (Beel et al., 2025), TAID, an efficient transfer method for training small language models that received ICLR recognition (Sakana AI, 2025).
The team has also pushed on inference-time scaling and collective intelligence with AB-MCTS, coordinating multiple frontier models at test time (Sakana AI, 2025), proposed the Continuous Thought Machine to explicitly model time in neural computation (Sakana AI, 2025), introduced ALE-Bench and ALE-Agent for long-horizon algorithm engineering (Sakana AI, 2025), and released benchmarks like Sudoku-Bench to probe compositional reasoning (Sakana AI, 2025).
The group also maintains several public GitHub repositories that demonstrate their tooling and experimental code, including SakanaAI/AI-Scientist (the research pipeline and experiment orchestration) and SakanaAI/TinySwallow-ChatUI (a lightweight front-end and demos for small-model workflows). These repos provide practical examples and code for many of the systems referenced above.
Conclusion: A New Chapter in AI Education
"Reinforcement Learning Teachers of Test Time Scaling" is more than just an incremental improvement; it's a paradigm shift in how we think about training reasoning LMs. By focusing on the quality of teaching rather than just the ability to solve problems, Edoardo Cetin, Tianyu Zhao, and Yujin Tang have developed a framework that is more efficient, effective, and accessible. The RLT framework has the potential to accelerate progress in AI by making it easier to create the next generation of powerful, reasoning AI systems. As the paper suggests, there are many exciting future directions to explore, such as training teachers and students together in a dynamic, adaptive loop. One thing is clear: the future of AI reasoning may depend not just on how well our models can think, but on how well they can teach.



Teaching AI to Teach: Sakana AI's New Approach to Training Reasoning Models
Reinforcement Learning Teachers of Test Time Scaling