Large language models are hard to deploy because memory and latency balloon with scale. In Findings of the Association for Computational Linguistics: ACL 2025, Yifan Yang and colleagues from the University of California, Santa Barbara and Amazon AGI introduce Wanda++, a pruning framework that narrows this gap by using decoder block level gradients and a tiny block local update loop.
The authors report that, at 2:4 sparsity, Wanda++ reduces WikiText perplexity by up to 32 percent relative to Wanda while pruning a 7B model in under 10 minutes on a single H100. The work sits squarely in the post training compression space alongside magnitude pruning, SparseGPT, Wanda, and gradient informed scoring methods like GBLM ((Sun, 2023), (Frantar and Alistarh, 2023), (Das et al., 2023)).
Unlike full model backpropagation based approaches that are memory intensive, Wanda++ computes regional gradients by backprop through one decoder block at a time and combines them with Wanda style input norms into a Regional Gradient Score. It then performs a few steps of Regional Optimization inside that block to better align dense and pruned outputs.
The target models include LLaMA and OpenLLaMA families ((Touvron et al., 2023)), and the method aligns well with hardware friendly 2:4 semi structured sparsity supported by NVIDIA Sparse Tensor Cores ((NVIDIA Developer Blog, 2021)).
Key Takeaways
- Regional Gradient Score fuses block local gradient magnitude with input activation norms to select weights; it improves pruning quality without global backprop.
- Regional Optimization is a short, in block mean squared error alignment between dense and pruned block outputs that mitigates pruning loss using only a few calibration samples.
- Perplexity drops up to 32 percent over Wanda at 2:4 sparsity on WikiText, with consistent gains across LLaMA 7B, 13B, 30B, 65B, and OpenLLaMA 3B, 7B, 70B.
- Runtime practicality: a 7B model can be pruned in under 10 minutes on one H100; memory footprint scales with hidden size rather than total parameter count.
- Orthogonal to fine tuning: LoRA recovers similar additional perplexity reductions for both Wanda and Wanda++ ((Hu et al., 2021)).
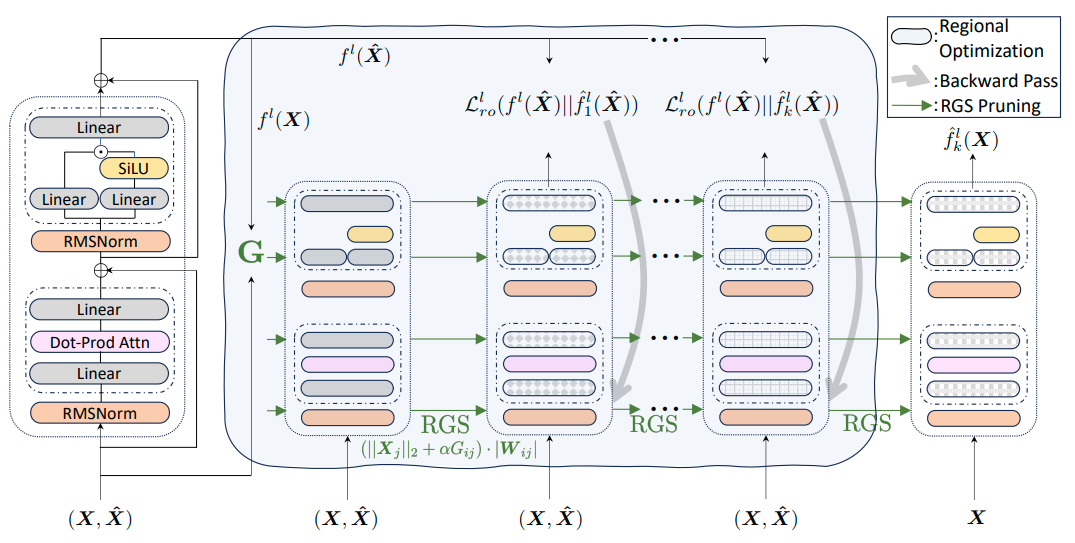
Figure 2: Illustration of Wanda++, which leverages regional gradients in two ways: first, we estimate the block-level gradient G, used in Regional-Gradient Scoring (RGS) for layer-wise pruning in each block. Next, we calculate the pruning-induced loss Lro for lightweight Regional Optimization (RO). RO can be iterated multiple times to infer better pruning masks for each decoder block. Image Credit: Yang et al.
How Wanda++ Works
Wanda++ is a two stage, per decoder block workflow. First, it assigns a Regional Gradient Score (RGS) to each weight element by combining a one time, block local gradient estimate with an activation norm term.
Concretely, for weight element Wij in a layer within block l, the score has the form
Sij = (α·Gij + ||Xj||2) · |Wij|, where G is the gradient magnitude from a backward pass on the L2 norm of the block output,
α is a constant to balance
the magnitude of the gradient and input activation
terms, and ||Xj|| is the per channel input norm. This mirrors the GBLM insight that first order terms matter while keeping compute local and cheap ((Das et al., 2023)).
Second, Wanda++ runs Regional Optimization (RO) with a handful of iterations where it forwards a small, random subset of calibration inputs through the dense and pruned versions of the same block, minimizes the mean squared error between their outputs, and updates only the weights in that block with a tiny learning rate (RMSprop). After each RO round, it reapplies RGS pruning to restore the target sparsity.
The RO loss with input
Background and Context
Magnitude pruning is a classic baseline: drop the smallest weights by absolute value. Wanda improved on this by scaling magnitudes with input activations, a better proxy for sensitivity in LLMs where feature scales vary widely ((Sun, 2023)).
SparseGPT showed one shot pruning can reach 50 to 60 percent unstructured sparsity with small perplexity increases by solving local reconstruction problems layer by layer ((Frantar and Alistarh, 2023)). GBLM went further by using properly normalized gradients from a few samples to shape the pruning metric ((Das et al., 2023)).
At deployment time, semi structured 2:4 sparsity is particularly practical because NVIDIA’s A100 and newer GPUs accelerate it in hardware. In every group of four weights, two must be zero, yielding 50 percent sparsity with regular metadata and measurable speed ups in TensorRT and TensorRT LLM pipelines ((NVIDIA Developer Blog, 2021), (TensorRT LLM, 2025)).
For compression more broadly, weight only quantization like AWQ is a complementary, near lossless 4 bit technique that often pairs well with sparsity ((Lin et al., 2024)).
Why This Matters
Practitioners need pruning that is both effective and economical. Full model backprop methods deliver informative gradients but at the cost of massive activation storage and GPU memory, which does not scale well to today’s foundation models.
Gradient free methods are memory frugal but can leave performance on the table. Wanda++ threads this needle: it injects gradient information where it counts the most, inside each decoder block, and avoids loading the entire model at once. The result is a practical method that improves the single shot quality of sparsity masks and reduces the amount of downstream fine tuning needed.
This block local formulation also aligns with how inference runtimes schedule work. If pruning can be done per block with predictable sparsity patterns like 2:4, deployment stacks such as TensorRT LLM can realize real latency gains. NVIDIA documents TTFT and throughput improvements with 2:4 under FP16 and FP8 in production style pipelines, which supports the author's choice to emphasize semi structured patterns ((NVIDIA Developer Blog, 2021), (TensorRT LLM, 2025)).
What The Results Show
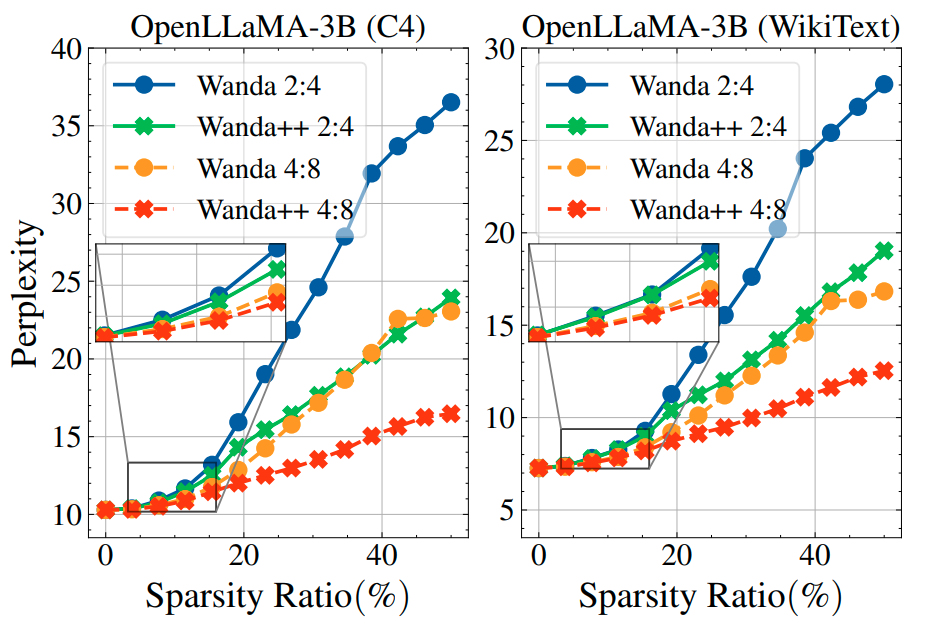
Perplexity. Figure 3 tracks C4 validation and WikiText test perplexity as sparsity increases on OpenLLaMA 3B by pruning two additional decoder blocks at a time up to all 26. At full 2:4 sparsity, Wanda++ reduces C4 perplexity from 36.5 to 23.9 and WikiText from 23.1 to 16.4, roughly 29 to 34 percent relative improvements. The gains grow with sparsity and, notably, Wanda++ at 2:4 approaches or beats Wanda at 4:8, a looser pattern.
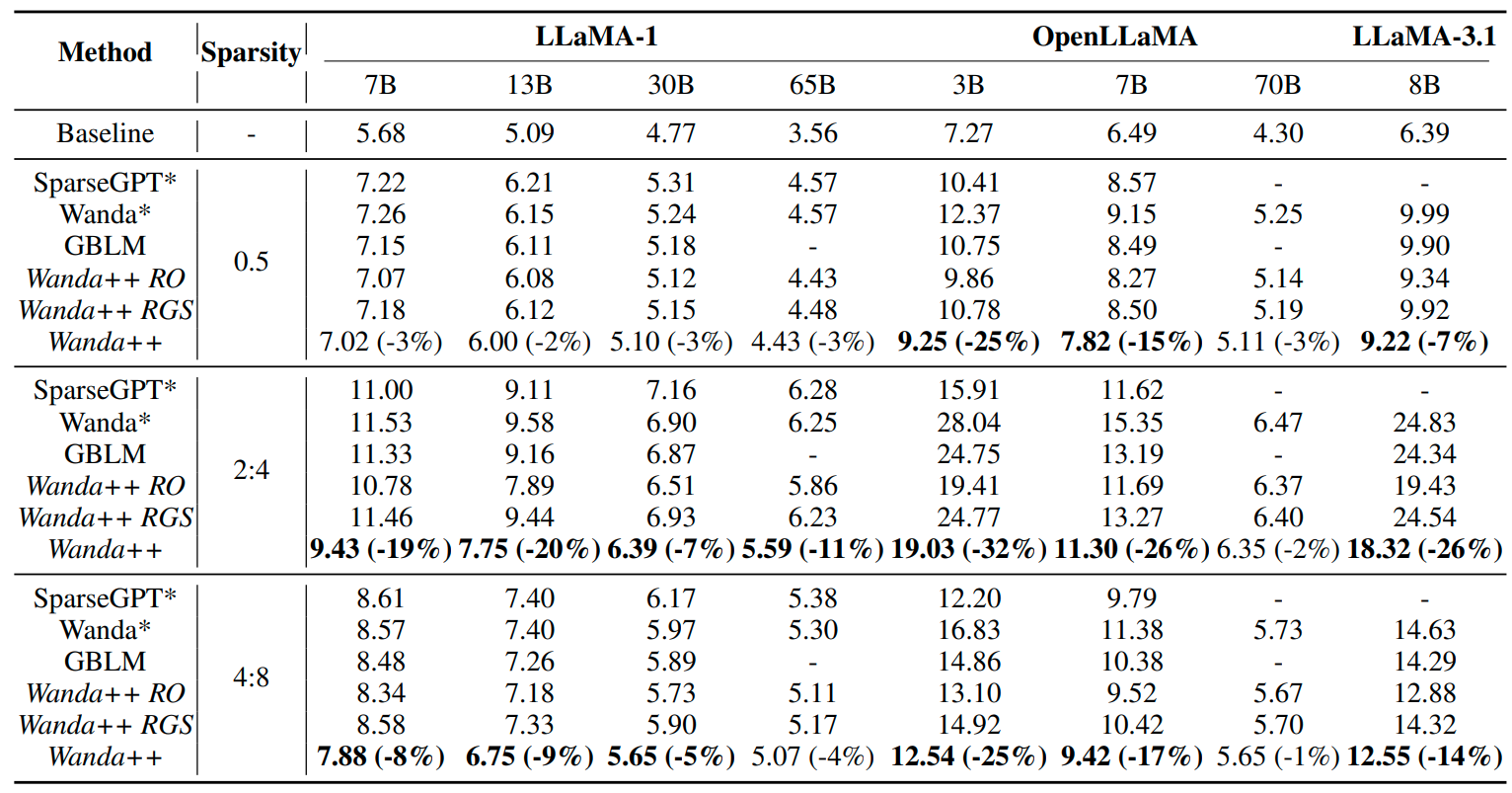
Table 1 extends this across LLaMA 7B, 13B, 30B, 65B and OpenLLaMA 7B, 70B, plus LLaMA 3.1 8B: at 2:4, relative WikiText perplexity reductions versus Wanda are around 19 percent (7B), 20 percent (13B), 7 percent (30B), and 11 percent (65B), with even larger margins on smaller OpenLLaMA.

Zero shot tasks. Table 2 reports 2:4 sparsity results on nine tasks using LLaMA 7B. Wanda++ generally leads or ties across tasks, with especially large gains on MRPC and RTE where it closes much of the gap to dense. This suggests Regional Optimization, although trained only to match block outputs on C4 samples, does not overfit and can generalize to downstream evaluations.
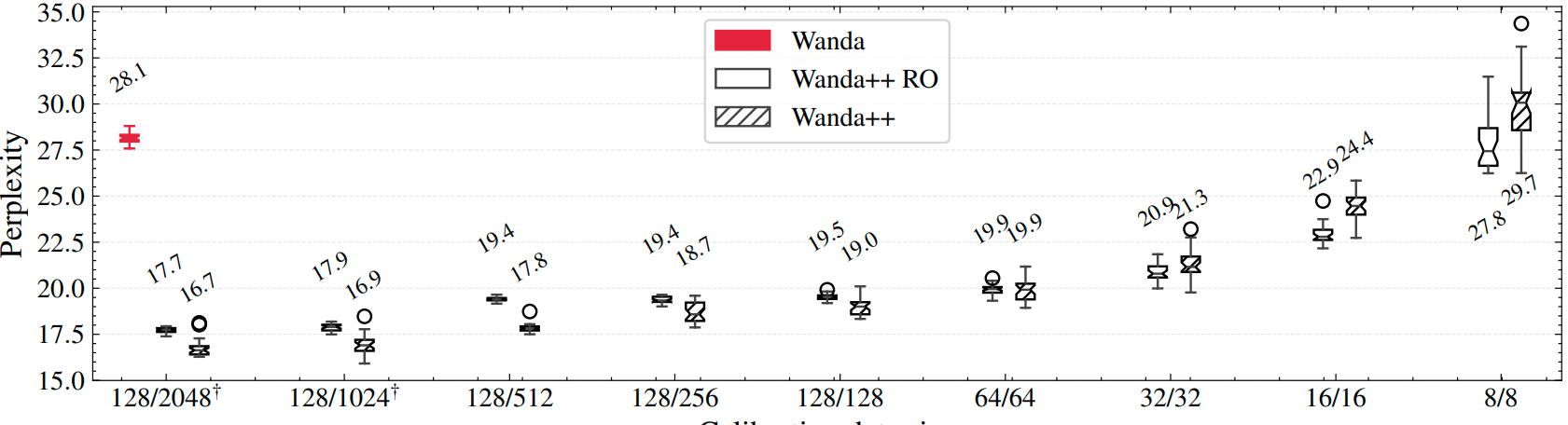
Sensitivity to calibration data. Figure 4 varies the number and length of calibration samples for the 3B model and shows box plots over 30 runs. Wanda++ benefits from larger calibration sets and begins to surpass Wanda++ RO beyond about 64 by 64 tokens. Even at small settings like 16 by 16, both Wanda++ variants outperform Wanda in perplexity, though Wanda++ exhibits more variance at tiny data sizes.
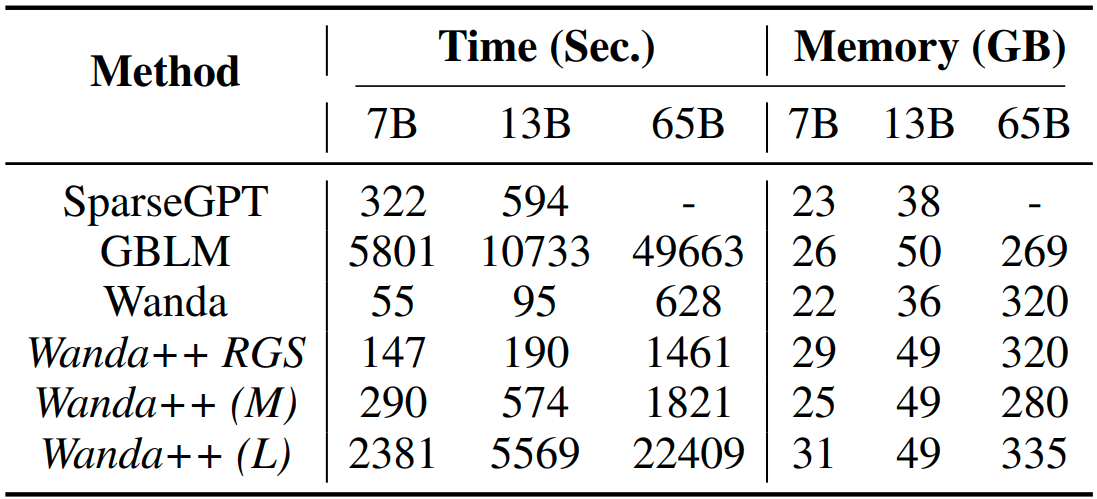
Time and memory. Table 3 compares pruning time and peak memory. Without weight updates, Wanda is fastest; Wanda++ RGS is next. Adding Regional Optimization increases time but stays in the same ballpark as SparseGPT. Crucially, memory usage for Wanda++ scales with the block hidden size, not total parameters. The authors estimate that even a massive block like those in MT NLG 530B could be optimized within the memory of a single 80 GB GPU given careful implementation. In practice, they prune 7B and 13B models in roughly 10 minutes and a 65B model in about 30 minutes with 4 H100s.
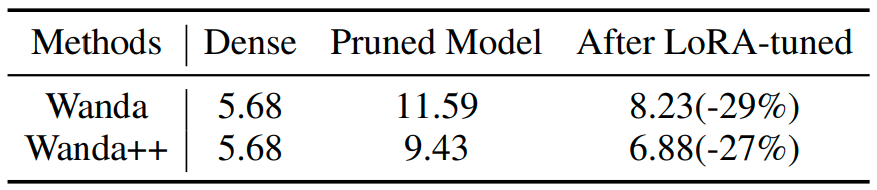
Compatibility with fine tuning. The authors fine tune pruned LLaMA 7B models with LoRA on the C4 dataset for 30k steps. Table 4 shows both Wanda and Wanda++ benefit similarly from LoRA, and Wanda++ preserves its relative advantage. This supports the claim that Wanda++ is orthogonal to sparsity aware fine tuning and can be combined with it when budgets allow ((Hu et al., 2021)).
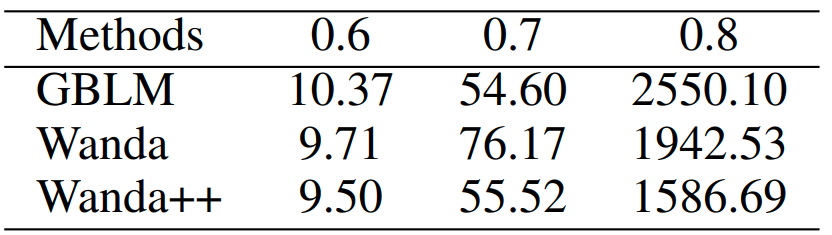
Higher sparsity and structured pruning. Table 5 explores unstructured sparsity up to 80 percent where Wanda++ still improves over baselines, though unstructured formats often lack runtime speed ups. Table 6 applies the idea to naive row wise structured pruning; Wanda++ SP outperforms Wanda SP, indicating the regional gradient and optimization concepts transfer beyond semi structured settings.
Edge cases to watch include very small calibration sets increase variance; scaling factor α for RGS is model specific (the paper finds a sweet spot around 50 to 100 on one model), and RO must be followed by a final RGS pruning pass to restore exact sparsity after updates.
Limitations and Practical Notes
The full Wanda++ framework is designed for unstructured and semi structured sparsity. While the authors show encouraging structured pruning results, they note the framework has not been fully tuned for structured regimes.
Regional Optimization is intentionally lightweight and may not correct extreme pruning errors under aggressive sparsity. Finally, although faster than end to end fine tuning, RO still adds wall clock time compared to pure scoring and masking methods.
Conclusion
Wanda++ offers an appealing midpoint between gradient free scoring and full model gradient pruning. By gathering gradients where they are cheap and meaningful, inside each decoder block, and pairing them with a minimal local alignment, it substantially improves perplexity at practical sparsity levels while keeping compute and memory budgets in check.
For teams targeting 2:4 on LLaMA class models, these results suggest Wanda++ style regional gradients and optimization are a sound default. When combined with modern deployment stacks like TensorRT LLM, the path from a pruned model to a faster service is clear.
Readers interested in compression can layer this with 4 bit weight quantization such as AWQ for additional gains ((Lin et al., 2024)). The paper appears in Findings of ACL 2025 and evaluates LLaMA and OpenLLaMA model families; if your workloads resemble those settings, the technique is worth a careful look.


Pruning LLMs With Regional Gradients: Inside Wanda++
Wanda++: Pruning Large Language Models via Regional Gradients