Computer architecture is having an AI moment. Yet despite rapid progress in agentic tooling for coding and verification, hardware-centric knowledge remains stubbornly hard for language models to master.
A new dataset, QuArch, offers a tight, domain-specific check: 1,547 multiple-choice questions, rigorously validated by experts, covering processor design, memory systems, interconnects, benchmarking, and emerging topics like accelerators and near-storage computing.
The goal is simple and overdue: measure whether today's models actually understand the fundamentals of systems design well enough to support real hardware workflows.
QuArch arrives as a complement to general benchmarks like MMLU, which capture broad technical knowledge but not the core trade-offs of architecture practice (Hendrycks, 2021). It also sits between easier knowledge checks and extremely difficult, hand-crafted exams such as GPQA (Rein, 2023).
The authors report that even the best closed-source models top out at 84% accuracy on QuArch, while strong open models lag by about 12 percentage points. Small models fine-tuned on the dataset gain 5.4% to 8.3% in accuracy. The dataset and leaderboard are available at quarch.ai and harvard-edge.github.io/QuArch.
Key Takeaways
- QuArch introduces 1,547 expert-validated multiple-choice questions spanning 13 core architecture areas.
- Frontier closed models reach about 84% accuracy; top small open models trail by roughly 12 percentage points.
- Models struggle most on memory systems, interconnection networks, and benchmarking/measurement.
- Fine-tuning small instruction-tuned LMs on QuArch yields 5.4% to 8.3% accuracy gains.
- Difficulty sits between general knowledge (MMLU) and very hard expert exams (GPQA), making QuArch a practical benchmark for progress tracking.
What QuArch is and how it was built
The dataset targets foundational and advanced concepts essential to architecture practice including execution pipelines, memory hierarchy and virtual memory, interconnects, parallelism, storage and near-data compute, workload characterization, and more. The construction process is a hybrid of curation and synthesis, followed by multi-stage validation.
First, the authors compiled an extensive architecture knowledge base they call Archipedia, spanning five decades of academic and industrial sources and exceeding a billion tokens.
Using this corpus, commercial LMs generated cloze-style multiple-choice questions, which were then validated through a layered process involving graduate-level experts and the LLM-as-a-judge protocol, implemented via independent reviewers reaching consensus.
Questions lacking definitive answers or that were too narrow were removed. This intentional mixing of synthetic generation with careful human review improves coverage while preserving correctness. Label Studio supported the review workflow (Tkachenko, 2020-2024).
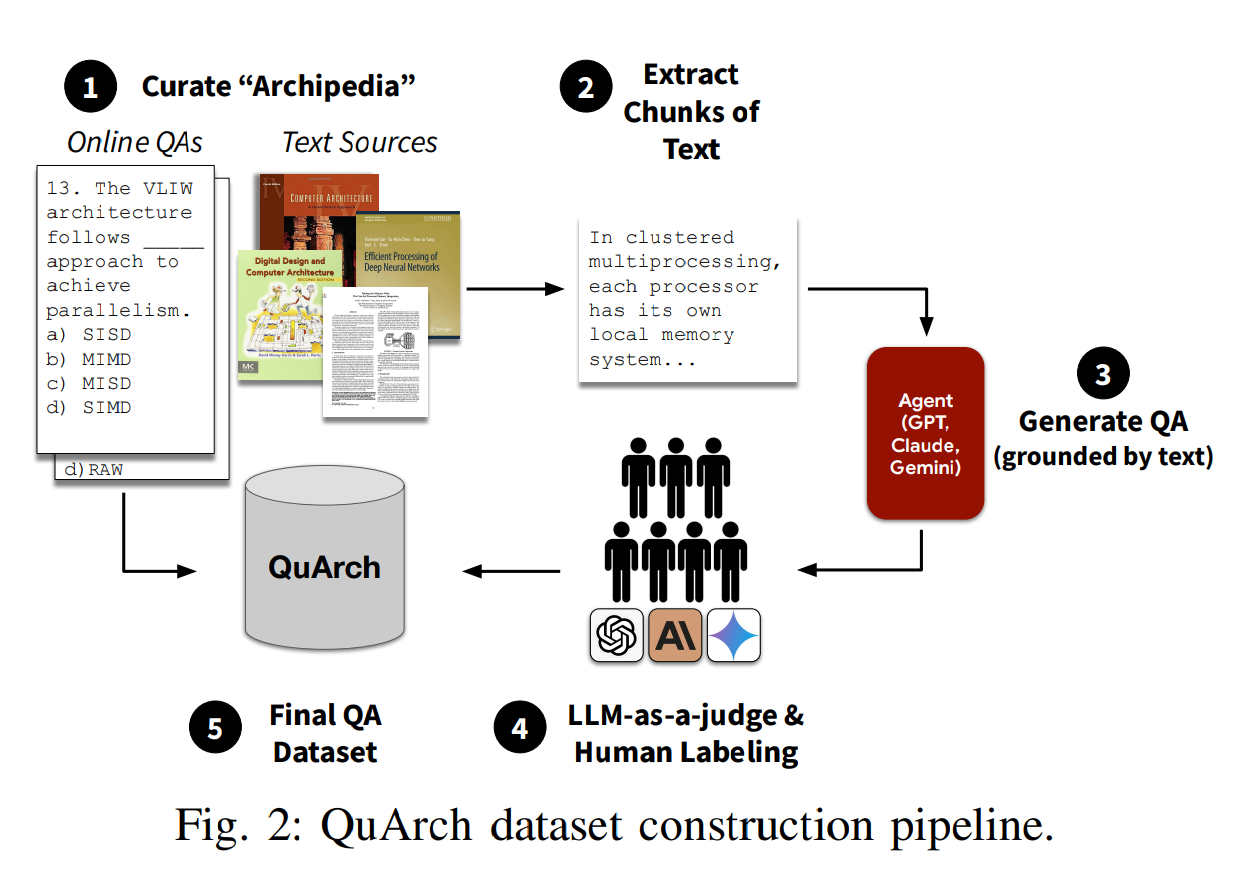
Figure 2 in the paper presents the pipeline: (1) curate and consolidate the domain corpus, (2) map topic coverage, (3) synthesize candidate QAs from source fragments, (4) validate with experts and LLMs, and (5) finalize the benchmark with additional vetted items. The authors report topic assignment via embeddings-based similarity with a second-stage LM arbiter, resulting in a distribution dominated by processor architecture (about one third), followed by memory and interconnects.
Why this matters for AI in hardware
Benchmarks define the contours of progress. In hardware, where correctness, performance, and safety hinge on nuanced system interactions, a generalist score does not reveal whether a model can reason about cache coherence, NUMA effects, or link-level congestion.
Recent domain-adapted efforts like ChipNeMo show the upside of tailoring LMs to EDA tasks and engineering workflows (Liu, 2023). QuArch complements this line of work with a focused knowledge check: do models truly grasp the architectural substrate that downstream automation depends on?
That is important for agentic chains that combine retrieval, code synthesis, and verification. If a model is shaky on memory systems or interconnects, it may propose plausible but incorrect designs or measurement plans.
QuArch's topic-level analysis is particularly useful: it identifies where to invest in corpus enrichment, retrieval strategies, or targeted fine-tuning to offset domain gaps, a pattern mirrored in advances on general benchmarks like MMLU (Hendrycks, 2021).
What the results show
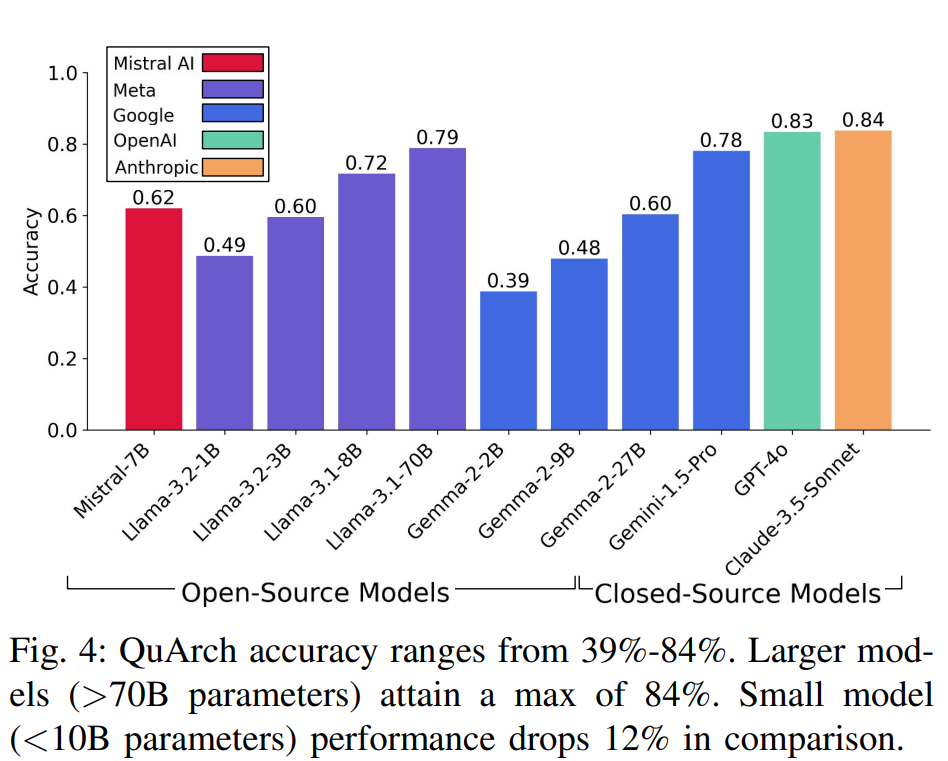
Figure 4 summarizes headline performance: model accuracy ranges from about 39% to 84%, with larger models clustering near the top and small models clearly behind. The reported 84% ceiling suggests substantial room remains before automated assistants exhibit expert-level reliability on architectural knowledge.
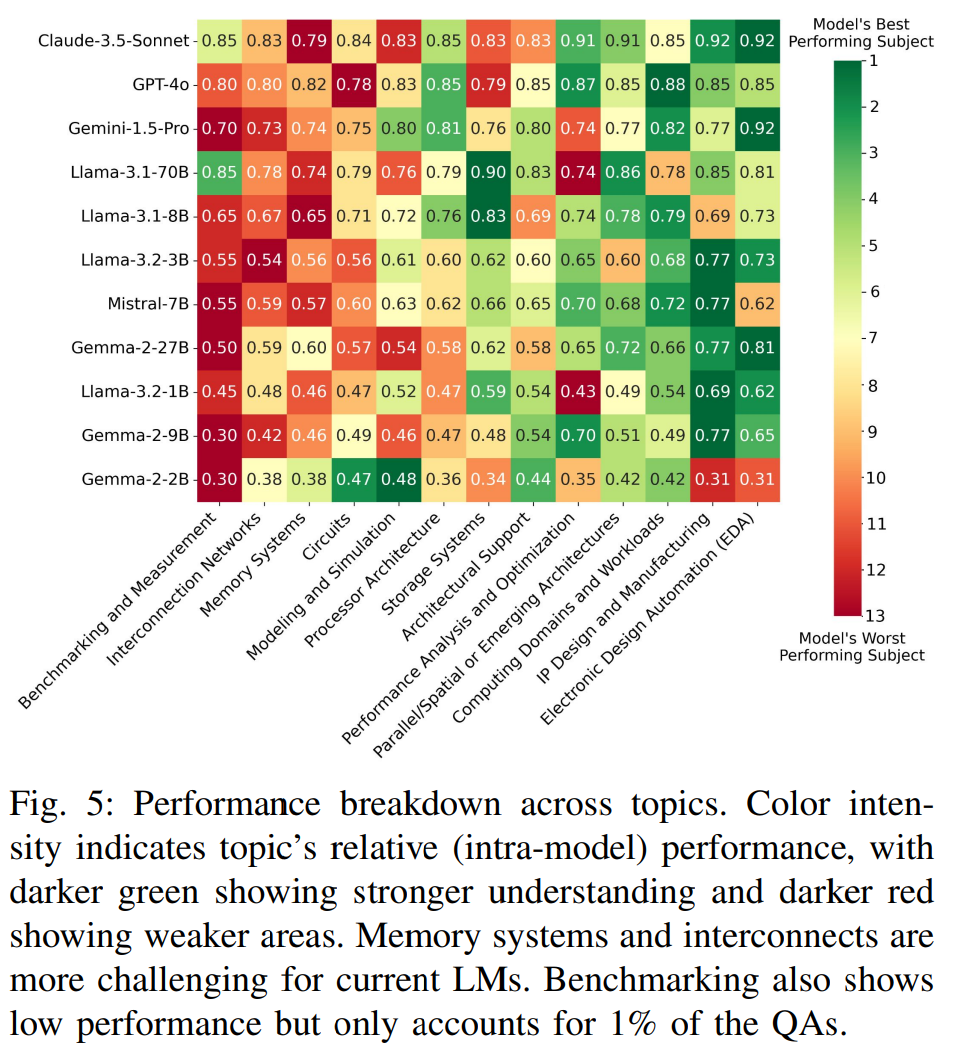
Figure 5 provides the most actionable signal: a heatmap of per-topic accuracy, normalized relative to each model's average to highlight strengths and weaknesses. Across families, models perform relatively well on EDA concepts, IP design and manufacturing, parallel processing fundamentals, and workload characterization. Weak spots consistently appear in three areas: memory systems, interconnection networks, and benchmarking/measurement. These are exactly the topics where real systems work forces trade-offs across latency, bandwidth, ordering, and contention - and where shallow pattern matching breaks down.

Table I compares QuArch to two familiar benchmarks. GPT-4o and Claude 3.5 Sonnet score roughly 88-89% on MMLU and about 54-59% on GPQA, versus 83-84% on QuArch. That triangulation is helpful: QuArch is tougher than broad knowledge quizzes yet easier than graduate-level, open-research puzzles. It is a realistic calibration point for progress in the systems slice of model competence.
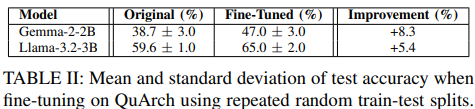
Table II focuses on QuArch as a training set. After fine-tuning, Gemma-2-2B improves by about 8.3 percentage points and Llama-3.2-3B by about 5.4 percentage points on repeated splits. That is a meaningful jump for small models, consistent with the idea that domain-specific data tightens factual grounding and reduces brittle guessing. For production systems, combining fine-tuning with retrieval over authoritative sources would likely be the pragmatic path forward.
Two additional observations stand out. First, topic-level variance varies by model family, suggesting data blend effects: models exposed to more GPU and accelerator literature appear stronger on parallel processor questions than on classical memory and networks content.
Second, the evaluation is purely zero-shot multiple choice with expert prompting - a reasonable baseline for knowledge retrieval, though not a full test of multistep reasoning or design synthesis. The authors explicitly note that future datasets should grow toward reasoning, planning, and design evaluation.
Limitations and next steps
QuArch specifically tests knowledge retrieval in a multiple-choice format. It does not evaluate multi-hop design reasoning, procedural verification, or code generation fidelity. The authors point to future expansions toward planning and design benchmarks.
Another limitation is the dependence on the Archipedia corpus and topic labeling pipeline; while embeddings plus LM arbitration is sensible, it inherits any bias in the underlying sources and topic taxonomy.
Finally, no artifact-level code or reproducer is required to use the dataset, but longer-term impact will hinge on sustained updates, clear licensing, and alignment with emerging agent workflows.
Conclusion
QuArch is a timely contribution for AI in computer systems: a high-coverage, expert-validated QA benchmark that reveals where models are ready to help and where they are likely to hallucinate or oversimplify. The consistent weaknesses in memory, interconnects, and measurement are a call to action for targeted corpus development, retrieval strategies, and fine-tuning.
If you are building agentic tools for hardware design, performance analysis, or workload engineering, QuArch offers a practical yardstick for baseline knowledge - and a compact dataset that meaningfully boosts small models. Read the paper and explore the leaderboard to see how your preferred models fare, and consider contributing to the next iteration as the field pushes toward reasoning- and design-level evaluations.
Paper metadata: QuArch - A Question-Answering Dataset for AI Agents in Computer Architecture by Shvetank Prakash, Andrew Cheng, Jason Yik, Arya Tschand, Radhika Ghosal, Ikechukwu Uchendu, Jessica Quaye, Jeffrey Ma, Shreyas Grampurohit, Sofia Giannuzzi, Arnav Balyan, Fin Amin, Aadya Pipersenia, Yash Choudhary, Ankita Nayak, Amir Yazdanbakhsh, Vijay Janapa Reddi. arXiv, 2025. DOI: 10.48550/arXiv.2501.01892 - arXiv page: arxiv.org/abs/2501.01892.
References
(Hendrycks, 2021) Measuring Massive Multitask Language Understanding. ICLR 2021.
(Rein, 2023) GPQA: A Graduate-Level Google-Proof Q&A Benchmark.
(Liu, 2023) ChipNeMo: Domain-Adapted LLMs for Chip Design.
(QuArch project site) Dataset and leaderboard.
(Tkachenko, 2020-2024) Label Studio: Data labeling software.


QuArch Puts AI Agents to the Test on Computer Architecture
QuArch: A Question-Answering Dataset for AI Agents in Computer Architecture