Wearables now collect rich sleep and activity data, but most users still struggle to translate those numbers into helpful actions. A new study in Nature Medicine presents the Personal Health Large Language Model (PH-LLM), a Gemini-based model finetuned to read multi-week, daily aggregated metrics and generate personalized sleep and fitness guidance.
The paper evaluates three capabilities: knowledge on standardized question banks, long-form recommendations from real case studies, and prediction of patient-reported sleep quality from daily sensor summaries.
PH-LLM targets a neglected gap between clinical LLMs and consumer dashboards: interpretable coaching grounded in routine, daily aggregates like total sleep time, sleep latency, wake after sleep onset, resting heart rate, and training load. Rather than diagnosing, the model aims to synthesize patterns and constraints into realistic suggestions that align with user goals while respecting safety and practicality.
Key takeaways
- PH-LLM is a finetuned Gemini model built for sleep and fitness coaching from multi-week, daily aggregated wearable metrics.
- On professional-style exams, PH-LLM reached 79% in sleep medicine and 88% in fitness, improving over the base model and matching or outperforming sampled human baselines in certain settings.
- Across 857 real-world case studies, expert raters judged PH-LLM's fitness coaching comparable to human experts; in sleep, it moved meaningfully closer to expert expectations versus the base model.
- For sleep, the model predicted patient-reported quality from daily aggregates with AUROC above naive baselines, indicating useful signal in routine summaries.
How the approach works
The model builds on Gemini Ultra 1.0 and is adapted in two stages: first for long-form generation on case-study prompts and then for sleep quality prediction using multimodal encodings of daily sensor summaries.
The case studies include demographics, up to 30 days of daily metrics, and aggregate statistics; fitness cases also include individual exercise logs. This framing keeps inputs compact and explainable, and it mirrors how a coach would scan trends over weeks rather than raw second-by-second streams.
Placing PH-LLM in context, general foundation models like Gemini are natively multimodal and strong across broad benchmarks. Domain adaptation has also been effective in clinical QA, for example Med-PaLM 2. PH-LLM extends that idea to longitudinal personal health signals, with an evaluation focused on coaching quality and personalization, not just answer accuracy.
Why this matters now
Wearables deliver a flood of numbers but few tailored narratives. Users need help interpreting micro-trends like rising resting heart rate, shifting bedtimes, or inconsistent training loads.
If a model can translate those patterns into safe, personalized guidance and pass expert scrutiny, it can lower the barrier to incremental behavior change. The use of daily aggregates is a practical compromise that supports transparency and privacy relative to sharing raw streams, although it may hide short-lived events and detailed temporal structure.
The study also raises prudent caveats. Patient-reported outcomes are subjective; AUROC should be viewed alongside calibration and class balance and generalization across device brands, demographics, and comorbidities remains a key question.
The evaluations emphasize expert ratings of practicality and safety, which is appropriate for coaching, but external replication and public datasets will be essential to stress-test robustness.
Reading the results

Figure 1 summarizes the three-part evaluation and headline numbers. Panel (a) depicts the overall setup: multiple-choice examinations, long-form recommendations from case studies, and prediction of sleep quality from daily aggregates. Panel (b) places PH-LLM against human experts and the base Gemini model, reporting bootstrapped confidence intervals and statistical tests. This helps contextualize progress against real expert expectations, not just model baselines.
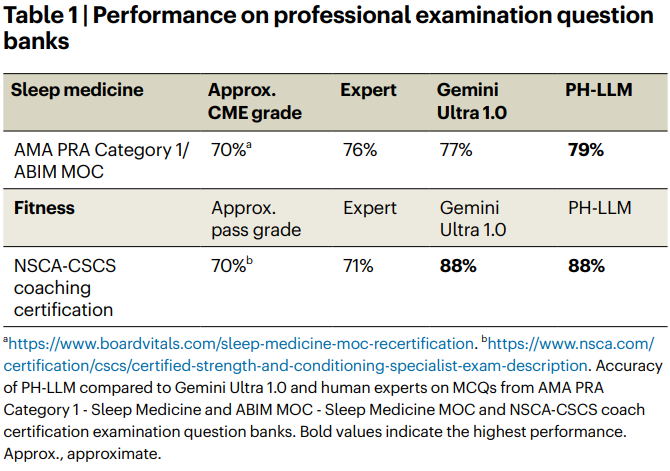
Table 1 reports accuracy on professional-style exam question banks in sleep medicine and in strength and conditioning coaching. Notably, fitness performance reaches 88%. For the fitness domain, the paper explicitly references the NSCA Certified Strength and Conditioning Specialist (CSCS) exam context; details of CSCS content and scoring are described by the National Strength and Conditioning Association.

Table 2 stratifies sleep exam results by difficulty tier, indicating that gains persist across question complexity. This matters because improvements limited to only easy items might inflate average accuracy without reflecting resilient domain knowledge. The paper also cross-checks broader medical QA tasks to ensure that specialty finetuning does not degrade general medical performance.
Beyond exams, the core contribution is the large-scale evaluation of coaching recommendations. The authors assembled 857 real case studies and collected thousands of expert ratings across principles and subsections. In fitness, PH-LLM's coaching quality was statistically similar to human experts; in sleep, it improved over the base Gemini and moved closer to expert expectations. The rubric emphasizes personalization, safety, and alignment to goals, which makes the ratings more informative than generic fluency scores.
Finally, for sleep quality prediction, the model produced AUROC above naive baselines on 833 survey responses, supporting the claim that daily summaries contain actionable signal about perceived sleep. While not a diagnostic outcome, this capability could help a coach model weigh subjective reports alongside objective aggregates when tailoring guidance.
What to watch next
Three fronts look especially important. First, richer temporal representations could capture mid-night awakenings, nap patterns, or intensity distribution within workouts that daily aggregates can smooth away. Second, broader and more diverse rater panels would strengthen conclusions about coaching quality, especially across age, sex, training status, and cultural context. Third, privacy-preserving pathways for deployment are crucial - including on-device inference for smaller models and careful governance when cloud services are involved.
The release of datasets, rubrics, and benchmarks is a welcome signal for reproducibility and comparability. If adopted widely, the combination of expert exams, case-based human ratings, and PRO prediction could become a transparent, multi-dimensional scoreboard for personal health LLMs.
Closing thoughts
PH-LLM offers a credible template for translating wearable data into coaching that feels specific, safe, and actionable. By pairing a general model with domain-targeted finetuning and expert-centric evaluation, the study shows human-comparable performance in meaningful contexts and outlines where limitations still matter. Researchers and product teams can use these rubrics and datasets to probe failure modes, quantify progress, and build more trustworthy systems for everyday health support.
Paper details: A personal health large language model for sleep and fitness coaching; Nature Medicine, 2025; DOI https://doi.org/10.1038/s41591-025-03888-0.


PH-LLM Turns Wearable Data into Practical Sleep and Fitness Coaching
A Personal Health Large Language Model for Sleep and Fitness Coaching