As AI coding agents approach human-level performance on existing benchmarks, the research community faces a critical challenge: how do we continue measuring progress when current evaluation suites are becoming too easy? This article analyzes SWE-Bench Pro, a substantially more challenging and contamination-resistant evaluation suite designed to address this exact problem.
SWE-Bench Pro builds on the foundation established by SWE-bench but targets enterprise-grade, long-horizon tasks that mirror real professional software development. Unlike simpler benchmarks that focus on single-file changes, these tasks often require multi-file modifications spanning 100+ lines of code. The dataset takes a sophisticated approach to data integrity by partitioning problems into three distinct subsets: public repositories with copyleft licenses, held-out evaluation sets, and commercial codebases sourced directly from private startup repositories.
The timing of this benchmark couldn't be more relevant. With resolution rates on SWE-bench-Verified now exceeding 70% for top systems, that benchmark's ability to differentiate between competing approaches has significantly diminished. SWE-Bench Pro reveals a stark reality: even the most advanced frontier models achieve Pass@1 resolve rates under
This performance gap aligns with broader trends in repository-level evaluation research ((Jimenez et al., 2024); (Xia et al., 2024); (Wang et al., 2024); (Yang et al., 2024)), suggesting that current agents still have substantial room for improvement when tackling complex, real-world software engineering challenges.
Key Takeaways
- SWE-Bench Pro focuses on enterprise-grade issues with multi-file, 100+ LOC patches and explicit human augmentation to reduce ambiguity while preserving technical difficulty.
- To mitigate training-set contamination, the public/held-out sets prioritize GPL and other copyleft repositories, and the commercial set draws from private startup codebases ((White et al., 2024) provides relevant background on contamination-resistant benchmarks).
- Frontier models reportedly achieve Pass@1 under
on the public set; the commercial set is even harder, indicating a sizable gap between current agents and professional software development demands. - Difficulty varies by language and repository; Python and Go fare relatively better than JavaScript/TypeScript, echoing patterns observed in prior cross-repo and cross-language studies ((Zan et al., 2024)).
- Trajectory analysis surfaces distinct failure modes across models: larger models more often miss on semantic/algorithmic correctness in large edits; smaller/open models show higher rates of syntax/tool-use and context-management errors ((Yang et al., 2024)).
Overview
The evolution from function-level to repository-level evaluation represents a fundamental shift in how we assess AI coding capabilities. While early benchmarks like HumanEval and MBPP focused on relatively short, standalone code snippets, SWE-Bench Pro is designed to reflect the reality of modern software engineering. Real-world development tasks require understanding complex interdependencies: build systems, dependency management, comprehensive test suites, and established code conventions that span multiple modules and programming languages.
SWE-bench originally established this repository-level evaluation paradigm for Python codebases ((Jimenez et al., 2024)), and subsequent research has expanded the approach across different languages and specialized domains ((Huang et al., 2023); (Zhuo et al., 2024)). SWE-Bench Pro builds on these foundations but introduces several key innovations to address emerging challenges in the field.
The benchmark's design centers on three complementary strategies.
- First, contamination resistance through careful repository selection, prioritizing GPL and other copyleft licenses for public datasets, while incorporating private commercial repositories that are definitively absent from training data.
- Second, complexity filtering that explicitly excludes trivial edits, ensuring that every task requires substantial, multi-file modifications.
- Third, a comprehensive human augmentation and verification pipeline that clarifies requirements and interfaces without compromising solution diversity or technical difficulty.
To ensure fair and reproducible evaluation, the researchers standardized their approach around containerized, language-specific environments with robust test stabilization procedures. This included filtering out flaky tests and validating proper fail-to-pass behavior.
For agent evaluation, they primarily relied on the SWE-Agent scaffold ((Yang et al., 2024)), noting that alternative approaches like Agentless ((Xia et al., 2024)) showed limitations with multi-file editing tasks. The evaluation protocol allows up to 200 agent turns, enables tool-use when supported, and maintains consistent prompting across all tested models.
Why It's Important
The influence of benchmarks on research direction cannot be overstated, they fundamentally shape how the field allocates resources and measures progress. As leading AI systems now routinely achieve over 70% success rates on SWE-bench-Verified ((OpenAI, 2024)), that benchmark's ability to distinguish between competing approaches has become severely limited.
This creates a critical need for evaluation suites that remain sensitive to meaningful improvements while being robust against the ever-present threat of training data contamination. SWE-Bench Pro addresses both challenges simultaneously by demanding larger code changes that span multiple files and requiring deeper repository understanding.
Meanwhile, its strategic use of copyleft licenses and private commercial repositories creates strong barriers against training data leakage ((Xu et al., 2024); (White et al., 2024)). This dual approach ensures that improvements measured on the benchmark likely reflect genuine advances in agent capabilities rather than memorization artifacts.
Perhaps most importantly, the commercial subset provides a reality check that's often missing from academic evaluations. Professional software engineering in enterprise environments involves much more than elegant, isolated solutions. It requires navigating legacy code, coordinating changes across multiple modules, maintaining comprehensive test coverage, adhering to established interfaces, and protecting against regressions that could affect thousands of users. The significant performance gap between public and commercial subsets in SWE-Bench Pro suggests that current agents still struggle with these messier, more constrained realities of production codebases.
Discussion
The results paint a sobering picture of current AI capabilities on complex SE tasks. On the public subset containing 731 problems, even the most advanced models struggle significantly, with frontier systems achieving Pass@1 resolve rates below
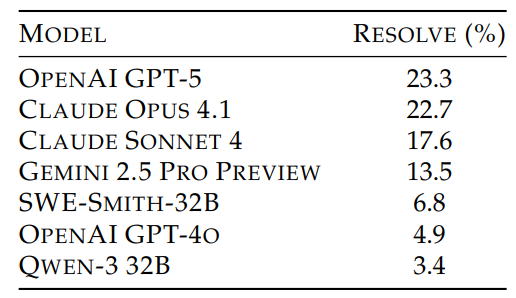
The paper's Table 1 (above) shows OpenAI's latest model and Anthropic's Claude Opus 4.1 leading the pack, followed by Claude Sonnet 4 and Gemini 2.5 Pro Preview. Open-weight models like Qwen 3 32B lag considerably behind, managing only low single-digit success rates.
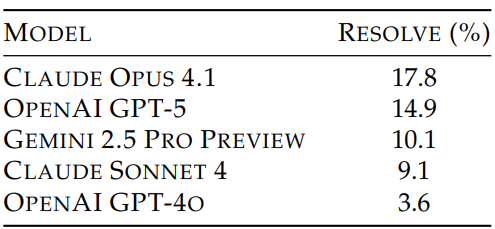
The commercial subset proves even more challenging, with only 276 problems but dramatically lower success rates across all models (Table 2 above), highlighting the substantial gap between academic benchmarks and real enterprise software complexity.
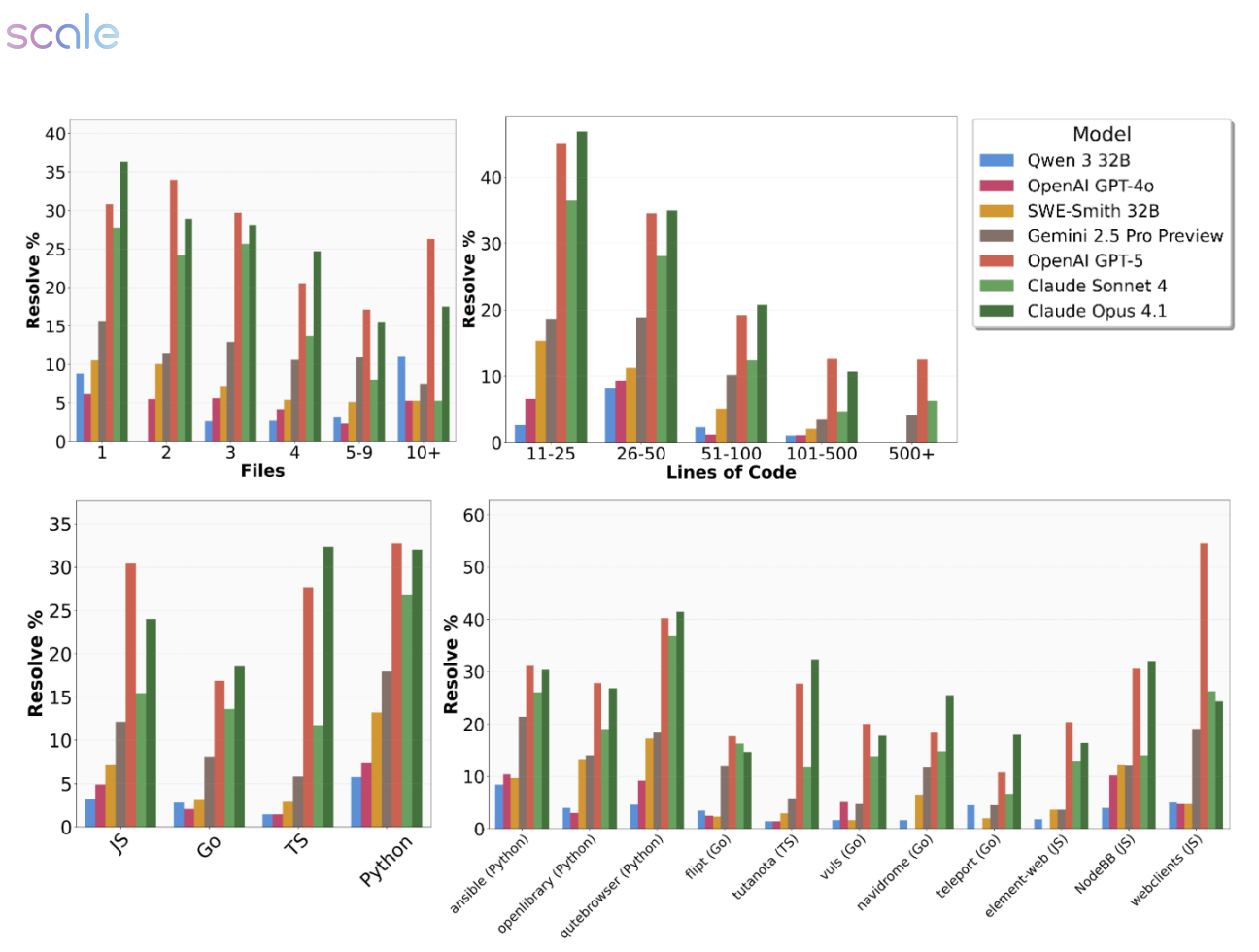
The data reveals significant variation in agent performance across different programming languages and repositories. According to Figure 4 (above), Python and Go generally prove more tractable for AI agents than JavaScript and TypeScript, while certain repositories consistently yield low resolve rates regardless of the model tested.
This pattern aligns with previous research showing that agent performance heavily depends on factors like ecosystem conventions, test coverage quality, and overall project architecture ((Liu et al., 2023); (Huang et al., 2023)). These findings suggest that agent capabilities aren't uniformly distributed across different technical contexts, some environments and languages may inherently favor current AI approaches.
Perhaps most illuminating is the detailed failure mode analysis conducted using an LLM-as-a-judge methodology ((Yang et al., 2024)). Table 3 reveals distinct patterns: larger, more sophisticated models primarily fail on semantic and algorithmic correctness, often producing elaborate but fundamentally incorrect solutions. In contrast, smaller and open-weight models struggle more with basic operational challenges such as syntax errors, tool-use problems, and context management issues like infinite loops or overflow conditions.
This divergence has important practical implications: addressing limitations in frontier models requires better verification systems and stronger test suites, while improving smaller models demands more reliable tool integration and enhanced context handling capabilities.
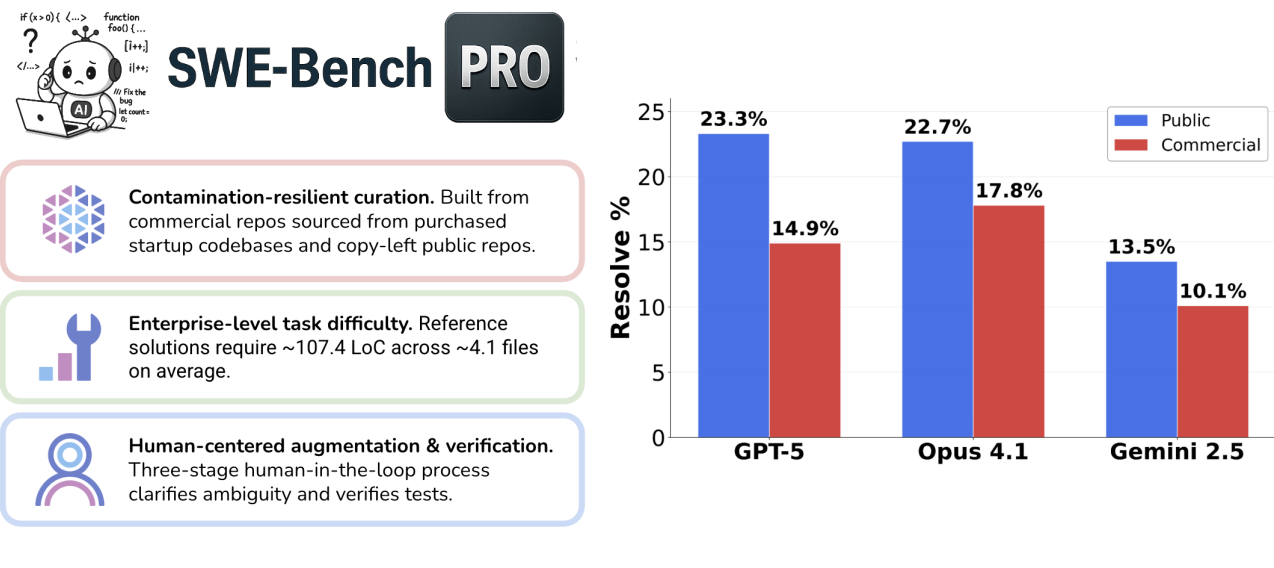
The paper's visual analysis reinforces these findings across multiple dimensions. Figure 1 effectively illustrates the performance gap between SWE-bench-Verified and SWE-Bench Pro, while
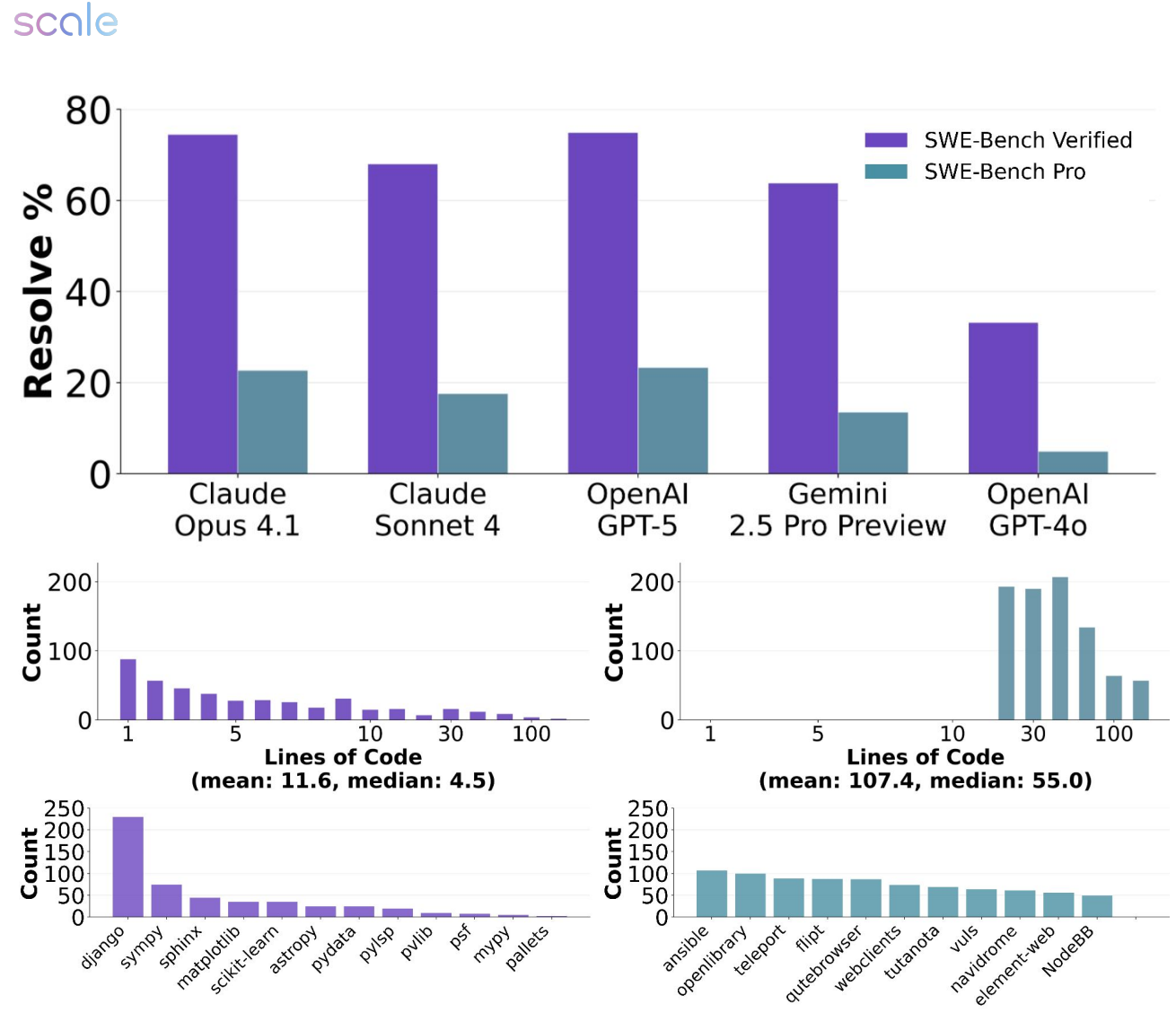
Figure 2: SWE-BENCH PRO is designed to mimic real, challenging software engineering tasks – with larger changes, across multiple files, sourced from professional software engineering repositories. Frontier models, such as GPT-5 and Claude Opus 4.1, score >70% of SWE-Bench Verified but less than 25% on SWE-BENCH PRO. Patches are generated with SWE-Agent [22] and evaluated on the public subset of SWE-BENCH PRO
Figure 2 demonstrates the complexity difference through patch size and multi-file modification requirements.
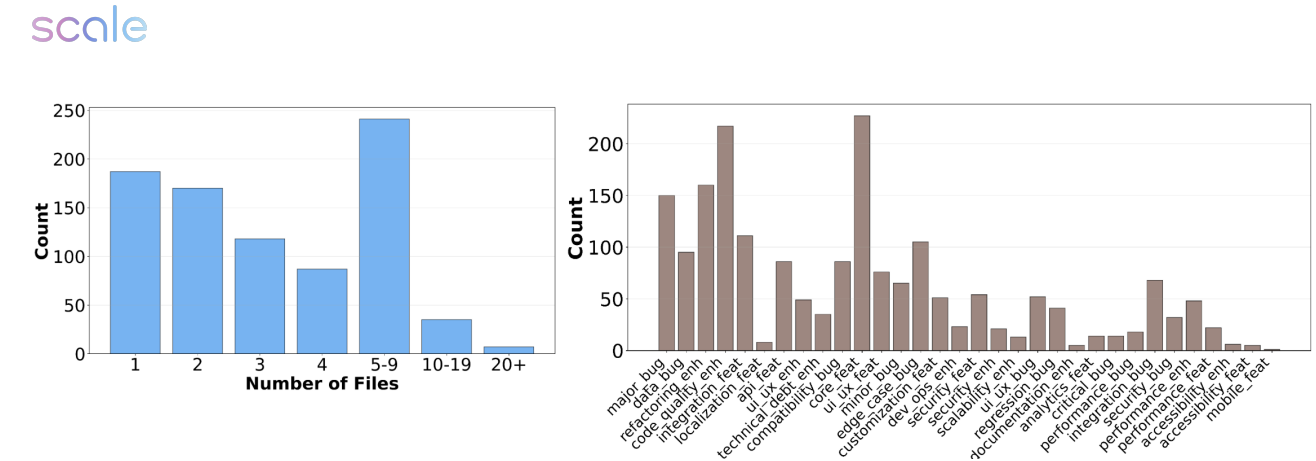
Figure 3 provides valuable insight into the benchmark's diversity, showing the distribution of task types across UI/UX improvements, backend modifications, optimization work, and security enhancements. When considered alongside the tabulated results, these visualizations strongly support the authors' central claim: SWE-Bench Pro captures a level of complexity that's both more challenging and more representative of professional software development than previous benchmarks.
The researchers acknowledge several important limitations that future work should address. The benchmark's language coverage remains imbalanced, with Java, C++, and Rust underrepresented compared to Python and JavaScript. The evaluation approach's reliance on test-based verification, while practical, may miss valid alternative solutions that don't conform to the original test expectations.
Additionally, the human augmentation process, despite its benefits in clarifying requirements, risks over-specifying tasks in ways that might not reflect the natural ambiguity present in real-world development scenarios. Ongoing research in multi-language evaluation, multimodal assessment, and performance-focused benchmarking ((Zan et al., 2024); (Yang et al., 2024); (He et al., 2025)) offers promising directions for addressing these constraints in future benchmark iterations.
Conclusion
SWE-Bench Pro represents a pivotal advancement in how we evaluate AI coding agents, fundamentally raising the bar for what constitutes meaningful progress in automated software engineering. Through its careful curation of contamination-resistant repositories, emphasis on complex multi-file modifications, and standardized evaluation infrastructure, the benchmark provides a rigorous and industry-relevant measuring stick that should remain valuable as the field advances.
The sobering performance results, with even frontier models achieving under
For practitioners building AI coding agents, these results provide clear guidance for future development priorities. The failure mode analysis reveals that different types of models require different improvement strategies: frontier models need better verification systems and algorithmic reasoning, while smaller models require more reliable tool integration and context management. As the field continues to mature, SWE-Bench Pro offers an essential benchmark for tracking progress toward truly autonomous software engineering capabilities that can handle the messy, constrained realities of professional development work.
Definitions
Pass@1: The proportion of tasks resolved by the first attempted solution; here, determined by repository test suites after applying the generated patch.
Contamination Resistance: Benchmark design choices that lower the chance that evaluation examples appeared in model training data (e.g., via copyleft licensing or private repositories). See discussions in ((Xu et al., 2024)) and ((White et al., 2024)).
Fail2Pass and Pass2Pass Tests: Tests that, respectively, should fail on the base commit but pass once the patch is applied, and tests that should continue to pass after the patch to prevent regressions.
Agent Scaffolds: Frameworks that structure tool actions, editing flows, and feedback loops for coding agents. Examples include SWE-Agent ((Yang et al., 2024)) and Agentless ((Xia et al., 2024)).


SWE-Bench Pro Sets A Higher Bar For AI Coding Agents
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?