The Model Context Protocol (MCP) has quickly become a common interface for connecting large language models to external tools and data. By design, it looks like a USB-C port for AI applications: a standard plug that lets agents access many servers and capabilities with a consistent contract. MCP-Universe evaluates models as agents that operate against real MCP servers, real APIs, and time-varying tasks. The project includes an open-source evaluation framework, a public leaderboard, and a website with documentation (Salesforce AI Research, 2025; MCP-Universe Website, 2025).
Key Takeaways
- Real servers, not stubs: 231 tasks across six domains and 11 MCP servers measure end-to-end agent performance.
- Execution-based grading: Format, static, and dynamic evaluators check results without relying on an LLM-as-judge .
- Frontier models still struggle: The best overall success rate reaches about 43.72% on the leaderboard (MCP-Universe Leaderboard, 2025).
- Two central hurdles: Long context accumulation across steps and unfamiliar tool interfaces are dominant error sources.
- Agent frameworks matter: Enterprise-style agents do not consistently beat a well-tuned ReAct baseline in this setting.
Overview
MCP-Universe evaluates agents in six domains: Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching.
- Location Navigation: Leveraging the official Google Maps MCP server, this domain tests an agent's ability to perform geographic and spatial reasoning for tasks like route planning and distance calculation using real-world location data.
- Repository Management: This domain utilizes the GitHub MCP server to assess an agent's proficiency in codebase operations, including repository searches, issue tracking, and code editing, mirroring authentic developer workflows.
- Financial Analysis: With the Yahoo Finance MCP server, agents are challenged with quantitative reasoning and decision-making based on live financial data, including monitoring stock prices and tracking options.
- 3D Designing: Agents interact with the Blender MCP server to perform computer-aided design tasks. This includes using advanced tools for 3D modeling, such as creating objects and manipulating assets.
- Browser Automation: The Playwright MCP server provides a platform for agents to demonstrate their capabilities in web automation. This involves tasks like navigating websites, clicking buttons, and taking page snapshots to simulate real-world browser control scenarios.
- Web Searching: This domain focuses on open-ended information retrieval. It integrates the Google Search MCP server for web searches and the Fetch MCP server to obtain content from specific URLs, reflecting the nature of real-world web searching.
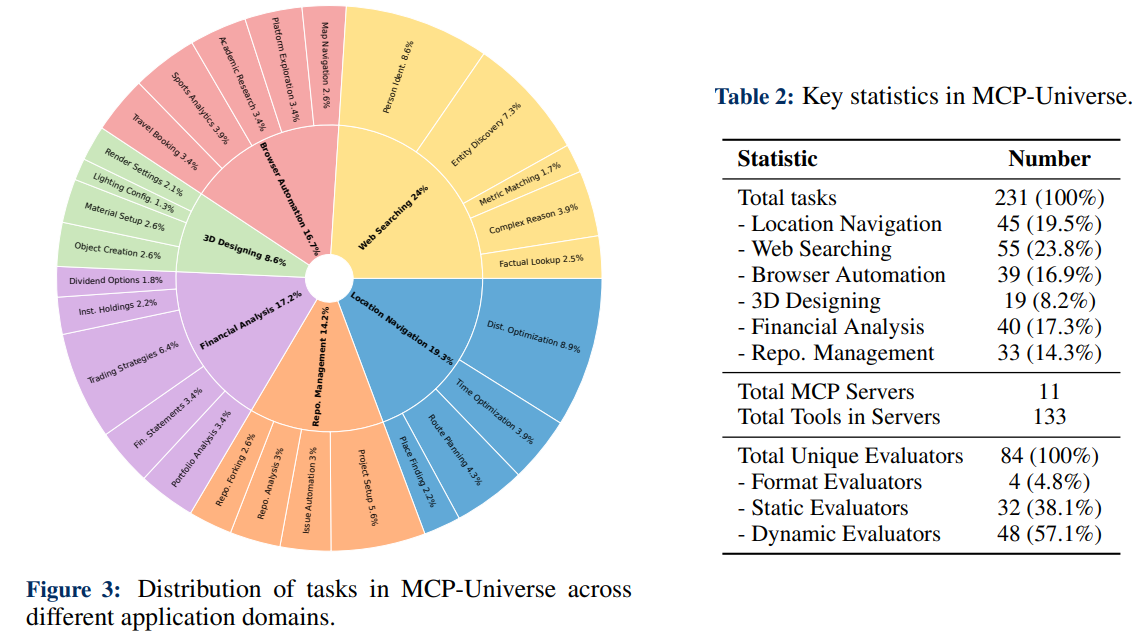
The benchmark aggregates 231 tasks that require interacting with 11 different MCP servers and, in total, 133 tools. Unlike static datasets, many tasks have real-time or time-variant answers, so the authors avoid using an LLM-as-judge and instead emphasize automated execution checks.
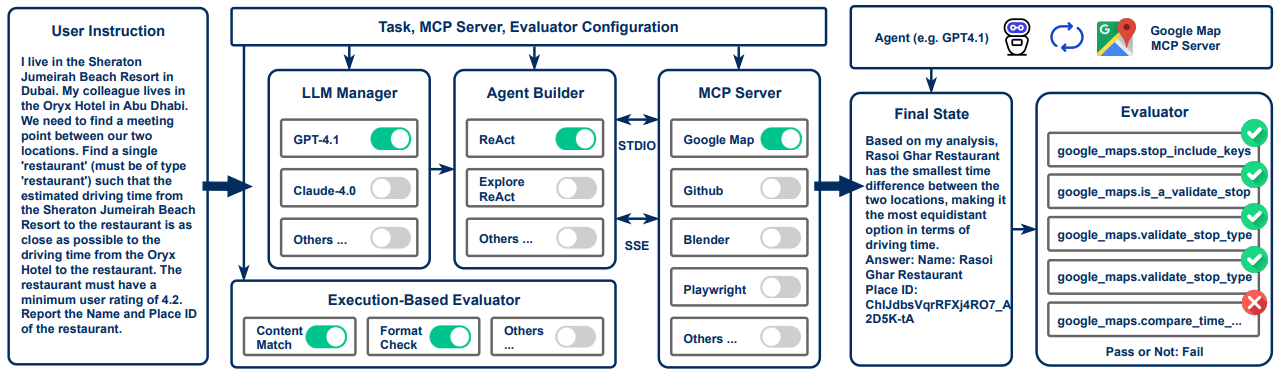
Figure 2: Overview of the MCP-Universe evaluation framework. The framework dynamically configures LLM agents, MCP servers, and execution-based evaluators according to task specifications. Each evaluation involves the agentserver interactions mediated via the MCP protocol, followed by an objective assessment conducted by automated execution-based evaluators to determine the success of task completion. Credit: Luo et al.
The framework architecture (Figure 2) wires together model selection, agent logic (e.g., ReAct), server connectivity, and evaluator configuration. Each evaluation runs an agent through multi-turn tool calls over the MCP protocol and then verifies completion with the associated evaluators.
This design makes the system extensible: new servers and tasks can be added, and researchers can swap in different agent policies and LLMs while holding the rest constant (Salesforce AI Research, 2025).
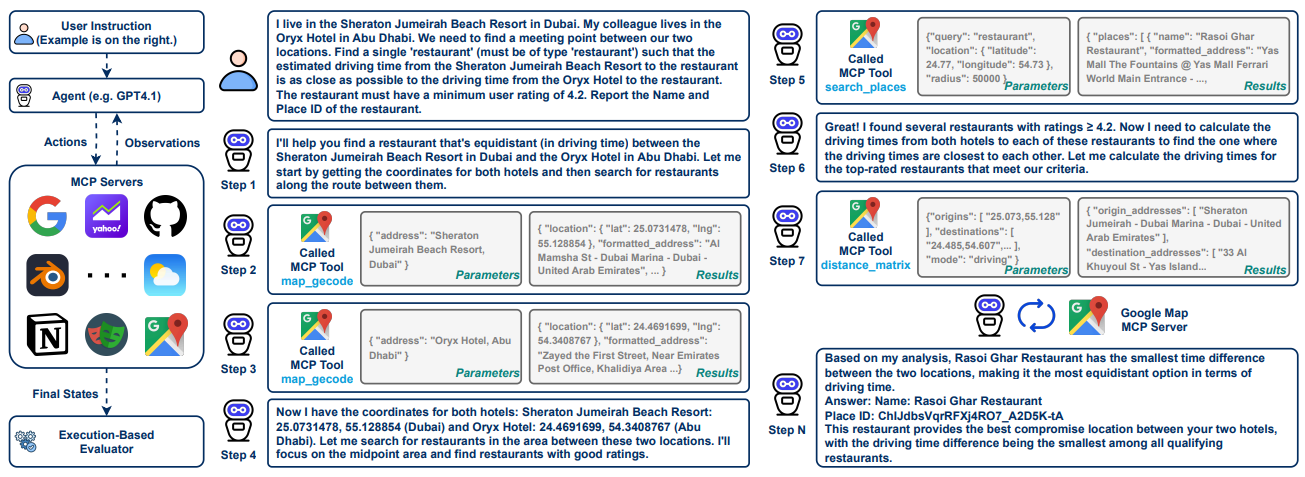
Figure 1: Example from MCP-Universe illustrating realistic challenges, including real-world tool usage, long-horizon multi-turn tool calls, long context windows, scattered evidence, and large tool spaces. Unlike prior work, MCPUniverse is grounded in real-world MCP servers connected to actual data sources and environments. Credit: Luo et al.
Figure 1 illustrates the experience from the agent’s point of view: long-horizon planning, scattered evidence collection, and repeated tool calls to get from vague instructions to verifiable answers.
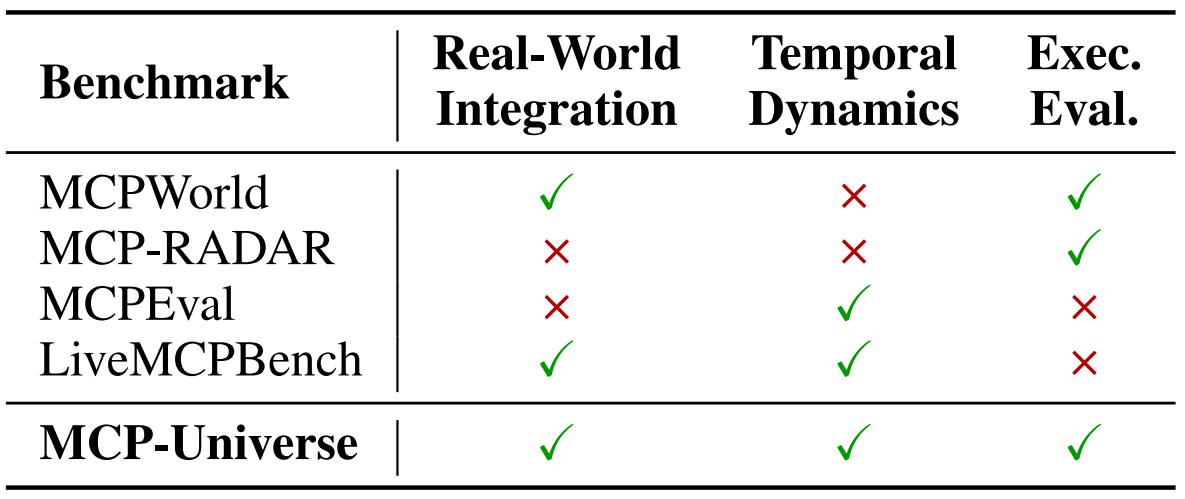
Table 1 positions MCP-Universe among related benchmarks, highlighting three properties that are often missing in prior work: real-world integrations, temporal dynamics, and execution-based evaluation. Credit: Luo et al.
Why It Matters
Tool-using agents are leaving the lab and operating in production environments: editors, browsers, data pipelines, CRM systems, financial dashboards, and more. MCP offers a standard bridge for that integration. A benchmark that exercises this bridge with authentic servers is valuable for three reasons.
- First, it forces models to handle realistic failure modes like flaky APIs, incomplete docs, and ambiguous parameters.
- Second, it stresses long-horizon reasoning where context grows across steps and the agent must summarize or retrieve its own history.
- Third, it surfaces cross-domain gaps: a model that is strong on repository operations may falter on geospatial queries or browser flows.
By reporting success rates along with average evaluator scores and step counts, the leaderboard gives a compact readout of both effectiveness and process efficiency.
The headline results show that even top proprietary models do not yet achieve robust performance, leaving room for improved planning, memory, and tool-competence training (MCP-Universe Leaderboard, 2025).
Discussion
The benchmark reveals that even SOTA (state-of-the-art) language models struggle with real-world MCP environments, with the best-performing models achieving only 43.72% overall success rate.
Models show significant cross-domain variation, performing better on structured tasks like financial analysis but struggling with complex multi-step scenarios like browser automation.
From this evaluation two fundamental challenges emerge: long-context degradation as conversation history grows, and difficulty with unfamiliar tool interfaces where agents must discover proper parameter usage on the fly.
Surprisingly, enterprise-level agent frameworks do not consistently outperform well-tuned ReAct baselines, suggesting that orchestration complexity can hinder rather than help performance.
Now let's take a look at what the results say.
The current Leaderboard shows that MCP tools are best used by closed source frontier models such as GPT-5 and Claude 4. Perhaps as expected we see a grouping of open source and closed source models basically falling into two categories in terms of tool calling performance. (Leaderboard, 2025)
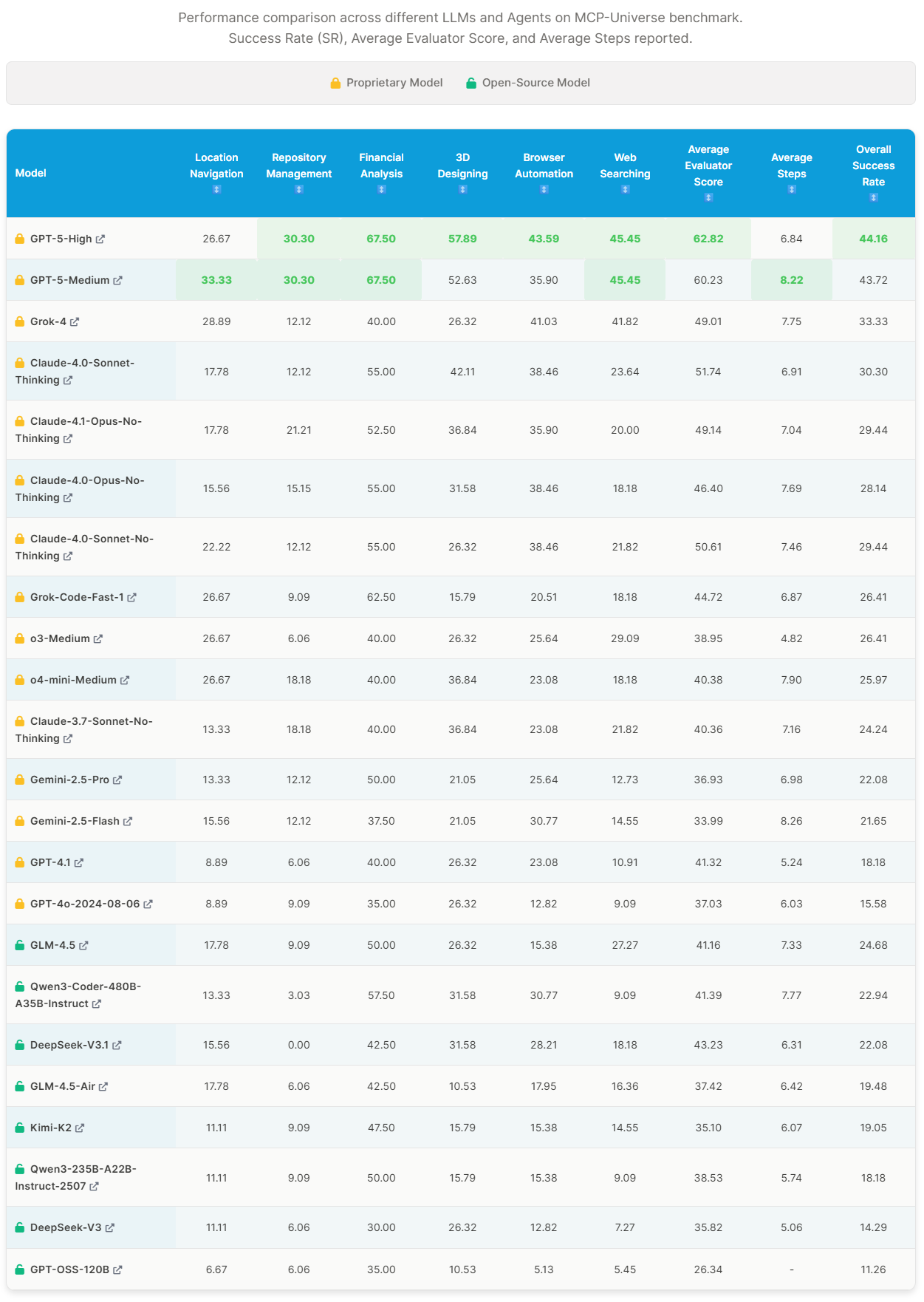
What is most notable to me is the difference between the latest SOTA models and recent reasoning models. We see GPT-5 has taken the lead even over reasoning models like 03 and DeepSeek R and V versions. I expect this can be interpreted as the evolution of the models training, since we are introducing MCP and only recently starting to train models on efficient usage. As training improves and access to documentation increases I expect we will see a tightening of this leaderboard and hopefully even a shift of open source models towards better performance across the board.
We have reviewed the current state of MCP tool performance from the leaderboard dated Sept. 5 2025. Now let's dive back into the publication and see what results the authors have detailed.
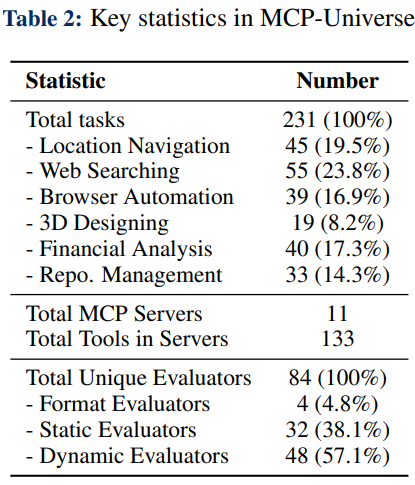
Benchmark design and scale. Table 2 summarizes benchmark scale: 231 tasks, 11 MCP servers, and 133 tools. The authors design three evaluator types to keep scoring objective. Format evaluators check that the agent returns outputs in the required structure. Static evaluators compare against ground truth that does not change over time (for example, a historical financial value). Dynamic evaluators fetch real-time answers for time-sensitive queries such as flight prices, current weather, or open issue counts and compare programmatically.
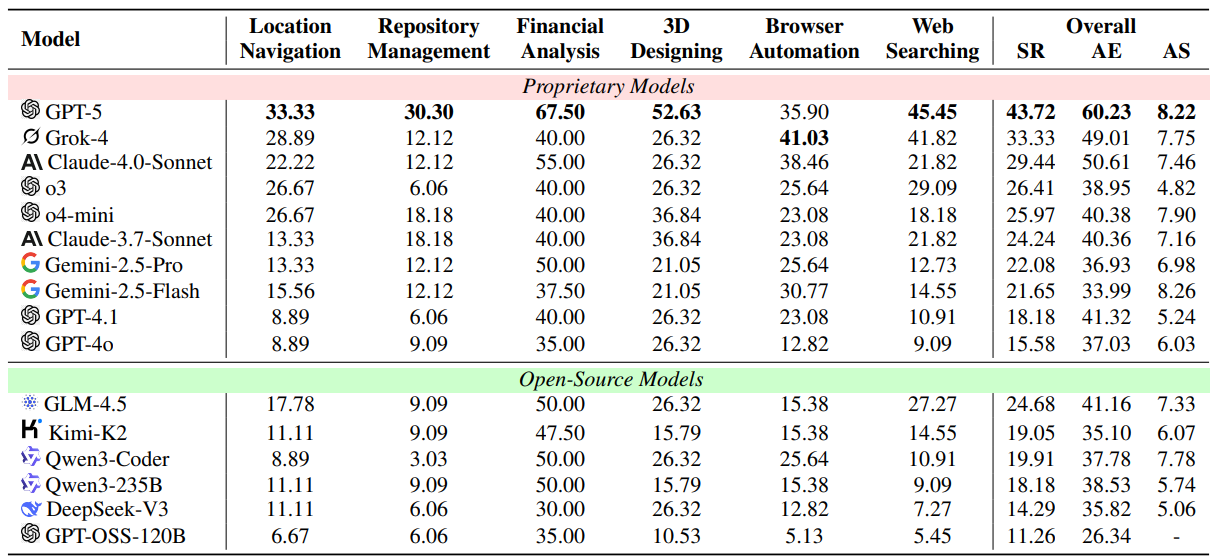
Model performance breakdown. Table 3 reports success rates and average evaluator scores across models when paired with a ReAct-style agent. On the public leaderboard, top models cluster in the 25% to 45% success range, with a best overall around 43.72% (Figure references and exact values are maintained on the website) (MCP-Universe Leaderboard, 2025).
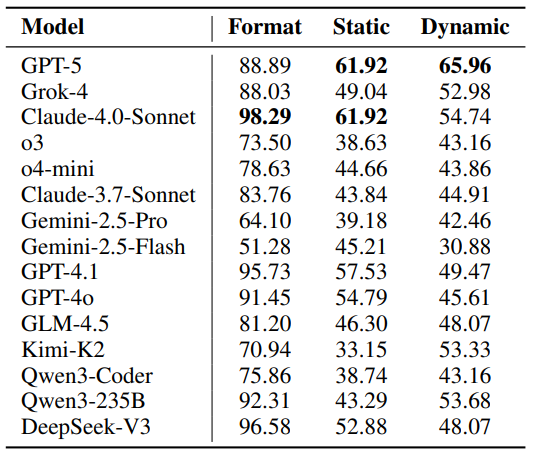
Table 4 breaks down success by evaluator type. Non-reasoning models are most prone to format failures, while reasoning-capable models improve on format but still struggle with dynamic checks that require fetching and reconciling live data. This aligns with field experience: a model that can format JSON may still fail to issue the right sequence of tool calls, handle pagination, or retry degraded endpoints.
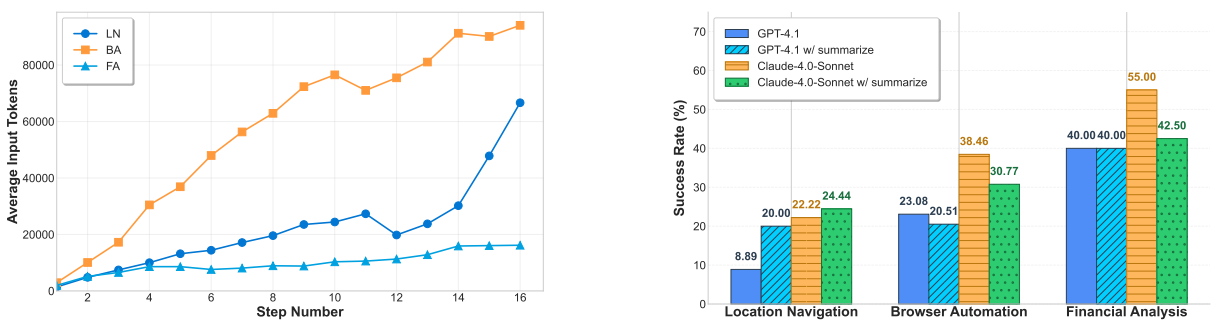
Long-context challenge. Figure 4 shows how token count grows as interactions proceed. Multi-turn sequences often push context windows to their limits, degrading output quality. The authors test a summarization agent that periodically condenses history; this helps for some models but is not a universal fix. It confirms that memory strategy and context management are first-class design choices for MCP agents.
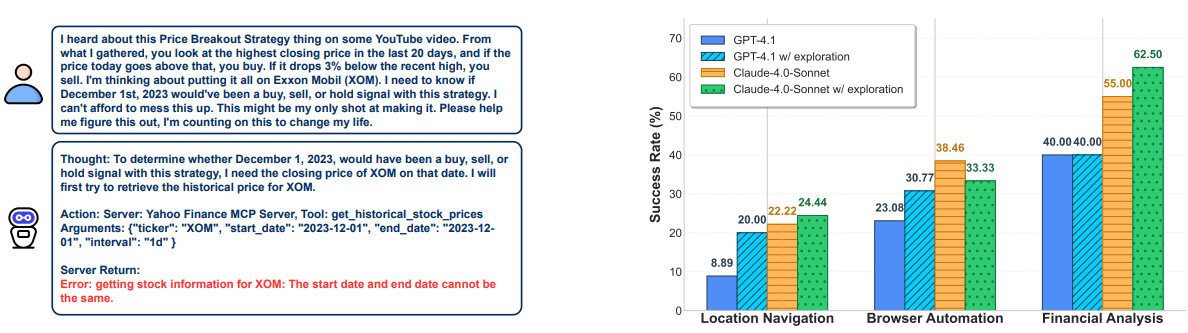
Unknown-tools challenge. Figure 5 (left) captures a common failure: a model calling a finance server misses that an extra flag or parameter is mandatory to retrieve a price series. The exploration-first variant, which adds a tool-discovery phase before solving the task, improves outcomes in some domains (Figure 5 right) but not all. This points to an open research direction: how to encode server capabilities and affordances so agents can learn them quickly during a session, or retain them across sessions.
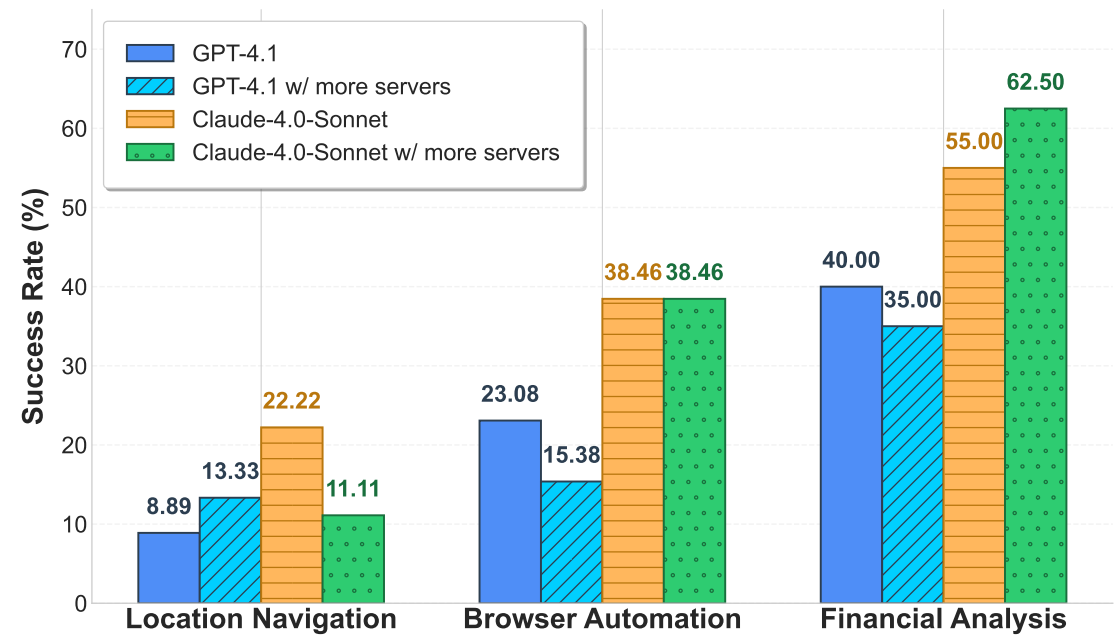
Tool-space size and noise. Figure 6 demonstrates that connecting more servers increases noise and reduces success if the agent is not disciplined about server selection and call sequencing. In practical deployments, this argues for capability routing, server whitelists, or per-domain tool bundles, rather than exposing a maximal tool set to every task.
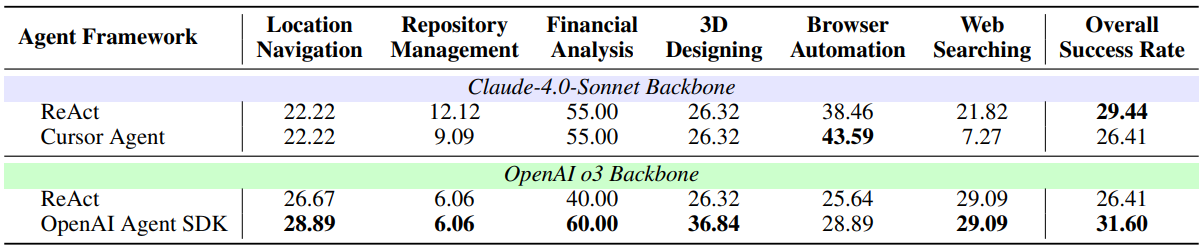
Enterprise agents vs baselines. Table 5 compares enterprise-style frameworks, including Cursor-style agents, against a ReAct baseline with the same model backbone. The takeaway is sobering: a clean ReAct implementation can outperform heavier frameworks on these tasks. Design details such as when to reflect, when to plan, and how to ground tool calls in observations appear to dominate performance in this environment.
Reproducibility and Extensibility
The public repository documents how to define tasks in JSON and compose benchmarks with YAML, including per-domain configs under mcpuniverse/benchmark/configs. It provides a dashboard, log collectors, and report generation utilities. Adding a server involves registering its MCP client configuration and linking evaluators that can verify objective completion (Salesforce AI Research, 2025).
Conclusion
MCP-Universe is a timely benchmark for agentic systems that use the Model Context Protocol. By grounding tasks in authentic servers and enforcing execution-based evaluation, it surfaces real failure modes and makes progress measurable. Today’s frontier models are not yet reliable across domains; the main blockers are context growth, tool unfamiliarity, and the complexity of orchestrating many capabilities.
If you build agents on MCP, this benchmark is a practical way to test improvements in planning, memory, tool literacy, and evaluator-friendly outputs. Start with the paper, review the leaderboard (MCP-Universe Leaderboard, 2025), and explore the repository’s configs and runner scripts (Salesforce AI Research, 2025).
Definitions
MCP (Model Context Protocol): An open protocol that standardizes how applications connect LLMs to tools and data; it uses JSON-RPC 2.0 over transports like stdio and SSE and defines servers, clients, and hosts (Model Context Protocol, 2025).
MCP Server: A capability provider that exposes tools, resources, and prompts via the MCP interface. Examples include Google Maps, GitHub, Yahoo Finance, and Blender integrations as used in the benchmark (Luo et al., 2025).
ReAct: An agent pattern that interleaves reasoning and acting, maintaining a thought-action-observation loop for multi-step problem solving.
Execution-Based Evaluator: An automated checker that verifies task success by parsing agent outputs and/or fetching ground truth, rather than asking another LLM to judge.
Average Evaluator Score (AE): The mean proportion of evaluators passed for a task, reported alongside success rate and average steps on the leaderboard (MCP-Universe Leaderboard, 2025).


MCP-Universe: Real-World Benchmarking For Agents That Use MCP
MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers