A new paper from researchers at Hebrew University, OriginAI, and Bar-Ilan University introduces Story2Board, a training-free framework for generating multi-panel storyboards that keep characters recognizable while allowing composition, background, and pacing to evolve naturally.
The team builds on the strengths of modern diffusion transformers such as FLUX and Stable Diffusion 3 to produce storyboards that look more cinematic and less like static slideshows.
Story2Board addresses a gap in existing approaches, which often prioritize character identity at the expense of visual storytelling. Instead of heavyweight architectures or special training runs, the authors propose two simple, inference-time mechanisms that guide pretrained models toward consistency across panels while preserving the model's native expressiveness.
They also introduce a new benchmark and a metric to evaluate not just whether a character persists, but whether the scene evolves in meaningful, film-like ways.

Image Credit: David Dinkevich
Key Takeaways
- Two training-free mechanisms, Latent Panel Anchoring (LPA) and Reciprocal Attention Value Mixing (RAVM), deliver consistent characters and coherent scenes without model changes or fine-tuning.
- A lightweight prompt decomposition step uses an off-the-shelf LLM to convert a story into panel-level prompts, improving structure without prompt engineering.
- A new Rich Storyboard Benchmark evaluates layout diversity and background-grounded storytelling, expanding beyond identity-only metrics.
- A Scene Diversity metric quantifies variation in subject framing and pose across panels, aligning evaluation with cinematic goals.
- Compatible with state-of-the-art diffusion transformers (e.g., FLUX, SD3), enabling practical adoption in creative pipelines without training cost.
How Story2Board Works
The framework takes a short narrative and first asks a language model to split it into two components: a reference prompt that captures recurring characters or objects, and a sequence of panel-level prompts that describe distinct moments.
These prompts condition a pretrained text-to-image diffusion transformer through a two-part image layout per panel: a top reference sub-panel and a bottom target sub-panel, rendered jointly in the same latent grid. This creates a natural channel for cross-panel consistency during denoising without any architectural edits.
Latent Panel Anchoring (LPA) is the high-level glue. During joint denoising of the batched two-subpanel latents, the method repeatedly overwrites the top half of each latent with the top half of the first latent in the batch. That keeps a synchronized reference depiction alive across panels, letting the model's self-attention naturally carry textures and identity cues from the shared reference into each target panel.
As the authors observe, diffusion transformers cluster semantically similar tokens in key space, which encourages feature sharing for related regions such as hair, clothing, or facial features across panels.
Reciprocal Attention Value Mixing (RAVM) is the fine-grained stabilizer. After self-attention, the method identifies token pairs across the stacked reference and target sub-panels that mutually attend to each other strongly, then softly blends their value vectors with a mixing weight.
RAVM fixes the details while LPA maintains the global anchor. Since keys and queries (which drive spatial layout) are untouched, the method preserves composition while nudging appearance features (texture, color, micro-structure) toward consistency.
Crucially, both mechanisms operate purely at inference time and require no retraining. They complement the base model's strengths, rather than constraining it.
The authors demonstrate compatibility with diffusion transformers such as FLUX and document results with Stable Diffusion 3 as well. The pipeline's LLM "director" step is intentionally lightweight: it turns freeform story text into grounded panel prompts without hand-tuning.
Why This Matters
Storyboards rely on composition, spatial dynamics, background evolution, and narrative pacing. Many prior approaches center on identity preservation and can produce sequences where the subject is consistently front-and-center, with little variation in viewpoint, scale, or scene context.
Story2Board emphasizes cinematic storytelling: characters can be small or off-center when the moment calls for it; backgrounds can carry meaning; framing can change to communicate mood or scale. These are the levers filmmakers use, and they are what creative teams need from AI tools.
From a systems perspective, Story2Board is practical. It avoids training costs and preserves the base model's expressivity, making it easier to deploy in production pipelines.
For teams standardizing on open-weight models like FLUX or previewing SD3's DiT+flow-matching stack, this is a plug-in technique that can elevate multi-image outputs into coherent narratives. Because it targets token values and latent synchronization, it is also model-agnostic in spirit: no custom layers, masks, or reference adapters are required.

Figure 1: Story2Board generates coherent multi-panel storyboards from a natural language prompt, maintaining subject identity while allowing dynamic changes in character pose, size, and position. Unlike prior work, it introduces a lightweight consistency mechanism that preserves the model’s generative prior, supporting rich, expressive storytelling without fine-tuning or architectural changes. Full story texts are available in the appendix (Credit: David Dinkevich).
Results, Metrics, and Figures
Figure 1 shows a storyboard generated from a single prompt, where the same character appears across panels with different poses, sizes, and placements, while backgrounds evolve to convey story beats. This illustrates the core claim: consistency without sacrificing composition or atmosphere.

Figure 2. Figure 2: Comparative storyboard outputs from our method and two leading baselines, using the same input narrative. While baseline methods tend to center the character in every frame with limited variation in framing or environment, our method leverages cinematic principles–such as exaggerated scale, dynamic perspective, and environmental context–to convey narrative progression more expressively. Note, for instance, how the small scale of the character in the third panel of the top row enhances the sense of vastness of the tower of bones, reinforcing the emotional arc of the story. (Credit: David Dinkevich).
Figure 2 compares Story2Board with prior systems and highlights a recurring failure mode elsewhere: a tendency to center the subject and repeat layouts across frames, yielding slideshow-like sequences. In contrast, Story2Board varies framing and leverages environmental context to support the narrative.
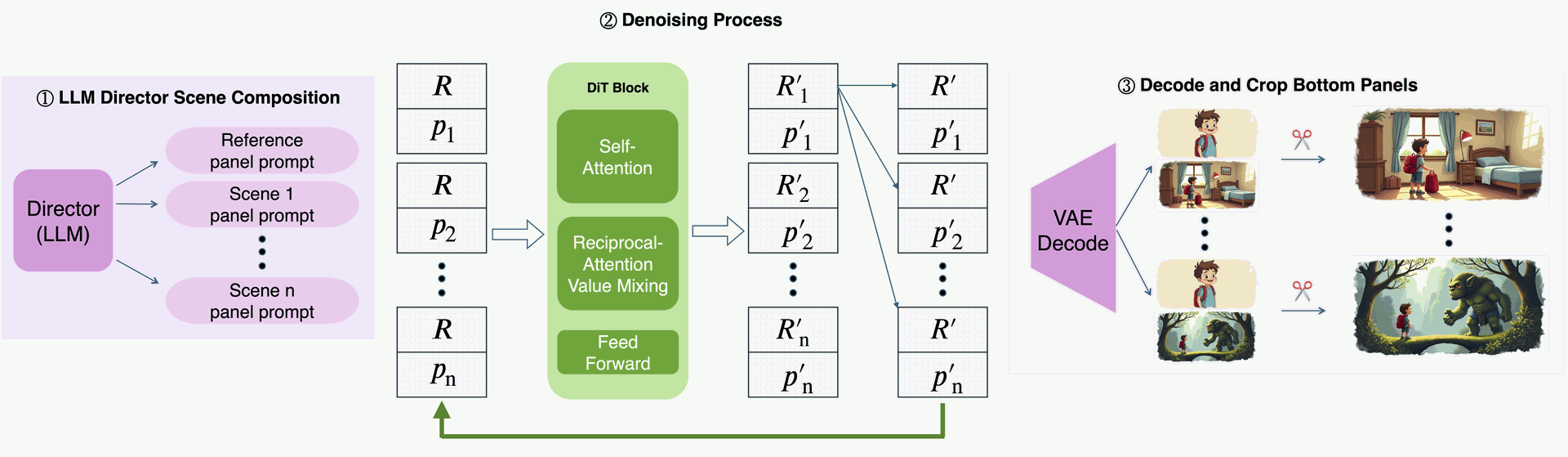
Fig. 3. Our training-free storyboard generation pipeline. (1) LLM Director: Decomposes the story into a shared reference panel prompt and scene-level prompts. (2) Co-denoising with LPA and RAVM: Generates a batch of two-panel images, syncing the reference panel across the batch after each DiT block and blending features for consistency. (3) Decode & crop: Produces the final storyboard panels. Credit: David Dinkevich
Figure 3 diagrams the pipeline. The two-subpanel latent structure (top reference, bottom target) enables Latent Panel Anchoring during denoising, while RAVM runs inside each transformer block to gently share appearance features between mutually attentive cross-panel token pairs.

Fig. 4. Visualization of Reciprocal Attention Value Mixing (RAVM) in action. Left: A generated two-panel output from our method, with the top panel serving as the shared reference. The red and green circles mark semantically corresponding character features (the hand) in the reference and target panels, respectively. Right: Heatmaps showing reciprocal attention scores at denoising step 12 of 28. Top-right: For each token in the top panel, we compute its reciprocal attention with the green-circled token in the bottom panel. Bottom-right: The reverse--each token in the bottom panel is scored based on reciprocal attention with the red-circled token in the top panel. In both cases, the hand token in the opposite panel receives the strongest reciprocal attention, showing that RAVM identifies semantically aligned token pairs for value mixing. This reinforces visual consistency without altering spatial composition. Credit: David Dinkevich
Figure 4 visualizes RAVM's reciprocal attention maps and shows that semantically corresponding regions (e.g., a hand) reliably find each other across panels, validating the mechanism behind the value mixing step.
To move evaluation beyond identity-only metrics, the paper introduces the Rich Storyboard Benchmark, a collection of 100 open-domain stories, each decomposed into seven scene-level prompts. It stresses layout flexibility and background-grounded storytelling, not just subject persistence.
The authors also propose a Scene Diversity metric that measures how dynamically the subject is framed across panels, combining variation in bounding-box scale/position and pose keypoints when applicable. The approach leverages established vision tools for detection and pose estimation, such as Grounding DINO and ViTPose.
Quantitatively, the paper reports performance tradeoffs using prompt alignment and identity consistency axes. Prompt alignment is measured using VQA-style evaluation, and identity consistency with DreamSim, a perceptual metric trained to better match human judgments of similarity.
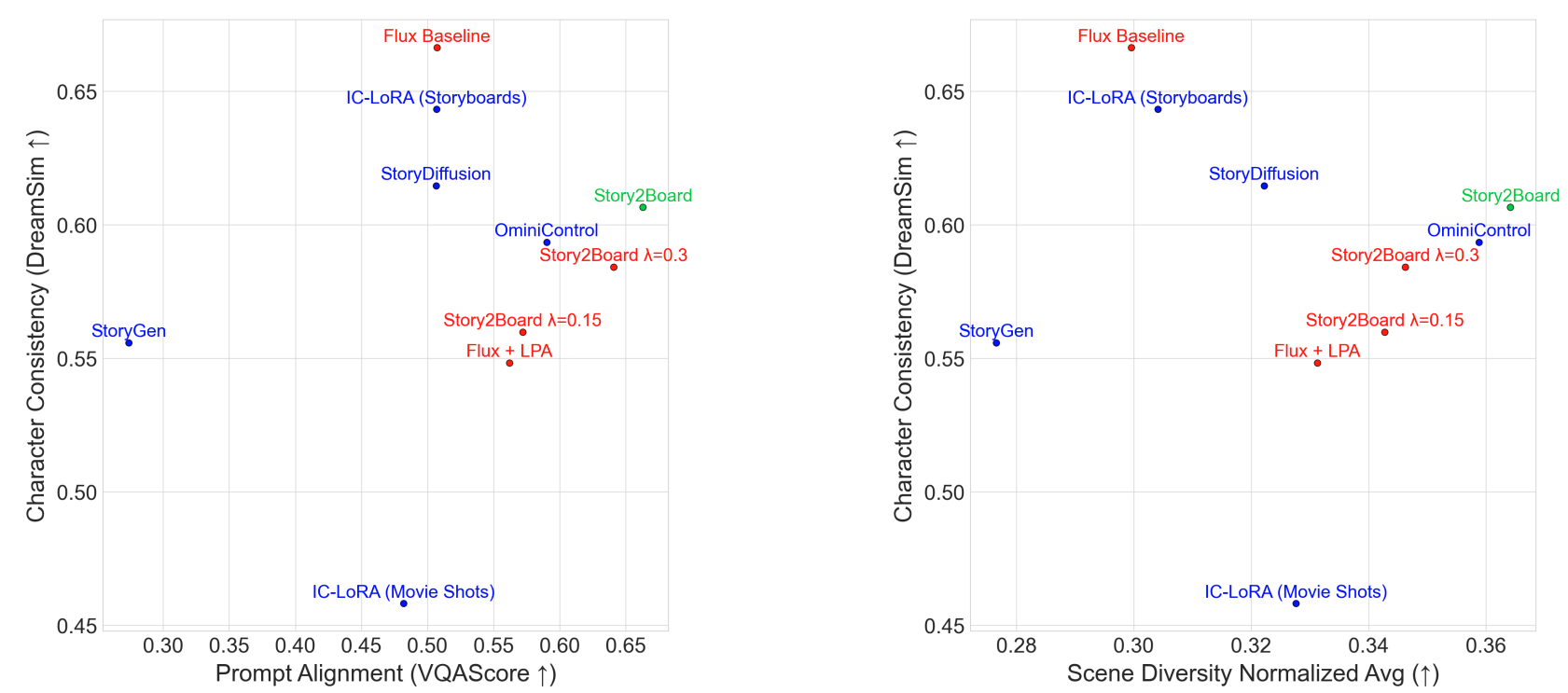
Figure 6: Left: Character Consistency vs. Prompt Alignment. Story2Board achieves the best tradeoff, outperforming all baselines and ablations. Prompt alignment (x-axis) is measured via VQAScore and character consistency (y-axis) via DreamSim. The Flux baseline exhibits unusually high consistency due to its collapsed behavior–rendering similar characters across panels with minimal pose or appearance variation–yet struggles with prompt grounding. Right: Scene Diversity vs. Character Consistency. Our method maintains high identity fidelity while enabling significantly more layout variation than competing methods. Scene Diversity (x-axis) is our proposed metric (details in supplementary), while character consistency (y-axis) is again measured via DreamSim. Note that IC-LoRA baselines (Movie Shots and Storyboards) operate only on 4-panel sequences and are not applicable to longer formats. Credit: David Dinkevich
In the plots (Figure 6), Story2Board sits on the Pareto frontier, achieving a favorable balance between alignment and consistency, while maintaining higher scene diversity than baselines like StoryDiffusion or tuned IC-LoRA variants.
A user study on Mechanical Turk further supports the qualitative claim: while some methods may edge out in individual sub-metrics, overall preference consistently favored Story2Board.
The limitations section is refreshingly candid because the method rides on native attention dynamics of the base model, it can propagate underlying attention entanglement when the model confuses attributes between entities.
Context and Related Work
Story2Board lands at the intersection of consistent multi-image generation and narrative visualization.
- Prior systems like StoryDiffusion add architectural modules to enforce cross-frame consistency and motion prediction.
- DreamStory combines an LLM "director" with multi-subject diffusion, introducing a benchmark (DS-500) focused more on identity coherence across short prompts.
- IC-LoRA shows that small, task-specific LoRA updates can unlock in-context generation for DiT models.
- OminiControl introduces minimal conditioning for DiTs to achieve broad control tasks with tiny parameter overhead.
- Story2Board differs by requiring no training and by explicitly optimizing for cinematic composition and scene diversity in addition to identity.
On the model side, diffusion transformers like FLUX and the SD3 family blend transformer backbones with diffusion or flow-matching training to scale text-to-image generation with strong prompt grounding and quality.
Story2Board leverages these advances directly, intervening only during sampling to rebalance the classic tension between consistency and expressivity.
Conclusion
Story2Board is a pragmatic step toward better story visualization. By anchoring a shared reference and mixing value features between semantically aligned tokens, it achieves consistent characters without flattening composition or suppressing stylistic diversity.
The Rich Storyboard Benchmark and Scene Diversity metric push evaluation to reflect real creative goals, not just subject repetition. For teams that already rely on state-of-the-art diffusion transformers, the appeal is clear: no training, minimal complexity, and outputs that look more like film storyboards and less like static slides.
Readers can explore examples and updates on the project page, and the arXiv paper provides additional ablations, user study details, and extended qualitative comparisons (Dinkevich et al., 2025).
References
Key sources used inline: Dinkevich et al., 2025 (Story2Board); Black Forest Labs, 2025 (FLUX); Stability AI, 2024 (Stable Diffusion 3); Zhou et al., 2024 (StoryDiffusion); Huang et al., 2024 (IC-LoRA); Tan et al., 2025 (OminiControl); He et al., 2025 (DreamStory); Fu et al., 2023 (DreamSim); Oquab et al., 2023 (DINOv2).


Story2Board: Training-Free Storyboards With Cinematic Consistency
Story2Board: A Training-Free Approach for Expressive Storyboard Generation