Imagine trying to build an AI system that truly understands human language not just in English, but in over 7,000 languages spoken worldwide. For years, this seemed like an impossible task. While encoder models like BERT revolutionized English language understanding, creating truly multilingual systems remained elusive. Most attempts either favored high-resource languages like English and Chinese, or struggled to effectively incorporate the world's diverse linguistic landscape.
Now, researchers at Johns Hopkins University have achieved a breakthrough that changes this narrative entirely. Their new model, mmBERT, successfully learns to understand 1,833 languages using an innovative training approach called "annealed language learning."
Published as an arXiv preprint, this work demonstrates how to efficiently teach an AI system thousands of languages while maintaining strong performance on major languages (Marone et al., 2025).
The timing is crucial. While decoder-only models like GPT-4 dominate headlines for text generation, encoder-only models like BERT remain essential for understanding tasks such as classification, search, and information retrieval. These applications power everything from customer support systems to scientific literature analysis. mmBERT represents the next generation of these models, one that could finally bring advanced language AI to speakers of underrepresented languages worldwide.
Encoder-only models like BERT and RoBERTa once dominated natural language understanding. In recent years, decoder-only large language models eclipsed them in attention. Yet for classification, retrieval, and embedding-heavy workloads, encoders remain compelling for efficiency.
mmBERT aims to supersede the long-standing multilingual baselines, mBERT and especially XLM-R, by combining stronger data pipelines, a long-context architecture descended from ModernBERT, and a training curriculum that “anneals” languages across phases (Conneau et al., 2019; Warner et al., 2024).
Key Takeaways
- Revolutionary Training Approach: mmBERT uses "annealed language learning" to introduce languages in three phases (60 → 110 → 1,833), with temperature sampling that shifts from high-resource bias to uniform distribution, dramatically boosting low-resource language performance.
- Adaptive Masking Strategy: Unlike traditional BERT training with fixed 15% masking, mmBERT uses an "inverse masking schedule" that decreases masking ratios over training phases, improving learning efficiency while maintaining model generality.
- Benchmark Domination: mmBERT-base surpasses XLM-R and other multilingual encoders on GLUE, XTREME, and MTEB v2 benchmarks, proving that 1,800+ language support doesn't compromise performance on major languages (Wang et al., 2018; Hu et al., 2020; Enevoldsen et al., 2025).
- Dramatic Low-Resource Gains: Adding 1,700+ languages only in the final training phase yields massive F1 score improvements, Faroese (FoQA) and Tigrinya (TiQuAD) see substantial boosts despite minimal exposure, proving the effectiveness of the annealing strategy (Simonsen et al., 2025; Gaim et al., 2023).
- Production-Ready Efficiency: Built on ModernBERT's optimized architecture with FlashAttention 2 and unpadding techniques, mmBERT handles 8,192-token contexts with exceptional throughput, making it practical for real-world deployment (Warner et al., 2024).
The Data Behind the Magic
Creating a truly multilingual model requires more than just gathering text in different languages, it demands a sophisticated data curation strategy. mmBERT's training corpus represents a carefully balanced mixture of high-quality sources, with different datasets prioritized in different training phases.
For English content, the researchers relied on filtered web text from datasets like DCLM, ensuring high quality while maintaining scale. Multilingual data comes primarily from FineWeb2 and FineWeb2-HQ, representing some of the cleanest and most diverse web-scraped text available. (Penedo et al., 2025)
The corpus extends beyond web text to include books, mathematical content, code repositories, and Wikipedia articles from specialized datasets like Dolma and MegaWika. This diversity is intentional as different types of text teach different aspects of language understanding. (Soldaini et al., 2024)
Mathematical texts help with logical reasoning, code helps with structured thinking, and books provide narrative understanding. While English content comprises a larger proportion than in older multilingual models like XLM-R, this reflects the current reality of available high-quality text data rather than a bias toward English.
The Three-Phase Training Recipe
mmBERT's success lies in its carefully orchestrated three-phase training approach, designed to efficiently scale from dozens to thousands of languages.
The journey begins with:
Phase 1: Foundation Building, where the model trains on 2.3 trillion tokens across approximately 60 high-resource languages. This phase establishes robust cross-lingual representations and core language understanding capabilities using a high masking ratio to encourage broad contextual learning.
Phase 2: Context Extension serves as a crucial bridge, expanding the model's context window capabilities while gradually introducing around 110 languages. Here, the masking ratio begins to decrease, allowing the model to process longer, more complete sequences.
Phase 3: The Annealing Phase represents the breakthrough innovation adding over 1,700 additional languages while dramatically reducing the masking ratio and flattening the language sampling distribution. This phase proves that massive linguistic diversity can be efficiently incorporated in the final stages of training.
Architecturally, mmBERT builds on the robust foundation of ModernBERT, incorporating state-of-the-art optimizations that make it production-ready. Key technical features include Rotary Position Embeddings (RoPE) for superior long-sequence handling, sliding-window global attention to manage computational costs, and support for contexts up to 8,192 tokens.
The model uses the Gemma tokenizer, specifically chosen for its exceptional coverage of diverse scripts and character systems across the world's languages (Warner et al., 2024). With approximately 307 million parameters, the base model dedicates significant capacity to its extensive vocabulary, a design choice that proves crucial for multilingual coverage.
Two Revolutionary Training Innovations
mmBERT's breakthrough comes from two key training innovations that work synergistically. The first innovation, inverse masking, challenges the conventional wisdom of BERT-style training. Traditional masked language modeling uses a fixed 15% masking ratio throughout training. mmBERT starts with a higher masking ratio and progressively decreases it across phases. Think of this like learning to read: early in training, the model sees text with many words hidden, forcing it to develop broad contextual understanding. Later, with fewer words masked, it refines its understanding with more complete information.
The second innovation, cascading annealed language learning, represents a paradigm shift in multilingual training. Rather than training on all languages simultaneously from the start, mmBERT introduces languages in carefully planned waves.
Crucially, the "temperature" of language sampling is also annealed, starting with sampling that heavily favors high-resource languages and gradually flattening to more uniform sampling across all languages. This strategy allows the model to build a strong multilingual foundation first, then efficiently transfer that knowledge to thousands of low-resource languages in a targeted final phase.
The results speak for themselves: languages like Faroese and Tigrinya, which appear only in the final phase, show dramatic performance improvements despite minimal exposure.
Transforming Real-World Language Applications
The distinction between encoder and decoder models matters enormously in practical applications. While decoder-only models like GPT-4 excel at generating human-like text, encoder models like mmBERT are optimized for understanding and representing text thus making them ideal for classification, search, and retrieval tasks that power much of the modern internet. mmBERT's multilingual capabilities open up entirely new possibilities for global applications.
Consider a multinational corporation managing customer support across dozens of countries. Traditional approaches require separate models or extensive translation pipelines for each language. mmBERT enables a single system that can automatically classify incoming support tickets by topic and urgency across 1,833 languages, routing them to appropriate teams regardless of the customer's native language. The model's strong performance on retrieval tasks means it can power semantic search systems that understand user intent across linguistic boundaries for example a user searching in Hindi can find relevant results originally written in Spanish or Arabic.
For e-commerce platforms operating globally, mmBERT could revolutionize product discovery. Instead of relying on keyword matching that fails across languages, the model can understand product descriptions and user queries semantically, connecting buyers with relevant products regardless of language barriers.
News organizations can leverage mmBERT to automatically categorize and analyze global news feeds, identifying trending topics and emerging stories across different regions and languages in real-time.
A Step Toward Digital Linguistic Equity
Perhaps most importantly, mmBERT represents a significant step toward digital linguistic equity. Currently, speakers of major languages like English, Chinese, and Spanish have access to sophisticated AI-powered tools, while speakers of smaller languages are largely excluded from the digital AI revolution. This digital divide affects over half the world's population, limiting access to AI-powered education, healthcare information systems, and economic opportunities.
mmBERT's training approach offers a practical roadmap for changing this dynamic. The dramatic performance improvements on languages like Faroese and Tigrinya (languages spoken by small communities that received minimal training data) demonstrate that effective multilingual AI doesn't require massive datasets for every language.
Instead, the annealed learning approach shows how cross-lingual transfer can efficiently extend advanced AI capabilities to underrepresented communities. This has profound implications for building more equitable AI systems that serve all of humanity, not just speakers of popular languages.
Benchmark Performance That Speaks Volumes
The proof of mmBERT's effectiveness lies in its comprehensive benchmark performance across multiple evaluation frameworks. On the GLUE benchmark, the gold standard for English language understanding, mmBERT-base performs competitively with dedicated English-only models like ModernBERT. This is remarkable because it demonstrates that supporting 1,833 languages doesn't compromise performance on high-resource languages, a common concern with multilingual models.(Wang et al., 2018)
Even more impressive are the results on XTREME, the premier multilingual evaluation benchmark covering classification and question-answering across diverse languages. mmBERT consistently outperforms previous multilingual champions like XLM-R and mGTE, models that have dominated the field for years.
On the MTEB v2 benchmark, which evaluates text embedding quality across retrieval, clustering, and classification tasks, mmBERT approaches MonolithBERT's English performance while leading all multilingual competitors (Enevoldsen et al., 2025).
Breaking Down the Numbers
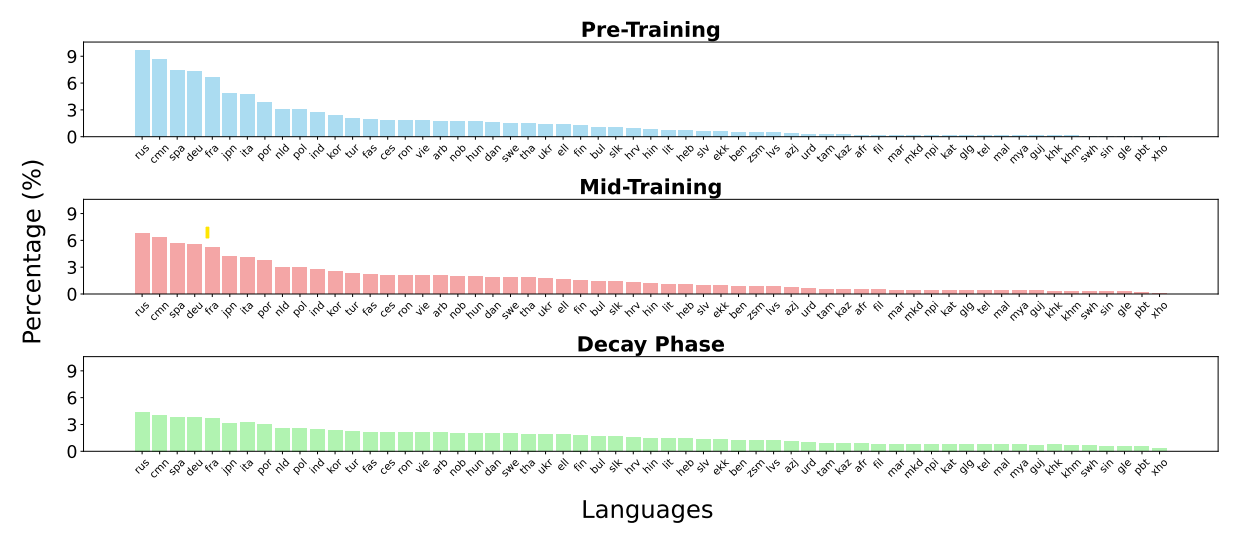
Figure 1: inverse temperature sampling ratio throughout training from Fineweb2 data, from τ of 0.7 to 0.5 to 0.3. Note that other sources are excluded from this chart and are not temperature sampled. For full language percent details, see Appendix D. Training starts out more high-resource biased but becomes increasingly uniform. Also included are another 50 languages in mid-training and 1723 more for the decay phase not visualized. Credit: Marone et al., 2025
The research paper provides rich detail about mmBERT's performance thoroughly. The training data composition (detailed in the paper's Table 1) reveals a strategic evolution toward higher-quality datasets in later training phases. This progression, combined with the inverse masking schedule, contributes significantly to the model's sample efficiency while getting more learning from each training example.
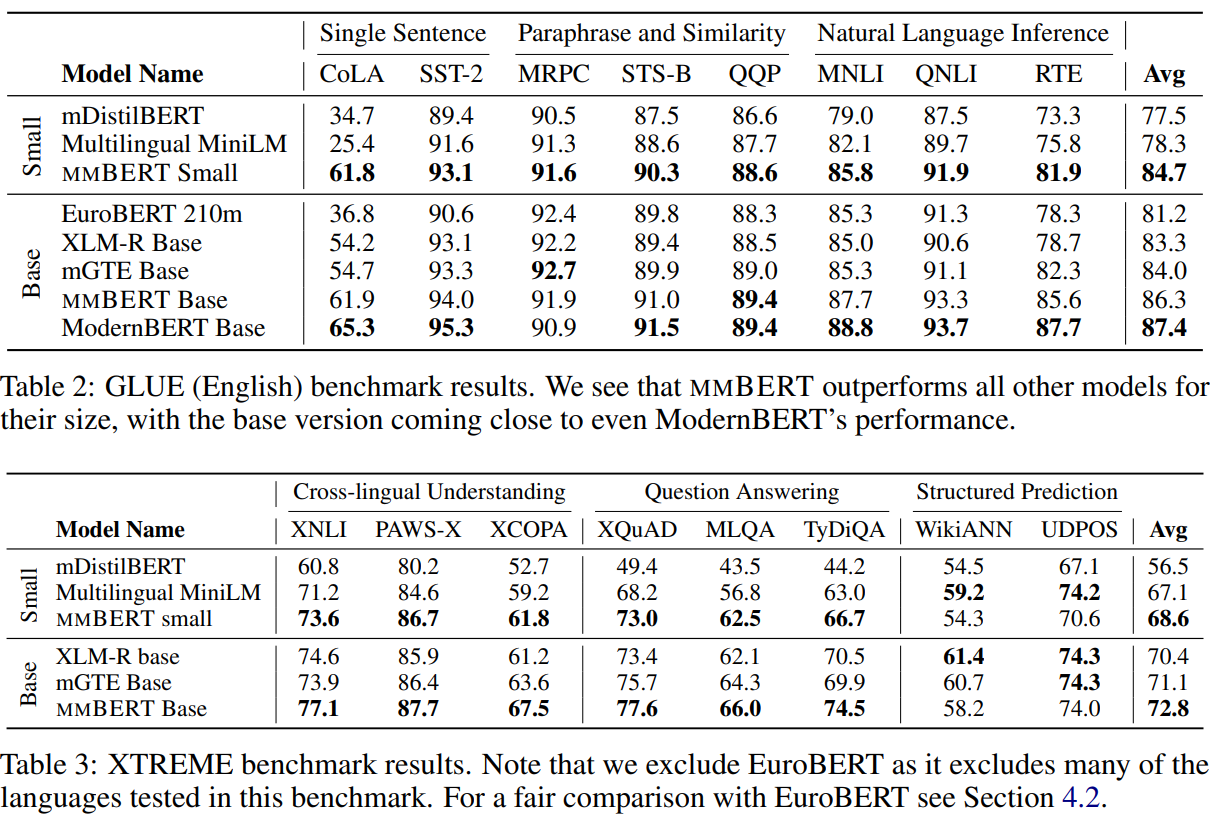
Performance tables for GLUE and XTREME benchmarks provide compelling evidence of mmBERT's superiority over existing multilingual models. The authors transparently note some performance gaps on structured prediction tasks like part-of-speech tagging and named-entity recognition, suggesting that tokenization choices may need refinement providing valuable honesty that could help guide future research directions.
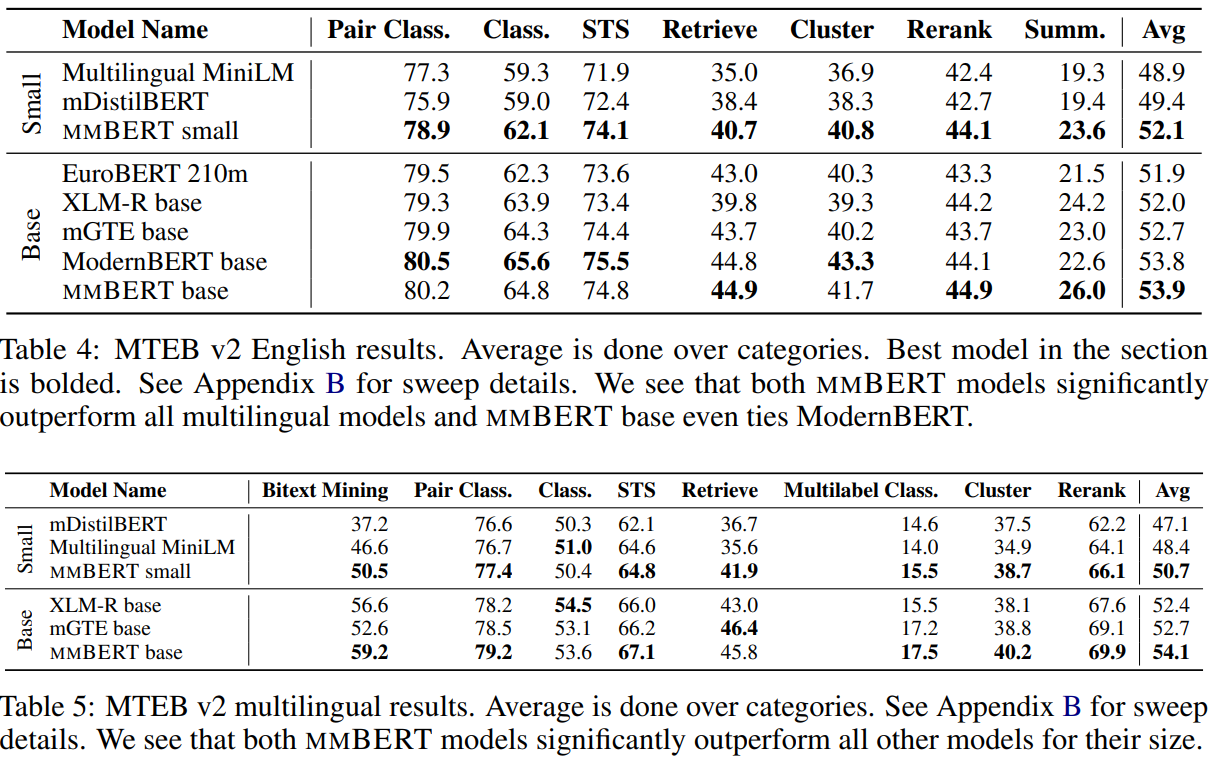
The MTEB v2 results confirm mmBERT's strength in creating high-quality text embeddings, a crucial capability for search and retrieval applications. Tables 4 and 5 (MTEB v2) confirm that mmBERT is a powerful tool for creating text embeddings for both English and multilingual retrieval tasks. This is a key advantage of encoder models, which are designed to produce rich, meaningful representations of text.
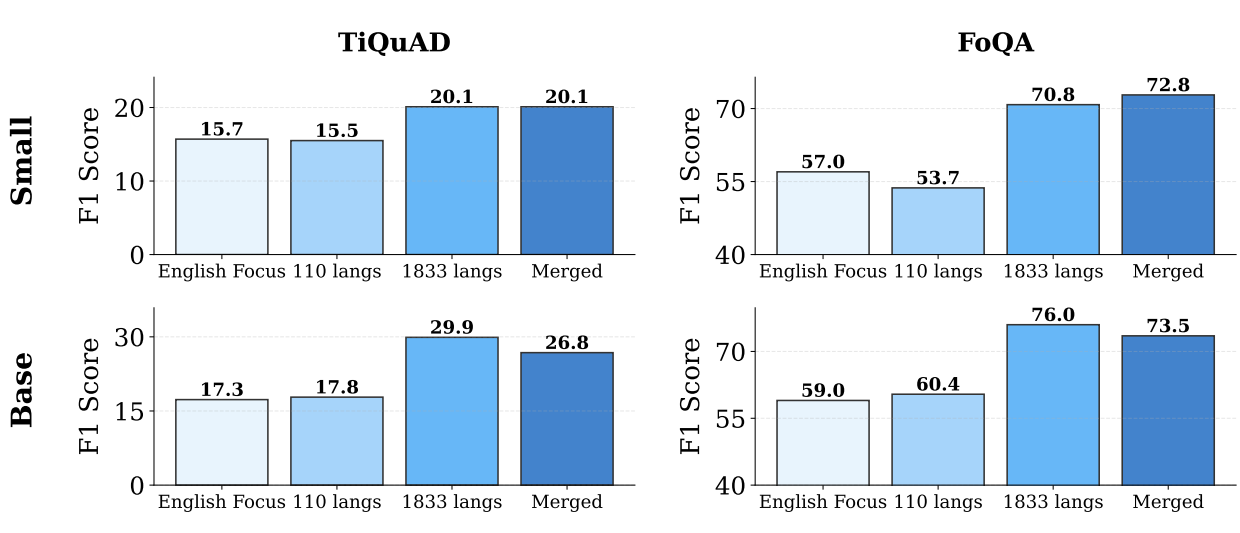
Figure 2: Performance of models using different decay phases on two languages (Tigray and Faroese) only added during the decay phase. We see that MMBERT with the 1833 language decay phase shows rapid performance improvements despite only having the models in the last 100B tokens of training. The final MMBERT models shows improvements by merging together checkpoints. Credit: Marone et al., 2025
Perhaps most striking are the visualizations showing the impact of annealed language learning. Figure 2 in the original paper demonstrates dramatic F1 score improvements for low-resource languages like Faroese and Tigrinya, providing compelling visual evidence that the annealing strategy works.
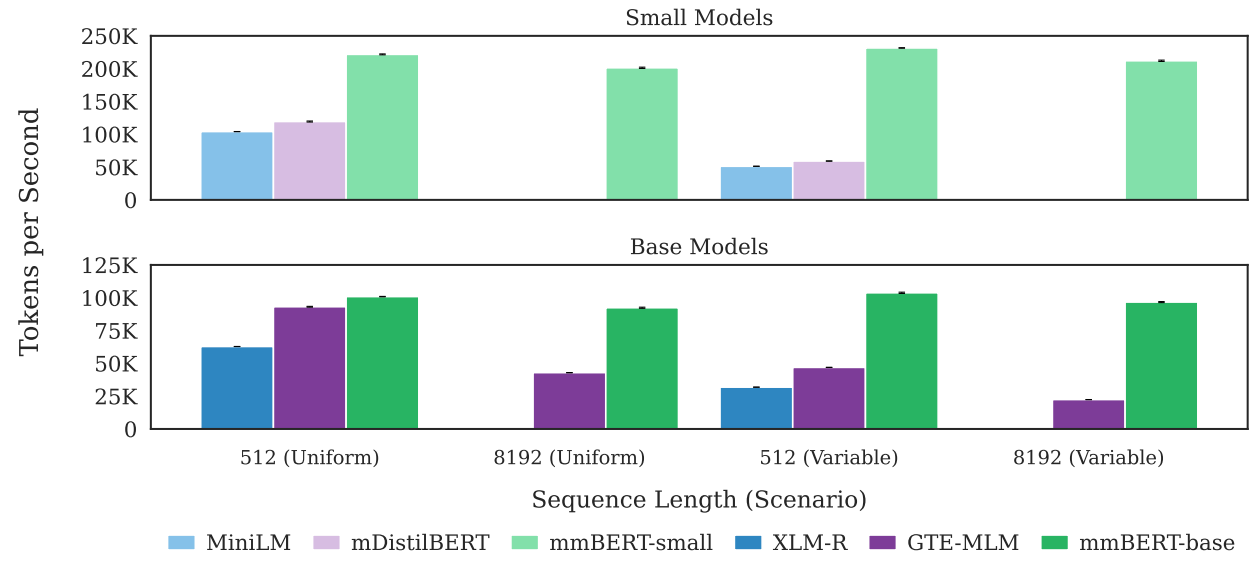
Figure 3: Throughput efficiency for various sequence lengths and variable input length (top row is small models, bottom row is base models). MMBERT is more efficient because of the use of Flash Attention 2 and unpadding techniques it inherits from ModernBERT. Empty bars indicate that the model cannot use a sequence length greater than 512. Error bars show standard error over five seeds. 8 and significantly faster on long context lengths (∼ 4x). For MMBERT small results are roughly 2x faster than MMBERT base and again roughly 2x faster than similarly-sized other multilingual models. We note that previous multilingual models such as MiniLM and XLM-R cannot go past 512 tokens whereas MMBERT can perform at up to 8192 tokens – and can do so as fast as other models at 512. Credit: Marone et al., 2025
Figure 3 showcases mmBERT's computational efficiency, with throughput measurements that prove the model's practicality for production deployments. These performance characteristics, inherited from ModernBERT's optimizations like FlashAttention 2, make mmBERT not just a research breakthrough but a practical tool for real-world applications.
Current Limitations and Future Horizons
While mmBERT represents a significant breakthrough, the researchers acknowledge several areas for improvement that point toward exciting future research directions. The most notable limitation appears in structured prediction tasks like named-entity recognition and part-of-speech tagging, where performance lags behind specialized models. This gap likely stems from tokenization choices as the Gemma tokenizer, while excellent for general multilingual coverage, may not optimally handle the fine-grained token-level decisions required for these tasks.
Another consideration is the computational cost of training such a massive multilingual model. While the final model is efficient for inference, the training process required substantial computational resources across three carefully orchestrated phases. This raises questions about the accessibility of such training approaches for smaller research groups or organizations, though the authors' commitment to open-sourcing their work helps democratize access to the final models.
Looking ahead, several exciting research directions emerge from this work. Future iterations could explore more sophisticated tokenization strategies tailored for different language families, investigate the optimal number of languages to include in each training phase, and examine how the annealing approach might transfer to even larger model scales.
The success with 1,833 languages also raises the tantalizing possibility of truly universal language models that cover all of the world's 7,000+ languages, a goal that mmBERT brings significantly closer to reality.
The Future of Multilingual AI Is Here
mmBERT represents a proof of concept for how AI can serve all of humanity's linguistic diversity. By demonstrating that a single model can effectively understand 1,833 languages while maintaining competitive performance on major languages, the Johns Hopkins team has fundamentally shifted our understanding of what's possible in multilingual AI. The annealed language learning approach provides a practical blueprint that other researchers can build upon, potentially accelerating progress toward truly universal language understanding.
The model's strong performance across diverse benchmarks, combined with its production-ready efficiency, makes it immediately valuable for practitioners building multilingual applications. Whether you're developing customer support systems, search engines, or content analysis tools, mmBERT offers capabilities that were simply unavailable before. The authors' decision to open-source their models and training recipes ensures that these advances will benefit the broader research community and accelerate further innovations in the field.
Perhaps most importantly, mmBERT moves us closer to a future where language is no longer a barrier to accessing advanced AI capabilities. As we stand on the brink of an AI-powered transformation of human society, ensuring that this transformation includes speakers of all languages, not just the most well-resourced ones, becomes both a technical challenge and a moral imperative. mmBERT shows us that this inclusive future is not just desirable but achievable.
Key Terms and Concepts Explained
Encoder-Only Model: A neural network architecture (like BERT) designed to understand and represent text rather than generate it. These models excel at tasks requiring text understanding for classification, search, sentiment analysis, and creating meaningful embeddings that capture semantic meaning.
Decoder-Only Model: A neural network architecture (like GPT) designed to generate text by predicting the next word in a sequence. These models excel at creative writing, translation, summarization, and conversational AI applications.
Annealed Language Learning: A training curriculum that introduces languages in phases while gradually adjusting sampling temperature. Early phases focus on high-resource languages with biased sampling, later phases include more languages with uniform sampling, enabling efficient knowledge transfer to low-resource languages.
Inverse Masking Schedule: A training technique that starts with high masking ratios (hiding more words) and gradually decreases them. This encourages broad contextual learning early, then fine-tunes understanding with more complete information later in training.
Cross-Lingual Transfer: The ability of a multilingual model to apply knowledge learned from one language to understand another language, even with limited training data in the target language.
XTREME: Cross-lingual Transfer Evaluation of Multilingual Encoders is a comprehensive benchmark suite covering classification and question-answering tasks across dozens of languages (Hu et al., 2020).
MTEB v2: Massive Text Embedding Benchmark is a large-scale evaluation framework testing models' ability to create meaningful text representations across retrieval, clustering, and classification tasks (Enevoldsen et al., 2025).
ModernBERT: An optimized encoder architecture featuring FlashAttention 2, unpadding techniques, and other efficiency improvements that enable high-throughput processing of long sequences (Warner et al., 2024).
Get Started With mmBERT
Ready to explore mmBERT's capabilities in your own projects? The Johns Hopkins team has made their models and training recipes openly available to the research community. Whether you're building multilingual applications, conducting cross-lingual research, or simply curious about the future of language AI, mmBERT provides an unprecedented opportunity to work with a truly multilingual understanding system. Check out the official repository below to access pre-trained models, implementation details, and comprehensive documentation.



mmBERT: How Johns Hopkins Built a 1,833-Language AI That Outperforms XLM-R
mmBERT: A Modern Multilingual Encoder with Annealed Language Learning