Scientific claim verification and reproducibility have emerged as a critical challenges in the era of information abundance and multimodal AI systems. Unlike traditional fact-checking that relies primarily on textual evidence, scientific claims often require synthesizing information from interconnected modalities: textual descriptions, data tables, and visualizations like charts and graphs. This multimodal nature reflects how scientists actually communicate findings in research papers, where conclusions are supported through diverse evidence types working in concert.
The field builds upon foundational work in claim verification, including the widely-used (FEVER benchmark, 2025) for fact extraction and verification, and domain-specific efforts like (SciFact, Wadden et al., 2020) that focused on scientific abstract verification.
However, these earlier benchmarks typically isolate modalities or limit scope to specific document sections, missing the integrated reasoning that characterizes real scientific literature comprehension.
The paper (Wang et al., 2025) introduces SciVer, the first benchmark specifically designed to evaluate multimodal scientific claim verification across complete papers. Curated by experts across 1,113 computer science papers, SciVer comprises 3,000 examples with supporting evidence annotations for fine-grained analysis.
The authors evaluate 21 models including o4-mini, GPT-4.1, Gemini-2.5-Flash, Llama-3.2-Vision, and Qwen2.5-VL, revealing substantial gaps to human expert performance, particularly on complex reasoning that requires cross-referencing multiple modalities. The dataset and code are available at (HuggingFace, 2025) and (GitHub, 2025).
Key Takeaways
- Benchmark scope: 3,000 expert-annotated examples across 1,113 papers; four reasoning subsets (Direct, Parallel, Sequential, Analytical).
- Evaluation breadth: 21 multimodal models tested; accuracy substantially below human experts (approx. 94 percent human vs. best models around 70 to 78 percent).
- Evidence-first: Each example includes supporting evidence pointers (paragraphs, tables, charts), enabling targeted error analysis.
- RAG helps: Retrieval-augmented settings improve accuracy; higher-quality retrieval yields larger gains.
- Top failure modes: missed evidence, visual misreads, brittle multi-step reasoning, over-reliance on text, and domain misconceptions.
Overview
SciVer formalizes document-grounded, multimodal claim verification: given a claim and a paper's context (text paragraphs P, charts I, tables T), a model predicts entailed or refuted and ideally justifies the decision using the evidence.
This approach draws from established work in scientific document understanding such as (MultiVerS, Wadden et al., 2021), which demonstrated weak supervision techniques for scientific claim verification, but extends the scope to true multimodal reasoning.
Because scientific tables often have complex structures, SciVer uses table and chart screenshots as inputs, which aligns with recent advances in (multimodal table understanding, Yang et al., 2025) and reflects how intricate layouts, mathematical notation, and visual elements often resist simple textual conversion.
The benchmark comprises four subsets aligned with real reasoning patterns:
- Direct reasoning: verify a claim by locating a single relevant element (a paragraph, table, or chart).
- Parallel reasoning: synthesize information from multiple sources concurrently (e.g., compare two tables).
- Sequential reasoning: chain intermediate conclusions across modalities where one step's output becomes the next step's premise.
- Analytical reasoning: apply domain principles or methodological understanding beyond literal data extraction.
Each example provides expert-annotated supporting evidence. The construction process emphasizes annotator expertise (18 graduate-level researchers across CS subfields) and multi-stage validation, achieving high label agreement (reported inter-annotator agreement approximately 94%). Data were drawn from recent arXiv CS papers with sufficient multimodal content and curated to exclude non-essential sections (e.g., related work, references) to keep inputs focused.
Why It's Important
SciVer addresses a significant gap in current evaluation frameworks. Most prior work in scientific QA or verification isolates modalities, for example text-only systems like (MAPLE, Zeng and Zubiaga, 2024) for few-shot claim verification, table-only fact checking approaches such as (T-REX, Horstmann et al., 2025), or chart-only question answering, which misses the integrated nature of real scientific papers.
This fragmentation fails to capture how scientists actually reason: by synthesizing evidence across complementary modalities where text provides context, tables offer quantitative support, and charts reveal patterns or trends.
SciVer pushes models to truly read across modalities and demonstrates that current systems often fail when evidence requires multi-hop, cross-modal synthesis. The results also quantify the cost of dropping multimodal information: text-only baselines show markedly weaker performance, underscoring the importance of visual elements in scientific reasoning.
Beyond benchmarking, SciVer clarifies research priorities for model improvement: robust chart and table understanding, better evidence retrieval and filtering across modalities, and reasoning architectures that maintain coherence across multiple inference steps.
These insights are particularly relevant given the recent focus on (multimodal evidence summarization, Chen et al., 2024) and efforts to build more transparent fact-checking systems that can explain their reasoning process to users.
Discussion
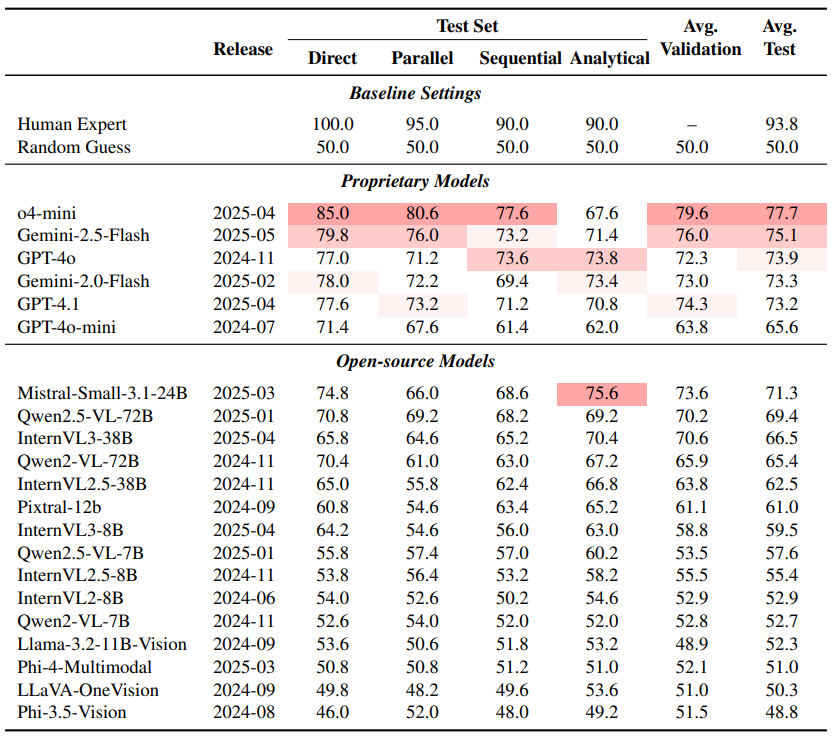
Table 3: Model accuracy on SCIVER validation and test sets with CoT prompts, ranked by test set performance
Results at a glance. Human experts reach about 93.8 percent on a small expert-run sample; leading models trail notably. Table 3 in the paper reports accuracy across the four subsets with Chain-of-Thought prompting, showing a persistent gap between models and humans. Reported figures also show that even strong systems like GPT-4 class models underperform on tasks requiring multi-hop, cross-modal reasoning. Open-source models have improved quickly, for example Mistral Small 3.1, Qwen2.5-VL, and InternVL3 are competitive, but as a group still lag top proprietary models and humans.
Detailed performance breakdown (Table 3). The comprehensive evaluation table reveals striking performance variations across reasoning types. While o4-mini achieves the highest overall accuracy at 78.4%, it still falls significantly short of human expert performance at 93.8%. The performance hierarchy shows proprietary models generally outperforming open-source alternatives, with Gemini-2.5-Flash (77.8%) and GPT-4.1 (73.2%) leading among widely-available models. Notably, analytical reasoning proves most challenging across all models, with even the best-performing o4-mini achieving only 75.6% accuracy compared to 90.0% human performance on this subset. This suggests that complex domain-specific reasoning requiring methodological understanding remains a significant bottleneck for current AI systems.
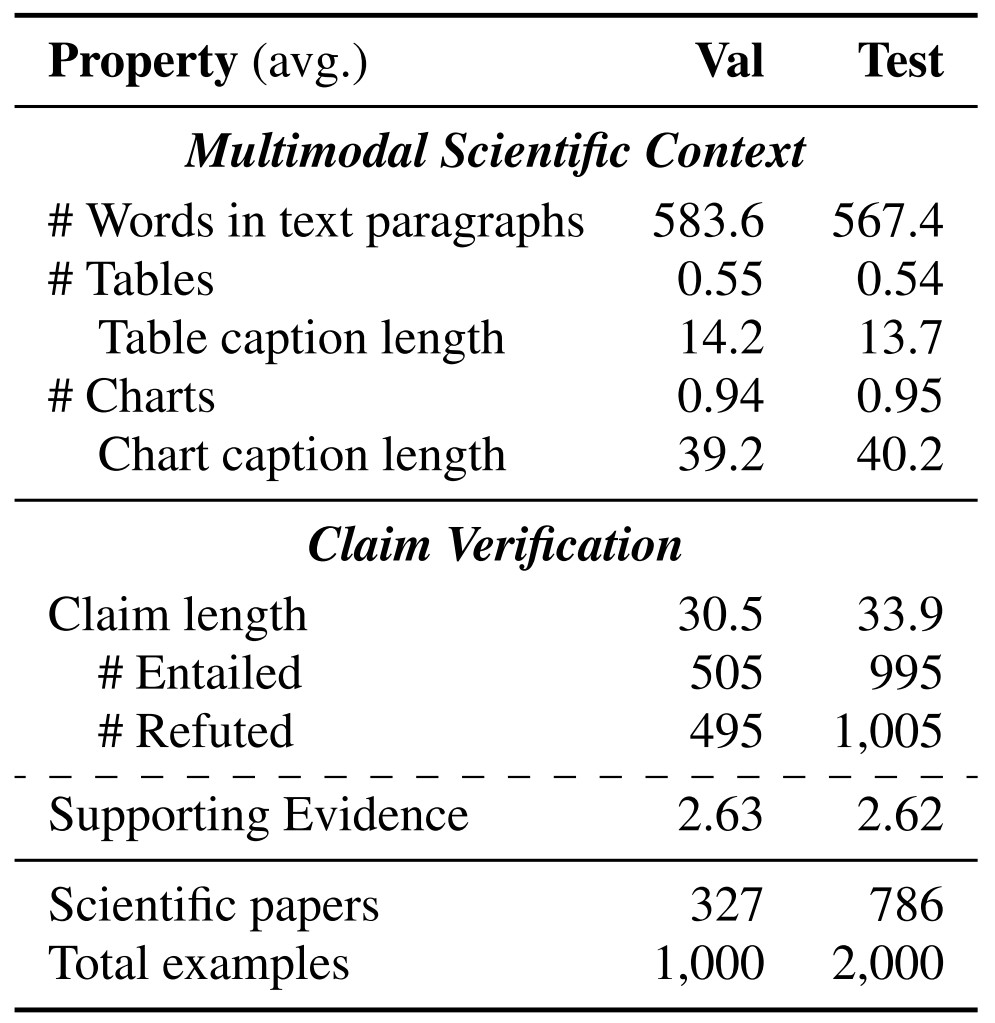
Dataset composition insights (Table 2). The benchmark's structure reveals careful design considerations that mirror real scientific reasoning challenges. With 3,000 total examples distributed across four reasoning types, the dataset maintains balance while ensuring adequate representation of each complexity level. The average of 2.6 supporting evidence pieces per example reflects realistic scientific claim verification scenarios where multiple sources must be synthesized. The split into 1,113 papers across computer science subfields ensures domain diversity while maintaining annotation quality through expert involvement. Crucially, the 94% inter-annotator agreement demonstrates the reliability of expert judgments, providing confidence that performance gaps reflect genuine model limitations rather than inconsistent ground truth.
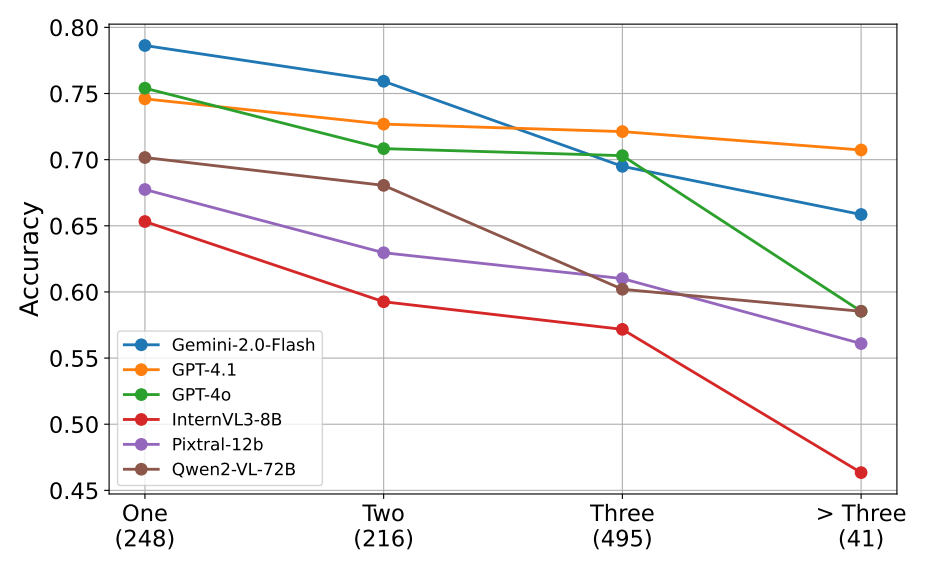
Evidence complexity matters (Figure 4). The relationship between evidence complexity and model performance reveals fundamental limitations in current multimodal reasoning capabilities. Figure 4 demonstrates a clear downward trend as claims require more supporting evidence pieces, with accuracy dropping dramatically from claims requiring one piece of evidence to those needing four or more. This pattern holds consistently across top-performing models including o4-mini, Gemini-2.5-Flash, and GPT-4.1. The steepest decline occurs between two and three evidence pieces, suggesting that models struggle particularly with the transition from simple parallel reasoning to complex multi-hop inference. This finding indicates that retrieval and evidence selection represent critical bottlenecks, as models must not only identify relevant information across modalities but also maintain coherent reasoning chains across multiple inference steps.
RAG analysis reveals retrieval bottlenecks (Table 4). The retrieval-augmented generation study provides crucial insights into information access limitations. Table 4 shows that higher-quality retrievers directly correlate with improved downstream performance, with OpenAI embeddings achieving 81% Recall@5 compared to 70.7% for Contriever and 74.3% for BM25. This translates to substantial accuracy gains: GPT-4o-mini improves from 63.8% to 67.0% (+3.2%) with better retrieval, while Qwen2.5-VL sees gains from 70.2% to 72.9% (+2.7%). The oracle condition, where models receive perfect evidence, reveals the upper bound of current reasoning capabilities, with GPT-4o-mini reaching 73.3% (+9.5% improvement) and Qwen2.5-VL achieving 75.3% (+5.1% improvement). The additional LLM-based evidence filtering provides further gains, suggesting that both retrieval quality and evidence selection precision are crucial for optimal performance.
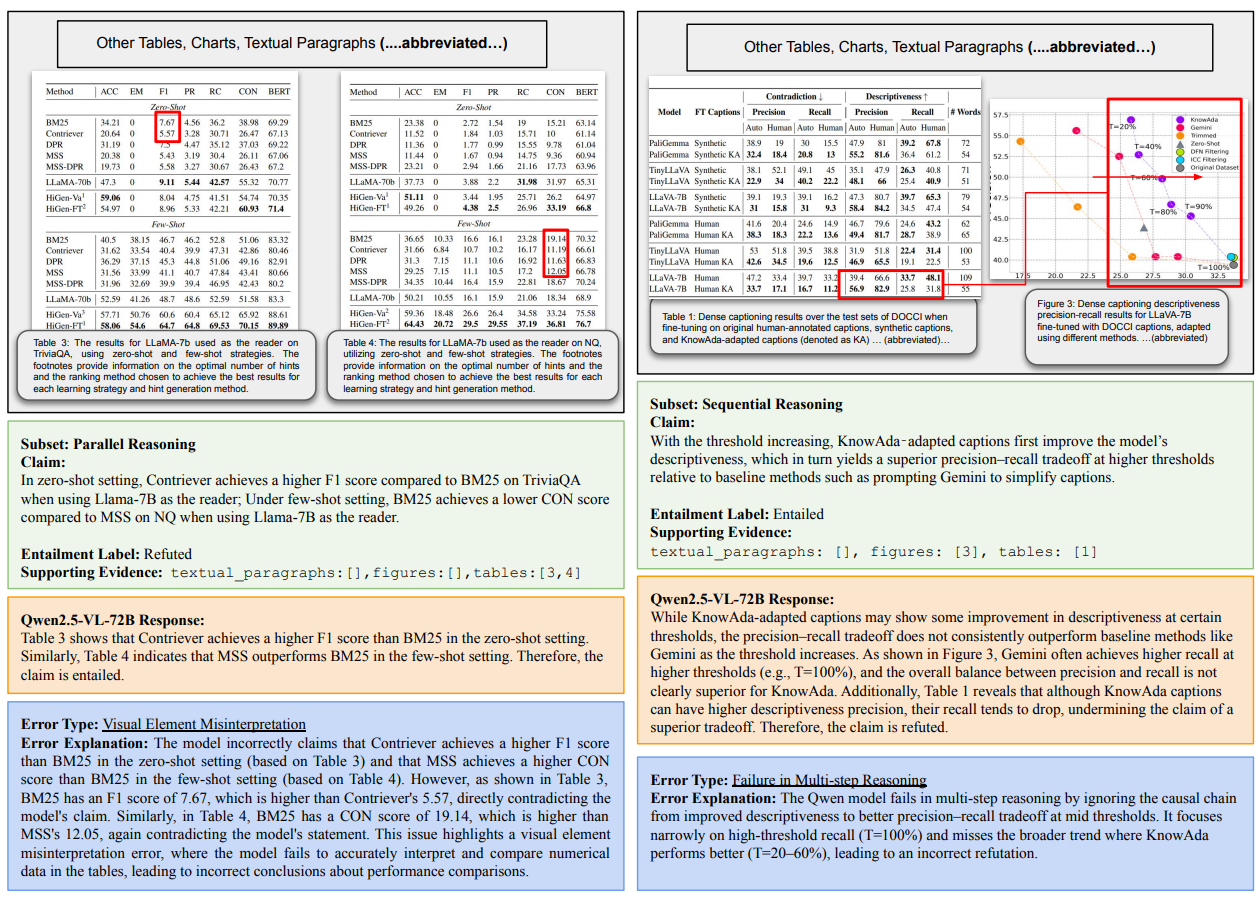
Error modes and failure patterns (Figure 5). The detailed error analysis reveals systematic weaknesses that mirror real-world deployment challenges. Figure 5 illustrates two primary failure categories that account for a significant portion of model errors. Visual Element Misinterpretation errors occur when models incorrectly parse charts, tables, or figures, often missing critical details like axis labels, legend information, or numerical relationships. These errors are particularly problematic because they can lead to confident but incorrect conclusions. Multi-step Reasoning failures happen when models lose coherence across inference chains, either by forgetting intermediate conclusions or failing to properly integrate information from different modalities. The examples show how models might correctly interpret individual elements but fail to synthesize them into coherent reasoning, highlighting the challenge of maintaining logical consistency across complex multimodal contexts.
Modality-specific challenges. The benchmark reveals distinct challenges across different input types that reflect the complexity of scientific literature. Chart interpretation errors often involve misreading scales, confusing categories, or failing to understand comparative relationships between data series. Table analysis failures typically occur when models struggle with complex layouts, multi-level headers, or numerical computations across rows and columns. Text-visual integration proves particularly challenging when claims require synthesizing information from paragraphs with quantitative evidence from figures or tables. These patterns suggest that effective multimodal scientific reasoning requires not just strong unimodal capabilities but sophisticated integration mechanisms that can maintain coherence across diverse information sources.
Dataset composition and quality validation. According to Table 2 in the paper, the dataset maintains careful balance by label (entailed/refuted) and includes an average of roughly 2.6 supporting evidence items per example, providing realistic difficulty. Multi-stage validation and adjudication processes ensure claims cannot be verified from text alone when charts or tables are required, and that evidence pointers are adequate without extra context. The 232 examples requiring revision during validation (about 8% of total) demonstrate rigorous quality control, while the high inter-annotator agreement of 94% confirms the reliability of expert judgments.
Reproducibility and access. The dataset card lists a CC-BY-4.0 license. The GitHub repository provides quickstart scripts using vLLM for inference and an automated accuracy evaluation script, which should facilitate reproduction and extensions. See scripts/vllm_large.sh, acc_evaluation.py, and the top-level README.md. The authors report ACL 2025 acceptance for the work, indicating peer review and archival publication.
Conclusion
SciVer establishes a new standard for evaluating multimodal scientific claim verification by requiring models to reason across text, tables, and charts with carefully annotated evidence. The benchmark reveals meaningful progress in AI capabilities while highlighting a persistent gap to human expert performance on complex reasoning tasks. The comprehensive evaluation of 21 models provides clear evidence that current systems struggle most with analytical reasoning and multi-hop inference that spans modalities.
For researchers and practitioners, SciVer points toward three critical research directions: developing more sophisticated chart and table parsers with better visual encoders; building retrieval systems specifically adapted to multimodal scientific artifacts; and designing reasoning architectures that can reliably carry intermediate conclusions across inference steps. The benchmark's integration with established scientific publishing practices and its open-source availability should accelerate progress in these areas.
The work also connects to broader trends in AI evaluation, including the growing emphasis on real-world applicability and the need for explainable systems that can justify their reasoning. As multimodal foundation models continue to advance, benchmarks like SciVer will be essential for ensuring that progress translates to practical capabilities in scientific domains. If you work on agentic reading systems, retrieval-augmented generation for scientific papers, or multimodal verification more broadly, SciVer provides a rigorous and challenging testbed for measuring genuine scientific reasoning capabilities.
Definitions
Claim verification: Classifying whether a claim is supported (entailed) or contradicted (refuted) by given context.
Multimodal: Involving multiple data types such as text, images (charts), and table screenshots.
RAG (retrieval-augmented generation): A pipeline where relevant evidence is retrieved and fed to a model to improve factuality and grounding.
Chain-of-Thought (CoT): Prompting strategy that elicits step-by-step reasoning before producing a final answer.
Inter-annotator agreement: A measure of labeling consistency across annotators.References
(Primary) (Wang et al., 2025). SciVer: Evaluating Foundation Models for Multimodal Scientific Claim Verification. arXiv:2506.15569.
(Dataset) (HuggingFace, 2025). SciVer Dataset. Hugging Face.
(Code) (GitHub, 2025). SciVer Code Repository. GitHub.
(FEVER) (FEVER, 2025). Fact Extraction and VERification Workshop and Shared Tasks.
(SciFact) (Wadden et al., 2020). Fact or Fiction: Verifying Scientific Claims. EMNLP 2020.
(MultiVerS) (Wadden et al., 2021). MultiVerS: Improving scientific claim verification with weak supervision and full-document context. arXiv:2112.01640.
(Multimodal Tables) (Yang et al., 2025). Does Table Source Matter? Benchmarking and Improving Multimodal Scientific Table Understanding and Reasoning. arXiv:2501.13042.
(MAPLE) (Zeng and Zubiaga, 2024). MAPLE: Micro Analysis of Pairwise Language Evolution for Few-Shot Claim Verification. arXiv:2401.16282.
(T-REX) (Horstmann et al., 2025). T-REX: Table -- Refute or Entail eXplainer. arXiv:2508.14055.
(MetaSumPerceiver) (Chen et al., 2024). MetaSumPerceiver: Multimodal Multi-Document Evidence Summarization for Fact-Checking. arXiv:2407.13089.



SciVer Puts Multimodal Claim Verification To The Test
SciVer: Evaluating Foundation Models for Multimodal Scientific Claim Verification