Researchers from Shanghai Jiao Tong University’s Institute of Parallel and Distributed Systems, the School of Artificial Intelligence, and Zenergize AI introduced SmallThinker: a family of large language models (LLMs) designed from the ground up for local deployment (Song et al., 2025).
Unlike most LLMs, which are built for cloud-scale GPU clusters and only later adapted for edge devices, SmallThinker is natively architected to thrive on consumer hardware, laptops, smartphones, and embedded systems, where memory, compute, and storage are limited. The project’s open-source models and inference engine are available on Hugging Face and GitHub.
Key Takeaways
- Native local-first design: SmallThinker is built for edge devices, not retrofitted from cloud models.
- Two-level sparsity: Combines fine-grained Mixture-of-Experts (MoE) and sparse feed-forward networks (FFN) to minimize compute and memory use.
- Pre-attention routing: A novel router predicts which experts are needed before attention, enabling prefetching and hiding storage latency.
- NoPE-RoPE hybrid attention: Reduces key-value (KV) cache size while preserving long-context performance.
- State-of-the-art efficiency: With Q4_0 quantization, SmallThinker models run at >20 tokens/sec on CPUs, using just 1GB (4B) or 8GB (21B) RAM.
- Open-source and reproducible: Models, code, and datasets are available for research and deployment.
Rethinking LLMs for the Edge: An Overview
Most LLMs, like GPT-4, Gemini, or Claude, are engineered for massive data centers, then compressed or distilled for local use. This often means trading away accuracy or capability. SmallThinker rejects this concept. Instead, it treats local device constraints as design principles, not obstacles.
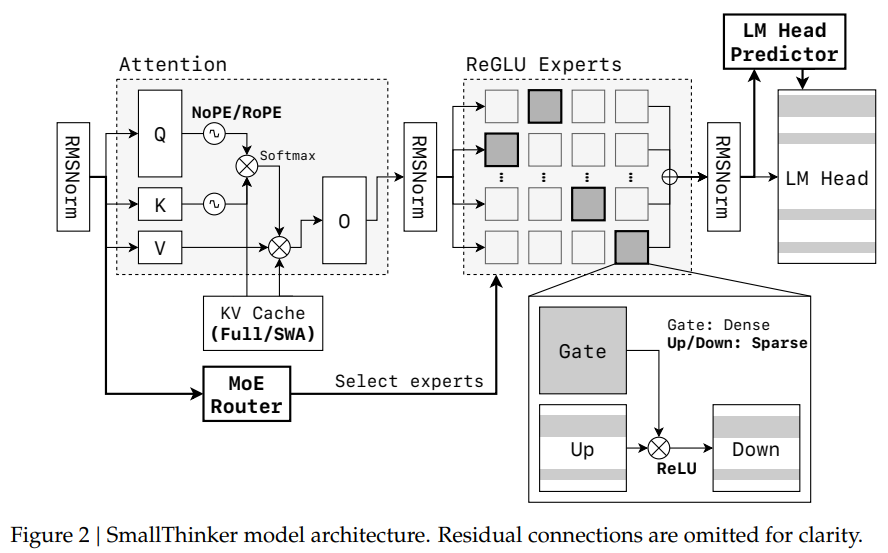
The core innovations include:
- Fine-grained Mixture-of-Experts (MoE): Each model (4B and 21B) is split into many “experts” (32 or 64), but only a small subset is activated per token. This drastically reduces the number of parameters in use at any time, saving compute and memory.
- Sparse ReGLU-based FFN: The feed-forward networks within each expert use the ReGLU activation, which induces high neuron-level sparsity, over 60% of neurons are inactive even when an expert is routed. This further cuts computation.
- Pre-attention router: By placing the MoE router before the attention block, the system can predict which experts will be needed and prefetch their weights from storage while attention is computed. This hides the latency of slow SSDs or flash memory, a major bottleneck on local devices.
- NoPE-RoPE hybrid sparse attention: Alternates between global attention layers (NoPE) and sliding window attention with rotary embeddings (RoPE), reducing the size of the KV cache needed for long-context inference.
- DP-Groups Global Load Balance Loss: Encourages expert specialization within data-parallel groups, enabling predictable “hot” experts that can be cached in fast memory, while “cold” experts are offloaded to slower storage.
These architectural choices are paired with a co-designed inference engine, PowerInfer, which fuses sparse FFN kernels, implements expert prefetching, and supports quantized models for both CPU and GPU.
The result: SmallThinker-21B-A3B and SmallThinker-4B-A0.6B can run at over 20 tokens/sec on ordinary CPUs, with memory footprints of 8GB and 1GB, respectively.
Why SmallThinker Matters
By designing for local constraints, SmallThinker enables private, responsive, and universally accessible AI, without the need for insecure cloud connectivity or expensive GPUs. This is crucial for privacy-sensitive applications, offline use, as well as democratizing access to advanced language models.
The innovations in sparsity, expert routing, and memory management are not just engineering tricks, they represent a new way to think about model architecture.
The predictable activation patterns of experts allow for efficient caching and prefetching, while the hybrid attention mechanism balances context length with memory use. These ideas could influence future LLMs across domains, from mobile devices to embedded systems and beyond.
Results: Performance, Figures, and Tables
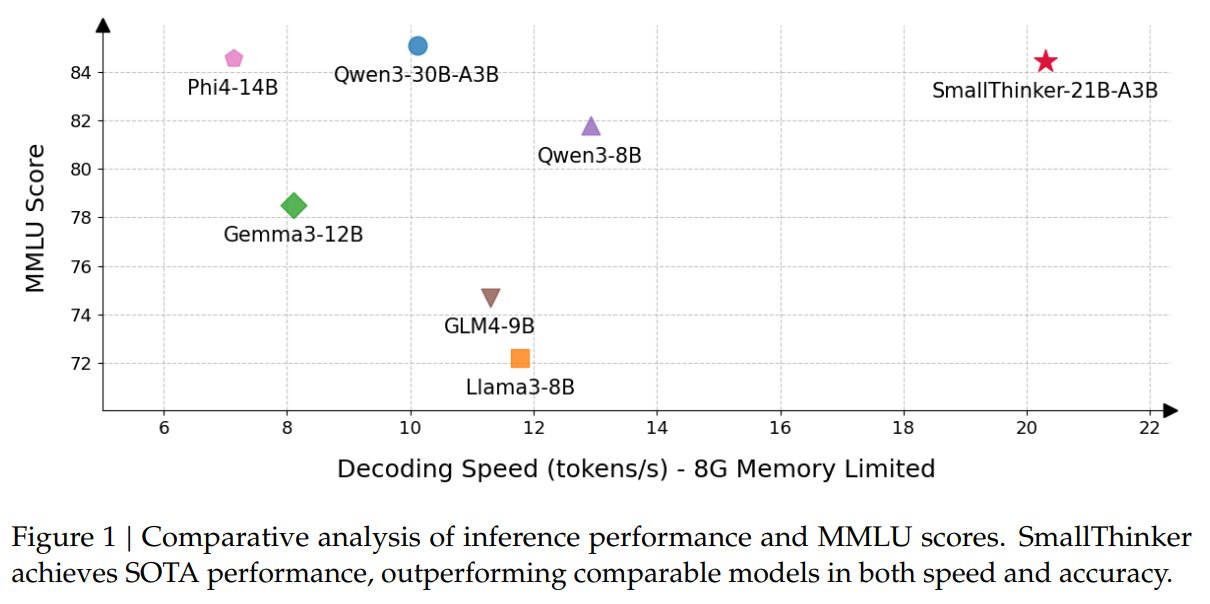
Figure 1 compares inference speed and MMLU accuracy across models. SmallThinker outperforms comparable models in both speed and accuracy, achieving state-of-the-art (SOTA) results for its size class.
Table 1 summarizes the architectures:
Model Layers Hidden FFN Heads Experts Top K
SmallThinker-4B-A0.6B 32 1536 768 12 32 4
SmallThinker-21B-A3B 52 2560 768 28 64 6
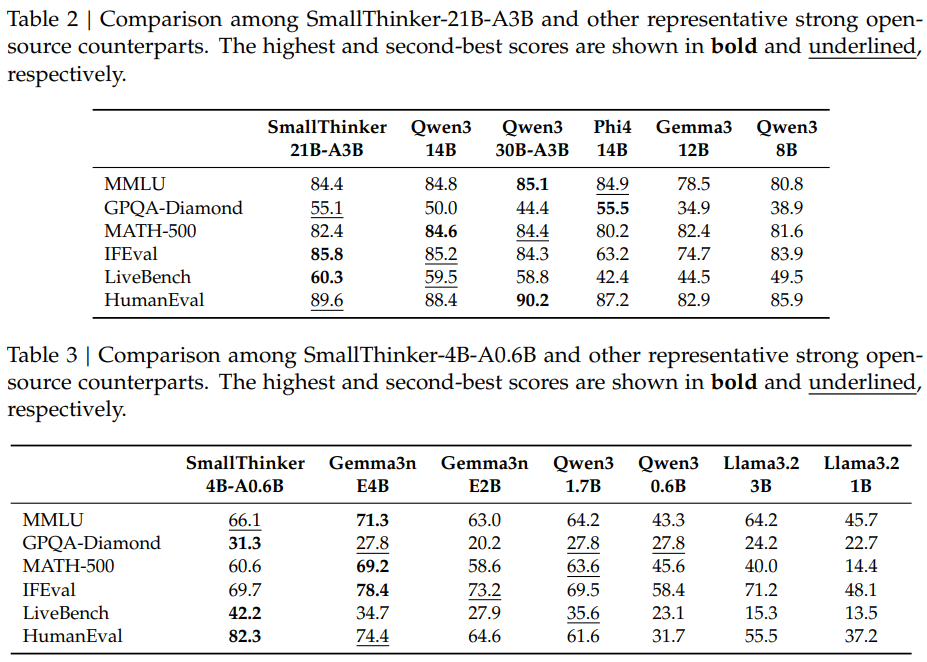
Table 2 and Table 3 benchmark SmallThinker against leading open-source LLMs (Qwen3, Gemma3, Llama3.2, Phi-4). On MMLU, GPQA-Diamond, MATH-500, IFEval, LiveBench, and HumanEval, SmallThinker-21B-A3B matches or exceeds the performance of much larger models, while SmallThinker-4B-A0.6B leads its class in efficiency and accuracy.
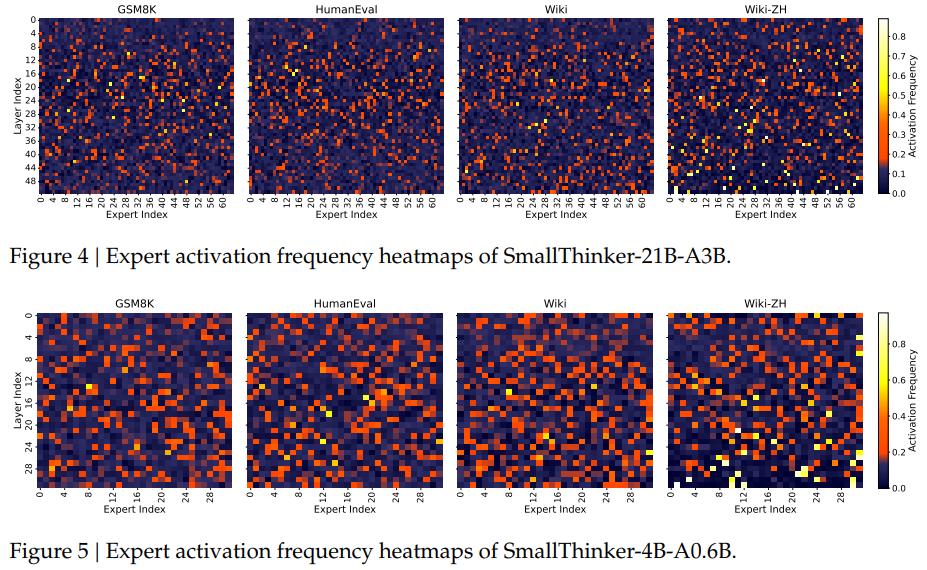
Figure 4 and Figure 5 (not shown) display expert activation heatmaps, revealing that only a small, predictable subset of experts are frequently used—enabling effective caching. Figure 6 shows neuron-level sparsity, with over 60% of neurons inactive in most layers, confirming the effectiveness of the ReGLU-based design.
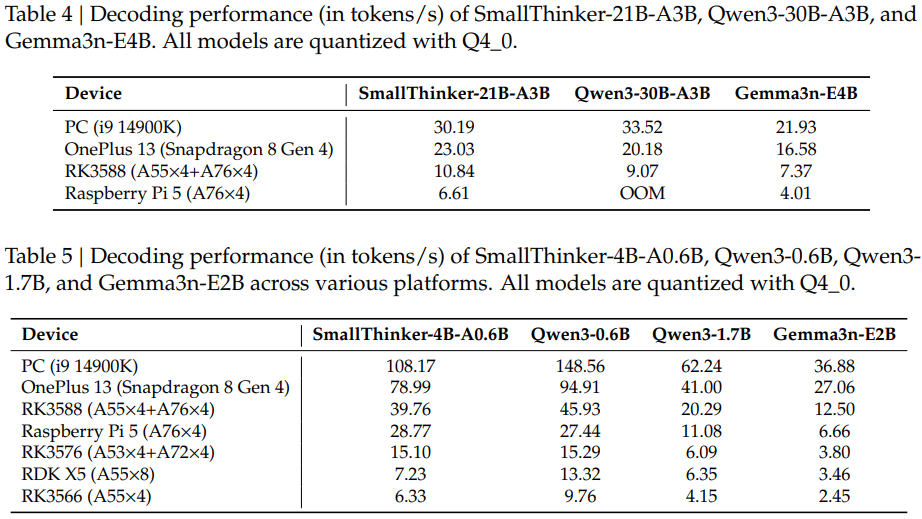
Table 4 and Table 5 report decoding speeds (tokens/sec) on various devices. For example, SmallThinker-21B-A3B achieves 30.19 tokens/sec on a PC (i9-14900K), 23.03 on a OnePlus 13, and 6.61 on a Raspberry Pi 5—all without a GPU. Even with strict memory limits (8GB for 21B, 1GB for 4B), SmallThinker maintains high throughput, outperforming Qwen3 and Gemma3n models in offloading scenarios.
All models are available in quantized Q4_0 format, and can be run using the PowerInfer engine. Example code for inference with transformers is provided in the Hugging Face model cards.
Discussion of Results
The results presented in the SmallThinker paper highlight not only strong benchmark performance, but also real-world usability for local AI applications. On standard academic tasks such as MMLU, GPQA-Diamond, MATH-500, IFEval, LiveBench, and HumanEval, SmallThinker-21B-A3B consistently matches or outperforms much larger models, including Qwen3-30B-A3B and Gemma3-12B.
This is particularly notable given that SmallThinker activates far fewer parameters per token, demonstrating the effectiveness of its sparse MoE and FFN design. The 4B-A0.6B variant also leads its class, outperforming models like Qwen3-1.7B and Llama3.2-3B in both accuracy and efficiency.
Perhaps most impressive is SmallThinker’s ability to maintain high throughput and accuracy under strict memory constraints. Even when limited to 8GB (21B) or 1GB (4B) of RAM, the models deliver fast inference speeds and robust results, thanks to innovations like expert prefetching and hybrid attention.
This means that advanced LLM capabilities are now accessible on consumer hardware, enabling private, offline, and low-latency AI for a wide range of users. The open-source release of both models and the PowerInfer engine further supports reproducibility and adoption in research and industry.
Conclusion: Limitations and Next Steps
SmallThinker demonstrates that it is possible to deliver high-quality LLM performance on local devices, without the compromises of post-hoc compression. However, the authors note that their pretraining corpus is smaller than those used for the very largest models, which may limit knowledge breadth.
Additionally, SmallThinker has not yet been aligned with Reinforcement Learning from Human Feedback (RLHF), so its instruction-following may lack some nuance and safety guarantees.
Future work will focus on scaling up pretraining data and implementing RLHF alignment. For now, SmallThinker stands as a compelling proof-of-concept for local-first LLMs, and a valuable resource for researchers and developers interested in efficient, private, and accessible AI.
Read the full paper on arXiv, try the models on Hugging Face, and explore the inference engine on GitHub.



SmallThinker: Bringing Powerful Language Models to Local Devices
SmallThinker: A Family of Efficient Large Language Models Natively Trained for Local Deployment