When AI Doctors Need Better Report Cards
A future where AI is designed to help improve diagnostic medicine and even find rare diseases may be very close thanks to research from ScaleAI. But what does it need to be a serious contributor to domain expertise? It needs to consider a wide range of data points including symptoms, medical history, test results, and specialist knowledge then provide clear reasoning for its recommendations.
The researchers simply ask: how do you train such a system? Traditional approaches often rely on simple positive or negative feedback such as in reinforcement learning training, but medical diagnosis requires nuanced evaluation across multiple criteria such as accuracy, reasoning quality, consideration of differentials, and appropriate confidence levels.
This paper introduces "Rubrics as Rewards" (RaR). Rather than training AI systems with opaque preference signals, the researchers propose something more systematic. Providing explicit evaluation criteria that breaks down complex tasks into measurable components, much like the rubrics teachers use to grade essays or doctors use to assess clinical competency.
Their approach, detailed in "Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains" by researchers from Scale AI, bridges a critical gap in AI training. While traditional reinforcement learning excels in domains like coding and mathematics where answers are objectively correct, real-world applications demand multi-criteria evaluation. The results are impressive with up to a 28% improvement on medical benchmarks while maintaining the transparency that high-stakes applications require.
Key Takeaways
- Rubrics as Rewards (RaR) replaces opaque preference models with explicit expert criteria, making AI training more interpretable and effective
- Performance gains are substantial: Up to 28% improvement on medical benchmarks and 13% on scientific reasoning tasks compared to standard methods
- Transparency matters: Unlike black-box methods, RaR shows exactly what the model is being rewarded for, enabling better debugging and validation
- Expert knowledge integration: The approach systematically incorporates domain expertise through structured evaluation criteria rather than ad-hoc feedback
- Scalability advantage: Smaller judge models perform better with rubric guidance, reducing computational costs while improving alignment
- Future potential: While demonstrated in medicine and science, the framework could extend to any domain where quality criteria can be articulated
Overview
The core insight behind RaR is elegantly simple: if human experts already use structured checklists to evaluate complex responses, why not use those same checklists to train AI systems? Traditional reinforcement learning excels when there's a clear "right answer" such as a chess move that leads to checkmate, code either compiles or crashes, a math solution is correct or incorrect. But what happens when quality depends on multiple factors simultaneously?
Consider a medical AI answering a patient's question about chest pain. Excellence requires: (1) accurate medical information, (2) appropriate urgency assessment, (3) clear, jargon-free communication, (4) empathetic tone, and (5) appropriate recommendations for next steps. Traditional preference-based training might capture some of this complexity, but it creates opaque reward models that are difficult to interpret, audit, or debug when they go wrong.
RaR transforms this challenge into an opportunity. The framework decomposes response quality into prompt-specific rubric items that are concrete, evaluable criteria that capture what makes a response excellent.
These rubrics can be evaluated in two ways: explicitly, by computing a normalized weighted sum
Here,
The beauty of this approach lies in its generality. As the authors demonstrate, RLVR (
(Reinforcement Learning with Verifiable Rewards) becomes a special case of RaR with just one criterion (
Training proceeds using GRPO (Group Relative Policy Optimization) on carefully curated datasets: RaR-Medicine-20k and RaR-Science-20k, with rubrics synthesized by advanced models like o3-mini and GPT-4o, grounded in expert-written reference answers when available.

Figure 1: Overview of Rubrics as Rewards (RaR). (i) Rubric Generation: Researchers synthesize prompt-specific, self-contained rubric criteria using a strong LLM guided by four core design principles, with reference answers serving as proxies for expert supervision. (ii) GRPO Training: These rubrics are used to prompt an LLM judge for reward estimation, which drives policy optimization via the GRPO on-policy learning loop. Credit: Hendryx et al.
How Rubrics Work in Practice
To understand RaR's power, consider how it might evaluate a medical AI's response to "Should I be worried about my chest pain?" A traditional approach might train on thousands of preference pairs, hoping the model learns to balance accuracy, safety, and communication. But what exactly is it learning? RaR makes this explicit through structured criteria:
- Essential Criteria (Weight: 1.0): Response correctly identifies key risk factors for cardiac events; recommends appropriate urgency of medical evaluation; avoids providing specific diagnoses without examination.
- Important Criteria (Weight: 0.7): Uses clear, accessible language avoiding medical jargon; acknowledges patient's concern with appropriate empathy; provides actionable next steps.
- Pitfall Criteria (Weight: 0.8): Does not dismiss symptoms that could indicate serious conditions; avoids overly alarming language that could cause unnecessary panic; does not provide treatment recommendations requiring medical supervision.
Each criterion becomes a binary check during training. The explicit approach sums these weighted evaluations, while the implicit approach feeds all criteria to a judge model for holistic scoring. This transparency serves multiple purposes: researchers can audit why specific responses scored highly, identify failure modes when criteria aren't met, and systematically improve rubrics based on observed weaknesses.
Why It Matters
The stakes for interpretable AI rewards extend far beyond academic benchmarks. In healthcare, a model's decision-making process can mean the difference between life and death.
Financial AI systems managing portfolios need transparent reasoning for regulatory compliance. While scientific AI assistants must demonstrate reliable methodology to maintain research integrity. RaR addresses these needs by making reward attribution explicit and auditable.
Consider the alternative: traditional preference-based training might produce a healthcare AI that performs well on average but fails catastrophically in edge cases. When such failures occur, debugging becomes nearly impossible, was the model optimizing for response length or another metric? Mimicking stylistic quirks of preferred responses? Overfitting to annotator biases? RaR eliminates this opacity by grounding rewards in human-interpretable criteria.
The broader impact extends to AI safety and alignment. As language models become more capable, ensuring they optimize for the right objectives becomes increasingly critical. RaR provides a scalable framework for encoding complex human values into training signals without relying on opaque preference models that may capture spurious correlations.
This is particularly valuable as AI systems tackle increasingly sophisticated tasks where simple correctness metrics fail to capture the full picture of quality and safety (Ma et al., 2025).
Results and Implications
The empirical results speak volumes about RaR's effectiveness. The research team conducted comprehensive experiments across medicine and science domains, training Qwen2.5-7B models using GRPO with carefully tuned hyperparameters: batch size 96, learning rate 5×10⁻⁶, and 16 response samples per prompt for reward estimation. Training utilized 8 H100 GPUs, reflecting the computational investment required for high-quality RL post-training (DeepSeek-AI et al., 2025), (OpenAI, 2024).
Performance gains are substantial: RaR-Implicit achieves up to 28% relative improvement over simple Likert-based rewards on HealthBench-1k and around 13% improvement on GPQA_Diamond. Perhaps more importantly, RaR matches or exceeds the performance of reference-based rewards while providing superior interpretability. This suggests that structured rubric guidance can capture expert knowledge as effectively as direct comparison to expert-written answers.
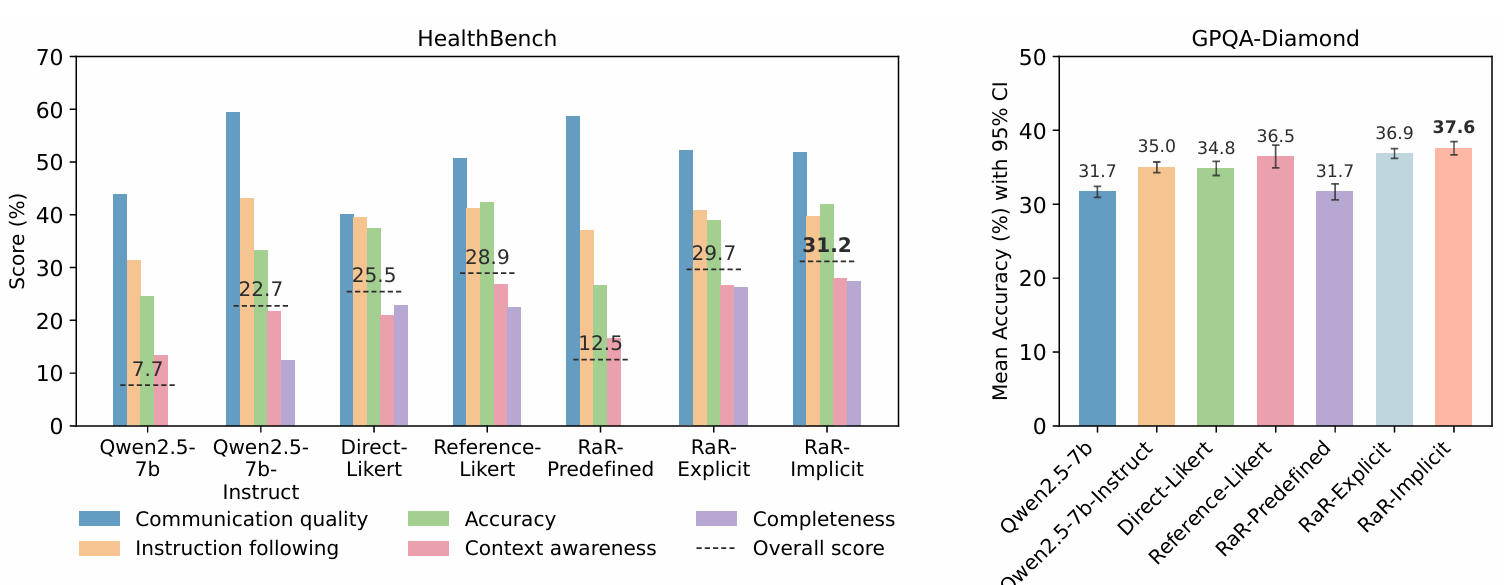
Figure 2: Performance of baselines and RaR (Rubrics as Rewards) variants for the medicine and science domains. HealthBench (left): shows per-axis scores across five core axes, with a thin dashed gray line indicating the overall score (all values shown as percentages). GPQA-Diamond (right): mean accuracy over 10 runs; error bars represent 95% confidence intervals. All policies are evaluated using gpt-4o-mini as the LLM-as-Judge. Across both domains, RaR-Implicit consistently outperforms Direct-Likert and demonstrates a competitive advantage over Reference-Likert. Credit: Hendryx et al.
Judge scaling effects reveal practical benefits: Figure 2 demonstrates that rubric guidance consistently improves judge accuracy across model sizes, with the largest gains for smaller models. This finding has significant practical implications including helping teams with limited computational budgets achieve better alignment using smaller, more cost-effective judge models when guided by well-designed rubrics.
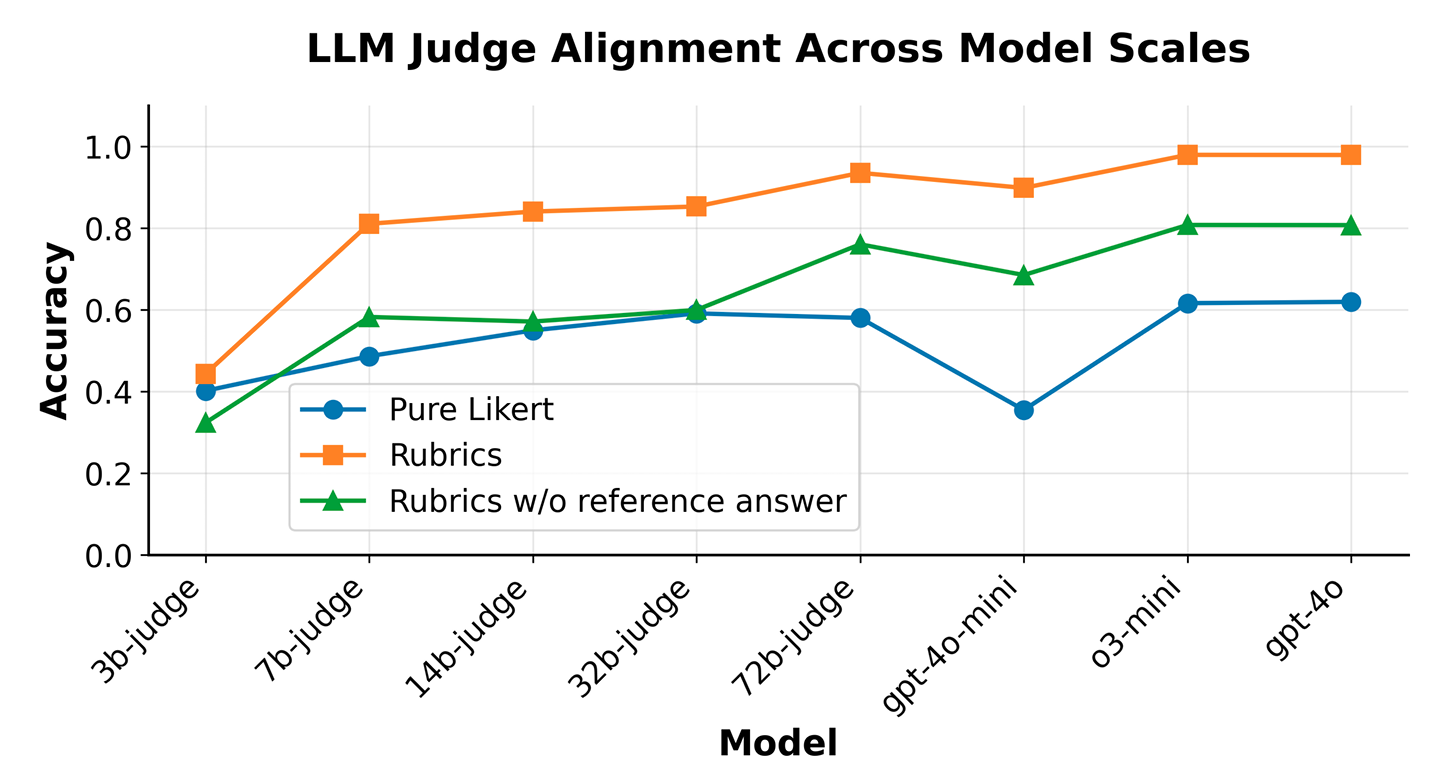
Figure 3: Alignment Study of LLM Judges across Model Scales. Rubrics as Rewards (orange) consistently improves alignment with human preferences across LLM judge sizes compared to direct Likert-based scoring (blue). Judge Alignment using synthetic rubrics without expert grounding (green) outperform the direct Likert baseline, but still fall short of expert-grounded rubrics (orange). The rubric structure especially benefits smaller judge models, helping them close the gap with larger models when guided by checklist-style criteria. Credit: Hendryx et al.
Ablation studies provide design insights: Prompt-specific rubrics dramatically outperform generic ones, confirming that contextualization is crucial. Interestingly, implicit aggregation proves more robust than explicit weighted sums, likely because LLM judges can adaptively balance criteria based on context rather than relying on fixed weights. The authors note that synthetically generating effective "pitfall" criteria remains challenging, understanding common failure modes requires human insight that current AI systems struggle to anticipate.
Expert guidance proves essential: Synthetic rubrics generated with access to reference answers significantly outperform those created without expert grounding. This highlights a key practical requirement: while RaR can scale rubric-based training, the initial rubric design benefits enormously from human expertise. Among reference-free generators, GPT-4o produces the most effective rubrics, but still falls short of expert-guided synthesis.
Future Directions and Limitations
While RaR represents a significant advance, the authors acknowledge important limitations that point toward future research directions. The current study focuses on medicine and science—two domains where expert knowledge is well-codified and criteria can be relatively objective. Expanding to more subjective domains like creative writing, strategic planning, or complex ethical reasoning will require more sophisticated rubric design methodologies.
The reward hacking question looms large: while rubrics provide interpretability, a sufficiently motivated model might still game individual criteria without capturing their intended spirit. Unlike opaque preference models where such gaming is invisible, RaR makes potential exploitation explicit—but this visibility doesn't automatically prevent it. Future work should investigate adversarial robustness and develop techniques to make rubric-based rewards more resistant to gaming.
Perhaps most intriguingly, the authors propose using rubrics as curriculum learning tools. Rather than applying all criteria uniformly throughout training, models might start with essential criteria and gradually incorporate more nuanced requirements. This approach could mirror how human experts develop competency—first mastering basic requirements before tackling subtle aspects of quality. The evaluation setup using HealthBench-1k (Arora et al., 2025) and GPQA_Diamond (Rein et al., 2023) provides solid foundations for measuring such progressive development.
Looking Forward: The Promise of Interpretable AI Training
RaR demonstrates that we don't have to choose between powerful AI systems and interpretable training methods. By encoding expert knowledge into explicit rubrics, we can train models that not only perform better but do so in ways we can understand and validate. This transparency becomes crucial as AI systems handle increasingly complex real-world tasks where the stakes such as lives, decisions, trust are high.
The research points toward a future where AI training incorporates human expertise more systematically. Rather than hoping that models learn the right things from opaque reward signals, we can explicitly teach them the criteria that matter. Whether diagnosing patients, answering scientific questions, or tackling new domains entirely, rubric-based training offers a path toward AI systems that are both capable and comprehensible.
Perhaps most importantly, RaR makes AI development more collaborative. Instead of relegating human experts to providing thumbs-up or thumbs-down feedback, this approach invites them to articulate the nuanced criteria that define quality in their domains. In a world where AI capabilities are advancing rapidly, such human-AI collaboration isn't just beneficial—it's essential for building systems we can trust to get the important things right.
Definitions
RLVR: Reinforcement Learning with Verifiable Rewards - training with programmatic correctness checks as reward signals.
Rubrics as Rewards (RaR): A method that converts prompt-specific checklist criteria into reward signals for on-policy RL.
Explicit Aggregation: Computes from binary criterion checks.
Implicit Aggregation: A judge model ingests rubric items and returns a single holistic score representing overall quality.
GRPO: A reinforcement learning algorithm used for on-policy post-training updates to the policy model.
HealthBench: A physician-authored, rubric-based open benchmark for health dialogue evaluation (Arora et al., 2025).
GPQA_Diamond: A challenging science QA benchmark focused on graduate-level knowledge (Rein et al., 2023).


Rubrics As Rewards: Reinforcement Learning Beyond Verifiable Domains
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains