Chest X-rays are fast, cheap, and ubiquitous, but reading them well demands careful multi-structure reasoning. The paper PASS introduces a multimodal agentic system that treats chest X-ray (CXR) analysis as a probabilistic decision process over a graph of specialized tools.
Instead of a rigid pipeline or a monolithic vision-language model, PASS learns to sample tool sequences with explicit probabilities, producing transparent, auditable traces and an early-exit mechanism for efficiency. The work comes from The University of Hong Kong with authors Yushi Feng, Junye Du, Yingying Hong, Qifan Wang, and Lequan Yu.
In contrast to end-to-end models like GPT-4o and biomedical assistants such as LLaVA-Med or CheXagent, PASS argues that real clinical deployment needs interpretable steps, multimodal grounding, and adaptive computation. The system brings these together: a controller trained in three stages chooses which tool to call next, records uncertainty, and decides when to stop.
The authors also release a new benchmark, CAB-E, to evaluate multi-step, safety-critical CXR reasoning.
For background, see GPT-4o's capabilities and safety framing (OpenAI, 2024), CheXagent's radiology focus (Chen, 2024), agentic supernet design in MaAS (Zhang, 2025), and ReAct prompting (Yao, 2022), as well as the MIMIC-CXR dataset description (Johnson, 2019) and the SLAKE VQA benchmark (Liu, 2021).
Key takeaways
- PASS models clinical reasoning as probabilistic sampling over a graph of agent containers, each wrapping domain tools for segmentation, classification, grounding, VQA, reporting, guidelines, or knowledge graph lookup.
- The controller outputs per-step action probabilities, creating interpretable traces and enabling post-hoc audits that are essential for safety in medicine.
- A three-stage training curriculum aligns tool use to expert patterns, sharpens path preferences, and optimizes a cost-aware reward with an early-exit option.
- A new benchmark, CAB-E, targets multi-step, safety-critical chest X-ray queries with free-form answers and multimodal context.
- Results show higher accuracy and language fidelity than strong baselines while exposing a tunable cost-accuracy Pareto frontier.
How the approach works
PASS operates on a directed acyclic graph of agent containers, forming a supernet over medical tools. Each container has a standardized interface: a sub-query, an optional region-of-interest image, a slice of personalized context, and tool hyperparameters in; a payload plus logging in return.
The policy decides which container-tool pair to invoke next, with the option to terminate early. The final textual answer is generated by a fixed synthesis module conditioned on the collected evidence and trajectory.
Crucially, the system learns a task-conditioned distribution over trajectories. Given a question, image, and context, the controller samples an action at each step. The resulting path carries probability annotations per decision, which are interpretable and auditable in a clinical setting. This probabilistic structure also supports uncertainty estimation: answer entropy reflects variability from policy rollouts, not opaque generator changes.
Training proceeds in three stages.
- First, an expert warm-up uses behavior cloning from clinician-validated demonstrations to instill safe, clinically coherent patterns.
- Second, contrastive path ranking samples multiple candidate trajectories per case and optimizes the policy to prefer those scoring higher on heuristic rewards like guideline adherence and brevity.
- Third, cost-aware reinforcement learning directly maximizes a utility that balances task accuracy against a composite cost for latency, token usage, and privacy, with an entropy penalty to discourage uncertain answers in high-risk settings. This curriculum turns clinical priors into a policy that adapts depth and breadth of reasoning on demand.
Why this matters
Healthcare AI needs more than raw accuracy. Clinicians and regulators require traceability, stable behavior, and the ability to reason about what went wrong when it does. PASS's probability-annotated traces offer a compact way to review decision paths and audit the steps that led to an answer. That is a meaningful advance over monolithic black boxes that offer little insight into failure modes.
Adaptivity is equally critical as cases vary widely in complexity. A patient with previous imaging and clear findings may need fewer tool calls, while a complex ICU case may demand segmentation, grounding, guideline checks, and structured reporting.
PASS exposes a knob via the controller and early-exit mechanism that lets hospitals optimize for turnaround time, cost, or maximum fidelity depending on the clinical setting. This mirrors broader trends in agentic systems, such as supernet-based designs in MaAS (Zhang, 2025), but brings them into multimodal, safety-focused medicine.
What the figures and tables show
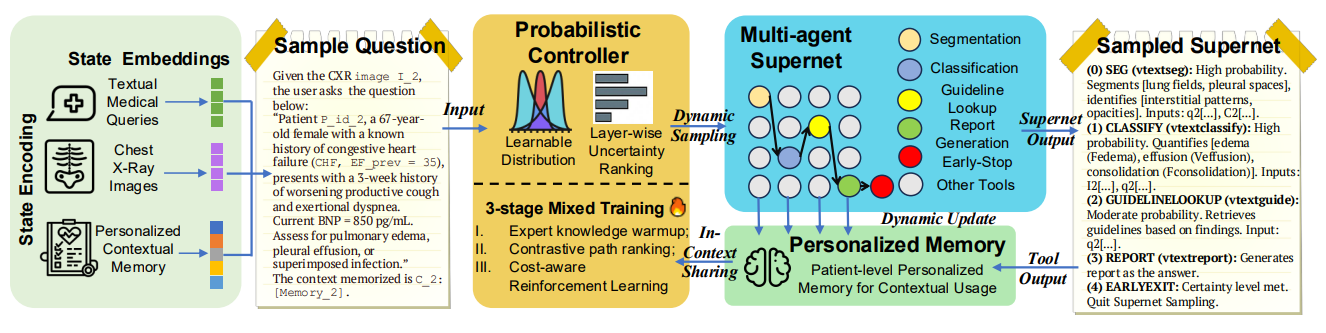
Figure 1: An overview of PASS. Given a multimodal complex reasoning task (CXR image, textual comprehensive query, multimodal personalized context), our probabilistic controller learns a continuous task-conditioned distribution over the agentic supernet (i.e. a directed acyclic graph of medical agent containers). At each step, it samples an action, yielding a workflow annotated with interpretable probabilities for post-audits and directly enhances clinical AI safety . Tool outputs, which can be both text and images, are summarized and fed into an evolving personalized memory and shared in-context to inform subsequent steps. The controller is trained via a principled three-stage strategy (expert knowledge warm-up, contrastive path ranking, cost-aware reinforcement learning) to optimize the accuracy-cost trade-off. Eventually, PASS is enabled to answer multimodal medical questions in free-form text via an interpretable, adaptive, and efficient agentic reasoning process.
Figure 1 is the system overview. It shows the controller sampling tool invocations over the medical supernet and annotating each choice with a probability. Outputs from tools are summarized and written to a bounded memory, which persists key findings across steps. The figure also highlights the three training phases that progressively align, rank, and refine the policy.
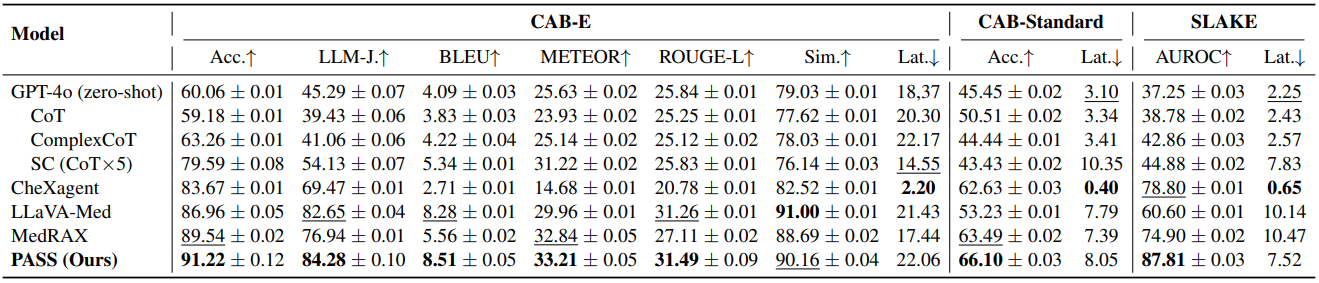
Table 1 reports main results across CAB-E, CAB-Standard, and SLAKE. On CAB-E, PASS tops accuracy and language metrics like LLM-as-a-Judge, BLEU, METEOR, and ROUGE-L. CAB-Standard confirms strong multiple-choice accuracy under latency constraints. On SLAKE, PASS leads AUROC while keeping latency competitive. The consistent gains suggest that adaptive multi-tool reasoning improves both correctness and textual fidelity over strong baselines including MedRAX and specialized VLMs.
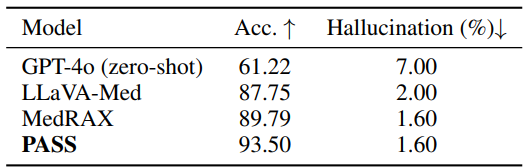
Table 2 focuses on 500 radiologist-verified safety-critical cases within CAB-E. PASS attains the highest accuracy and matches the lowest hallucination rate. This matters because safety splits stress real-world pitfalls, where conservative and auditable behavior counts as much as raw score.

Table 3 is an ablation study. Removing the early-exit mechanism increases cost substantially and hurts accuracy, indicating that dynamic depth control is not just a budget trick but contributes to better reasoning. Dropping the contrastive path-ranking and expert warm-up also degrades performance, showing that the three-stage curriculum is synergistic rather than optional.
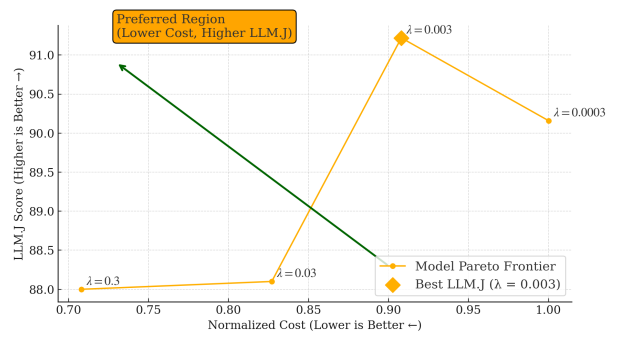
Figure 2 plots the cost-accuracy Pareto frontier. Each point reflects a policy configuration with different penalty weights. The frontier shows that PASS can trade cost for accuracy smoothly, instead of locking users into a single operating point. This is useful in practice: a screening clinic might choose a mid-cost configuration, while a tertiary-care setting might opt for the highest-fidelity regime with more steps and stricter audits.
Limitations and interpretation
PASS deliberately fixes the container set to preserve interpretability and safety. That choice limits flexibility but helps bound behavior. The authors note future scaling to other imaging modalities and enriched toolsets.
Another practical consideration is the dependency on a frozen answer generator, which simplifies learning but places a ceiling on language quality if the generator lags. Finally, while the CAB-E benchmark is a welcome step toward realistic evaluation, broad clinical validation will require prospective studies and integration with hospital systems.
Conclusion
PASS reframes medical agent reasoning as sampling a distribution over workflows rather than following a single rigid script. Its probability-annotated traces, early exits, and three-stage training provide a credible path toward systems that are both capable and accountable.
The results across CAB-E, CAB-Standard, and SLAKE suggest that adaptive, multimodal tool use can outperform monolithic or static pipelines, while offering clinicians visibility into how answers are produced. Readers interested in agentic supernets, medical VLMs, or clinical AI safety will find PASS a timely and practical contribution. See the paper and consider testing the code once it is available.


PASS Puts Probabilities on Agentic Workflows for Safer, Adaptive Chest X-ray AI
PASS: Probabilistic Agentic Supernet Sampling for Interpretable and Adaptive Chest X-Ray Reasoning