Researchers from Zhongguancun Academy, Peking University, Tencent AI Lab, and collaborating institutions have developed SciAgent, a hierarchical multi-agent system that achieves gold medal performance across multiple International Olympiad competitions.
Published on arXiv in November 2025, the work introduces what the authors term generalistic scientific reasoning, the capacity to dynamically adapt problem-solving strategies across diverse scientific domains and difficulty levels without domain-specific redesign. This contrasts with contemporary approaches where models achieve over 90% on traditional benchmarks like MMLU but struggle on graduate-level or expert-designed problems.
Unlike specialized systems engineered for individual competitions, SciAgent employs a Coordinator-Worker-Sub-agents hierarchy that attempts to mirror how human scientists decompose cognitive tasks.
"The SciAgent architecture is designed around the principle that scientific reasoning is inherently hierarchical." (Li et al.)
The system achieved scores exceeding average gold medalist performance on the 2025 International Mathematical Olympiad (36 out of 42 points versus 35.94 average), perfect scores on the 2025 International Mathematics Competition (100 out of 100), and gold-level results on the 2024 and 2025 International Physics Olympiads. In the 2025 Chinese Physics Olympiad, SciAgent scored 264 out of 320 points, surpassing the highest human gold medalist score of 199 (OpenDCAI, 2025).
Key Takeaways
- SciAgent introduces a three-tier hierarchical architecture where a Coordinator Agent routes problems to specialized Worker Systems, each containing collaborative Sub-agents for generation, verification, and multimodal analysis.
- The system achieves gold medal performance across five major competitions: IMO 2025 (36/42 points), IMC 2025 (100/100 points), IPhO 2024 (27.6/30 points), IPhO 2025 (25.0/30 points), and CPhO 2025 (264/320 points).
- Different Worker Systems employ domain-appropriate reasoning frameworks: mathematics uses iterative reasoning-review cycles for proof construction, while physics employs ReAct loops integrating symbolic computation with diagram analysis.
- The hierarchical structure enables extensibility, new domains can be added by instantiating specialized Worker Systems without modifying existing architecture, demonstrated through preliminary Chemistry Olympiad capabilities.
- Evaluation methodology combines AI-based grading with human expert verification, ensuring alignment with official competition scoring rubrics across all benchmarks.

Figure 2: SciAgent consists of a hierarchical multi-agent framework with a Coordinator Agent that routes problems to domain-specific Worker Systems. Each Worker System—Math, Physics, Chemistry, and General Exam—contains multiple Sub-agents (e.g., Generator, Reviewer, Image Analyser) collaborating through adaptive reasoning loops. The right panel summarizes key design principles: hierarchical meta-reasoning, modularity, and adaptive assembly. Credit: li et al.
ALL Code is planned to be released by Nov 20.
The Hierarchical Architecture for Scientific Cognition
SciAgent operationalizes scientific reasoning through a three-tier hierarchy that separates meta-reasoning from execution. At the top level, the Coordinator Agent performs domain inference, difficulty assessment, and adaptive routing. When presented with a problem, it analyzes the task structure, determines whether symbolic deduction, numerical modeling, or conceptual analysis is required, and dispatches the problem to the appropriate Worker System.
The middle tier consists of specialized Worker Systems, each functioning as a self-contained multi-agent ensemble for a specific scientific domain. The Math Olympiad Worker coordinates symbolic deduction and proof verification through Generator, Improver, and Reviewer Agents that iterate until solutions pass validation checks.
The Physics Olympiad Worker implements a ReAct framework (Yao et al., 2022) where Generator, Image Analyser, Reviewer, and Summarizer Agents alternate between reasoning and observation cycles, enabling dynamic coordination between code execution and perceptual feedback. While the Chemistry Olympiad Worker integrates Molecule Recognition and SMILES Verify Agents alongside reasoning components to handle molecular structure tasks.
At the execution level, Sub-agents perform concrete operations such as algebraic manipulation, model formulation, code execution, diagram analysis, and result verification. These agents communicate through structured message passing and critique-revision loops, with feedback flowing upward to enable Workers to revise reasoning trajectories when inconsistencies arise.
This separation of control, specialization, and execution distinguishes SciAgent from flat multi-agent networks that lack mechanisms for meta-reasoning about which reasoning style suits a given task.
Domain-Specific Reasoning Strategies
Mathematical problem-solving in SciAgent emphasizes internal consistency over environmental interaction. For example, Olympiad mathematics problems are typically single-modal and compact in description yet high in conceptual complexity, requiring logically complete reasoning chains.
The Math Worker therefore employs a structured reasoning-review architecture where the Generator Agent produces initial solutions, the Improver Agent refines them through self-critique, and the Reviewer Agent validates correctness. This iterative cycle continues until solutions pass a threshold number of review checks or until a review error triggers targeted correction.
The authors note that while ReAct frameworks combining Thought, Action, and Observation cycles are widely adopted in general-purpose reasoning agents (Yao et al., 2022), they prove less suited to domains demanding uninterrupted symbolic reasoning.
In mathematical problem-solving, extended deductive chains tend to saturate the model context window before meaningful feedback can be incorporated, making iterative ReAct loops inefficient for maintaining logical coherence. The reasoning-review approach instead prioritizes complete proof construction followed by comprehensive validation.
Physics problems, by contrast, are inherently multimodal and step-decomposable, often requiring transitions between conceptual modeling, mathematical formulation, and diagram-based numerical analysis. The Physics Worker naturally aligns with the ReAct paradigm, where the Generator drives symbolic and computational reasoning, the Image Analyser interprets experimental or graphical data, the Reviewer validates physical consistency, and the Summarizer consolidates results into structured answers.
Flexible reasoning trajectories emerge dynamically from the interaction between code execution and perceptual feedback, mirroring the iterative reasoning process of human physicists.
For chemistry, the Worker System reflects the complex nature of problems requiring both symbolic reasoning and molecular recognition. Tasks involve chemical reaction prediction, molecular structure analysis, and verification of chemical equations.
The system integrates a Generate Agent for formulating hypotheses, a Molecule Recognition Agent for interpreting structures from textual or visual data, a SMILES Verify Agent for validating chemical notation, a Chemistry Knowledge Agent that recalls domain-specific principles, and a Breakdown Agent that simplifies complex reactions. These agents interact within an adaptive ReAct loop where the system generates hypotheses, interacts with specialized agents, and refines reasoning through feedback.
Benchmark Performance Across Olympiad Competitions
In the International Mathematical Olympiad 2025, SciAgent scored 36 out of 42 points, solving five of six problems completely with partial progress on the final problem. This total exceeds the average gold medalist score of 35.94 and meets the overall gold standard threshold.
Note from Joshua: The avg human gold score being nearly identical to the SciAgent score suggests that there may be an issue with training data overlapping with the test version used in this research. Such tight couple between the two averages suggest to me that further investigation is needed to rule out data contamination.
The IMO represents one of the most prestigious mathematics competitions globally, featuring problems that demand deep ingenuity and non-routine constructive arguments. The sixth problem, where SciAgent achieved only 1 point, was also the most difficult for human competitors, with even gold medalists showing significant variability in performance. The system demonstrated particular strength in problems requiring multi-step algebraic manipulation and proof by construction.
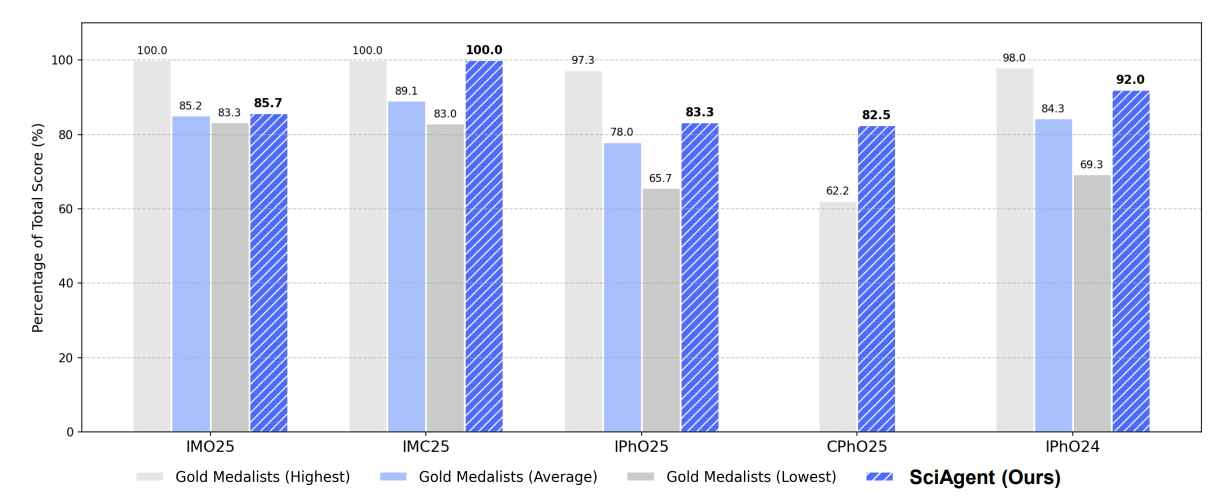
Figure 1: We compare SciAgent’s performance (represented by the striped blue bars) with the highest, average, and lowest gold medalist scores across five competitions: IMO25, IMC25, IPhO25, CPhO25 and IPhO24. Our SciAgent achieves gold medal performance in all tasks, surpassing the average gold medalist score, and its performance in IMC25 and CPhO25 is on par with or even exceeds the highest human gold medalist scores. Credit: li et al.
On the International Mathematics Competition 2025, SciAgent achieved a perfect score of 100 out of 100 points, matching the highest human Grand First Prize performance and exceeding both the average score of 89.08 and the lowest threshold of 83.
The IMC format comprises ten problems spanning algebra, number theory, and combinatorics, testing robustness across multiple mathematical subdisciplines. The perfect score indicates strong reliability in the multi-agent reasoning mechanism and adaptive coordination among internal mathematical sub-agents.
For physics competitions, SciAgent achieved 25.0 out of 30.0 points on IPhO 2025, exceeding the average gold medalist score of 23.4, and 27.6 out of 30.0 points on IPhO 2024, again outperforming the average gold medalist score of 25.3. These results demonstrate the system can generalize reasoning across both conceptual and computational sub-problems while maintaining coherence.
The paper includes a detailed comparison showing that SciAgent successfully solves problems where direct large language model approaches fail, even for formulaic calculations, highlighting the value of the multi-agent architecture over single-model inference. (Appendix B)
In the Chinese Physics Olympiad 2025, SciAgent achieved 264 out of 320 points, significantly surpassing the highest human gold medalist score of 199. This substantial margin demonstrates the scalability of the multi-agent ReAct architecture for solving extended multi-step problems involving symbolic derivation and visual data interpretation.
The CPhO problems typically require more extensive computational work than IPhO problems, and the system performance validates the effectiveness of the internal coordination mechanism where specialized sub-agents for generation, modeling, verification, and summarization collectively sustain accuracy across long reasoning chains.
Rigorous Evaluation with AI-Assisted Grading
The research team employed a two-stage evaluation methodology to ensure accurate and fair assessment. First, an AI evaluator receives both the official standard answer including specific scoring criteria and the complete output from SciAgent.
The evaluator performs a comprehensive review of the problem-solving process, analyzing all intermediate steps and the final answer to assign a score according to official rubrics. These AI-generated scores are then collected, anonymized, and reviewed by human experts familiar with official scoring standards.
Crucially, human experts verify the AI-assigned scores rather than rescoring solutions from scratch. This approach leverages AI efficiency for initial detailed analysis while maintaining human oversight for accuracy and adherence to competition standards.
For Olympiad benchmarks, problems are typically divided into multiple parts with specific point values, and the total score for a problem is the sum of points awarded for each part. This granular scoring allows the evaluation to capture partial credit for incomplete solutions, mirroring how human competitors are assessed.
The final validated scores are benchmarked against official performance thresholds for human competitors. The paper presents detailed score breakdowns showing performance on individual problems and sub-parts, providing transparency into where the system excels and where challenges remain.
For the Humanity Last Exam tasks, the team selected a subset of mathematics and physics problems to assess consistency between SciAgent outputs and standard solutions. HLE represents a significant challenge even for frontier models, as questions are designed to be unambiguous, easily verifiable, but impossible to quickly answer via internet retrieval, providing a rigorous test of genuine reasoning capabilities (Phan et al., 2025).
Generalization Beyond Olympiads
To assess general scientific reasoning capabilities beyond competition benchmarks, the researchers evaluated SciAgent on selected tasks from the Humanity Last Exam benchmark (Phan et al., 2025). This frontier-hard dataset curates closed-ended, retrieval-resistant questions designed to remain challenging for state-of-the-art models across mathematics, physics, chemistry, and biology.
Unlike traditional benchmarks where models achieve over 90% accuracy, HLE consists of 2,500 questions developed globally by subject-matter experts that cannot be quickly answered via internet retrieval. The evaluation demonstrates SciAgent adaptability to problem formats outside specialized Olympiad structures.
In the mathematics domain, SciAgent successfully calculated log probabilities for sequences in hidden Markov models by decomposing HMM diagrams and computing transition and emission probabilities.
For physics, the system applied Thevenin Theorem to analyze electrical circuits, solving differential equations and calculating cutoff frequencies. While in chemistry, it analyzed the enantioselective synthesis pathway for a complex natural product by decomposing substrate and reagent roles and generating plausible reaction sequences.
The biology task involved examining histopathological kidney biopsy images to identify glomerular sclerosis and other lesions using both symbolic reasoning and image analysis.
These cases illustrate SciAgent versatility in adapting to different problem types. Whether for structured mathematical derivations or open-ended conceptual analysis, the system coordinates between symbolic reasoning, mathematical modeling, and perceptual understanding.
The ability to decompose complex problems, derive necessary formulas, and validate solutions underscores adaptive scientific reasoning across diverse disciplines and problem levels. However, the authors note that the Chemistry and Biology Worker Systems remain in development and have not yet reached gold medalist performance levels.
Limitations and Benchmarking Constraints
The paper acknowledges important limitations in evaluation scope. Chemistry and Biology Olympiad results were not included in the current evaluation due to data availability and benchmarking constraints.
The International Chemistry Olympiad does not publicly release individual participant scores; instead, medal distributions are determined proportionally based on score rankings rather than absolute values. As a result, there are no accessible human baselines for quantitative comparison in IChO, preventing full results for Chemistry Olympiad tasks in this evaluation.
For the International Biology Olympiad, all problems and official solutions from the past two years are subject to a restricted blackout period during which competition materials are not publicly available for research or benchmarking purposes.
Given these constraints, SciAgent evaluation currently focuses on mathematics and physics domains where both problem materials and human performance references are accessible and standardized. The Chemistry Agent System has shown potential in handling basic chemical reasoning tasks but has not been validated against top human performance due to lack of publicly available benchmarks.
Another consideration is the reliance on Gemini 2.5 Pro as the underlying language model across all agents in the system. While the architecture is designed to be model-agnostic and each agent can be configured to use any LLM, all experiments in the paper employed the same model.
This raises questions about how performance might vary with different base models or heterogeneous agent configurations. The paper does not explore whether specialized models for different domains might improve performance or whether the hierarchical coordination can effectively leverage model diversity (DeepMind, 2025).
Positioning in Multi-Agent Reasoning Research
SciAgent builds on recent advances in LLM-based multi-agent systems while introducing architectural innovations for cross-domain scientific reasoning. Prior work, such as PhysicsMinions, achieved gold medal performance in individual physics olympiads through co-evolutionary multi-agent frameworks featuring three synergistic studios for visual interpretation, logic formulation, and dual-stage verification (Yu et al., 2025).
The system delivered the first-ever open-source gold medal in IPhO 2025, elevating open-source models from 1-2 to 6 gold medals across seven olympiads. For IMO-style problems, model-agnostic verification-and-refinement pipelines iterate generation, critique, and repair to attain proof-level soundness (Huang and Yang, 2025).
These systems, while achieving impressive domain-specific results, remain fundamentally specialized, each is restricted to a single discipline and relies on handcrafted proof strategies or fixed toolchains that cannot transfer across domains.
By contrast, SciAgent hierarchical coordination framework enables dynamic assembly of reasoning pipelines suited to problem structure and modality without domain-specific redesign. The Coordinator Agent performs meta-reasoning about which Worker System and strategy to invoke, while Workers self-assemble internal multi-agent pipelines through adaptive collaboration among Sub-agents.
The work also relates to emerging perspectives on agentic collaboration and reflective reasoning. Systems like Reflexion employ self-improvement via reflection and verbal reinforcement learning, maintaining episodic memory buffers of past reflections to induce better decision-making in subsequent trials, achieving 91% pass@1 accuracy on HumanEval coding benchmarks (Shinn et al., 2023).
MetaGPT introduces meta-programming for multi-agent collaborative frameworks, encoding Standardized Operating Procedures into prompt sequences and assigning diverse roles to agents following an assembly line paradigm (Hong et al., 2024).
SciAgent extends these ideas by embedding hierarchical structure that explicitly separates reasoning control from execution, enabling the system to reason about reasoning rather than simply executing collaborative protocols.
Technical Implementation Details
The implementation integrates existing open-source multi-agent frameworks with custom coordination logic. Following implementations from smolagents, which provides a lightweight library for building agentic systems (Roucher et al., 2025), and domain-specific systems, the team constructed Worker Systems and Sub-agents and integrated them into SciAgent unified coordination framework.
This integration ensures consistent communication protocols, adaptive routing, and system-level coordination across heterogeneous agents. The reasoning and coordination capabilities throughout the framework are powered by LLM-based agents, with Gemini 2.5 Pro configured as the default model.
The Math Worker architecture avoids ReAct cycles because extended deductive chains in mathematics tend to saturate context windows before meaningful feedback can be incorporated.
Instead, it employs a reasoning-review loop where the Generator produces complete solution attempts, the Improver performs targeted refinements, and the Reviewer validates against problem constraints. The process continues until solutions pass a threshold number of review checks or until specific errors are identified and corrected. This design prioritizes logical completeness over incremental environmental interaction]
The Physics and Chemistry Workers implement ReAct loops where Thinking, Action, and Observation phases alternate. During the Thinking phase, the Generator formulates hypotheses and plans computational steps. In the Action phase, code execution, diagram analysis, or molecular recognition occurs through specialized Sub-agents.
The Observation phase integrates results back into the reasoning context, allowing the system to adjust its trajectory based on computational outcomes or perceptual feedback. This cyclic structure naturally accommodates the step-decomposable nature of physics and chemistry problems.
Future Research Directions
The authors envision several research trajectories building on this foundation. Expansion to additional scientific domains will extend SciAgent to interdisciplinary sciences, integrating new reasoning agents specialized for experimental design, molecular modeling, and data interpretation. The team plans to develop Worker Systems for biology, materials science, and potentially social sciences, testing whether the hierarchical framework generalizes beyond STEM disciplines.
Multimodal scientific reasoning represents another priority. Real scientific inquiry involves text, equations, images, experimental data, and interactive simulations. Incorporating enhanced multimodal perception and reasoning such as advanced visual diagram analysis, table interpretation, and equation grounding will improve SciAgent cognitive completeness. Current image analysis capabilities handle static diagrams, but dynamic visualizations and temporal data present additional challenges.
The development of collaborative and self-evolving agents could enable persistent reasoning memory and continuous refinement of collaboration policies. Future versions may include inter-agent negotiation mechanisms where Sub-agents can challenge each other assumptions and reach consensus through structured debate. Self-improving feedback loops would allow the system to learn from past problem-solving experiences, building a knowledge base of successful strategies and common pitfalls.
Integration with real-world scientific workflows aims to deploy SciAgent as a partner in actual research environments, automating parts of hypothesis generation, simulation verification, and analytical modeling, thus bridging AI reasoning and scientific discovery.
Implications for AI in Scientific Research
SciAgent represents a concrete step toward what the authors call generalistic scientific intelligence, AI systems capable of coherent, cross-disciplinary reasoning at expert levels. The hierarchical architecture demonstrates that scientific cognition can be operationalized through structured coordination among specialized agents rather than relying solely on scaling individual model capabilities.
This architectural approach may prove complementary to continued advances in foundation model performance, with hierarchical coordination enabling effective deployment of model capabilities across diverse reasoning tasks.
The success on olympiad-level problems suggests progress toward AI systems that can tackle graduate-level challenges (Rein et al., 2023), though significant gaps remain between competition performance and open-ended research contribution.
The gold medal performance across multiple olympiads validates that multi-agent systems can achieve expert-level results without extensive domain-specific engineering. However, the true test of generalistic reasoning will come from deployment in open-ended research contexts where problem formulations are unclear, relevant knowledge must be discovered rather than retrieved, and solutions require genuine creativity rather than pattern matching against training data.
The Humanity Last Exam results provide encouraging evidence of capability beyond structured competition problems, but substantial work remains to bridge the gap between competition performance and research contribution.
For the broader AI research community, SciAgent offers both inspiration and caution. The inspiration comes from demonstrating that hierarchical multi-agent architectures can coordinate complex reasoning across domains, suggesting a path toward more general AI systems that combine specialized capabilities.
The caution emerges from recognizing that even gold medal performance on olympiads does not necessarily translate to the kind of open-ended scientific reasoning required for original research. The system solves well-defined problems with clear evaluation criteria, but scientific discovery often involves recognizing which problems to solve in the first place.
Conclusion
SciAgent advances the state of AI in scientific reasoning through a hierarchical multi-agent architecture that achieves gold medal performance across mathematics and physics olympiads while maintaining extensibility to new domains.
By separating meta-reasoning from execution and enabling adaptive assembly of reasoning pipelines, the system demonstrates that scientific problem-solving can be operationalized as self-organizing coordination among specialized agents. The consistent performance across competitions with different formats, problem types, and difficulty levels provides evidence that the approach supports genuine adaptability rather than narrow specialization.
The work establishes important baselines for evaluating multi-agent scientific reasoning systems and introduces methodological innovations in AI-assisted grading validated by human experts.
While limitations remain in chemistry and biology domains due to benchmark availability, and questions persist about how the architecture would perform with heterogeneous base models, SciAgent demonstrates a viable path toward more general scientific AI.
Future developments integrating multimodal reasoning, self-evolution, and deployment in real research workflows will determine whether this approach can progress from competition performance to genuine scientific contribution. The open-source release invites the research community to build on this foundation and explore the frontiers of generalistic scientific intelligence.
Definitions
Generalistic Scientific Reasoning: The capacity of an AI system to autonomously select, compose, and adapt reasoning procedures suited to a given problem structure and modality across diverse scientific domains without domain-specific redesign or human intervention.
Coordinator Agent: The top-level component in SciAgent hierarchy that performs global task understanding, domain and difficulty inference, and adaptive routing to appropriate Worker Systems based on problem characteristics.
Worker System: A self-contained multi-agent subsystem specializing in a scientific domain or reasoning mode, composed of interacting Sub-agents that construct and refine solution strategies tailored to specific task demands.
ReAct Framework: A reasoning paradigm that combines Thought, Action, and Observation cycles, enabling systems to alternate between symbolic reasoning and environmental interaction through iterative feedback loops (Yao et al., 2022).
SMILES (Simplified Molecular Input Line Entry System): A notation system for representing molecular structures as linear text strings, enabling computational processing of chemical compounds and verification of molecular structure correctness.
International Mathematical Olympiad (IMO): An annual mathematics competition for pre-university students featuring six problems that demand deep ingenuity and non-routine constructive arguments, with medals awarded based on score thresholds (Wikipedia, 2025).
International Physics Olympiad (IPhO): A global physics competition for secondary school students requiring complex conceptual modeling, symbolic derivation, and multi-stage quantitative reasoning across theoretical and experimental problems (Wikipedia, 2025).
Humanity Last Exam (HLE): A benchmark dataset curating closed-ended, retrieval-resistant questions across scientific disciplines designed to remain challenging for state-of-the-art language models (Phan et al., 2025).



SciAgent: Gold Medal Performance Through Hierarchical Multi-Agent Scientific Reasoning
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning