Rewriting performance-critical C code in Rust promises stronger memory safety with similar speed, but moving large systems is hard. A new preprint introduces LLMigrate, a toolchain that combines large language models with static analysis and compiler feedback to translate C modules into Rust while minimizing human edits (Liu et al., 2025).
The authors benchmark LLMigrate on three Linux kernel modules (math, sort, ramfs) and report less than 15% of the final Rust lines required manual modification to compile and run correctly, despite heavy use of safe Rust.
The core insight is that state-of-the-art LLMs can produce idiomatic, safe Rust, but they get “lazy” on long, complex inputs, skipping code by replacing it with comments or stubs.
LLMigrate breaks the job into function-sized units, preserves just enough context to translate accurately, and uses a repair loop driven by the Rust compiler to fix what the model gets wrong. Where necessary, it falls back on rule-based tools like C2Rust for completeness, and uses Bindgen for consistent type and macro definitions.
Key Takeaways
- Function-level translation largely eliminates LLM “laziness,” the tendency to omit code when context is long (Figure 4); shorter functions translate more completely and accurately.
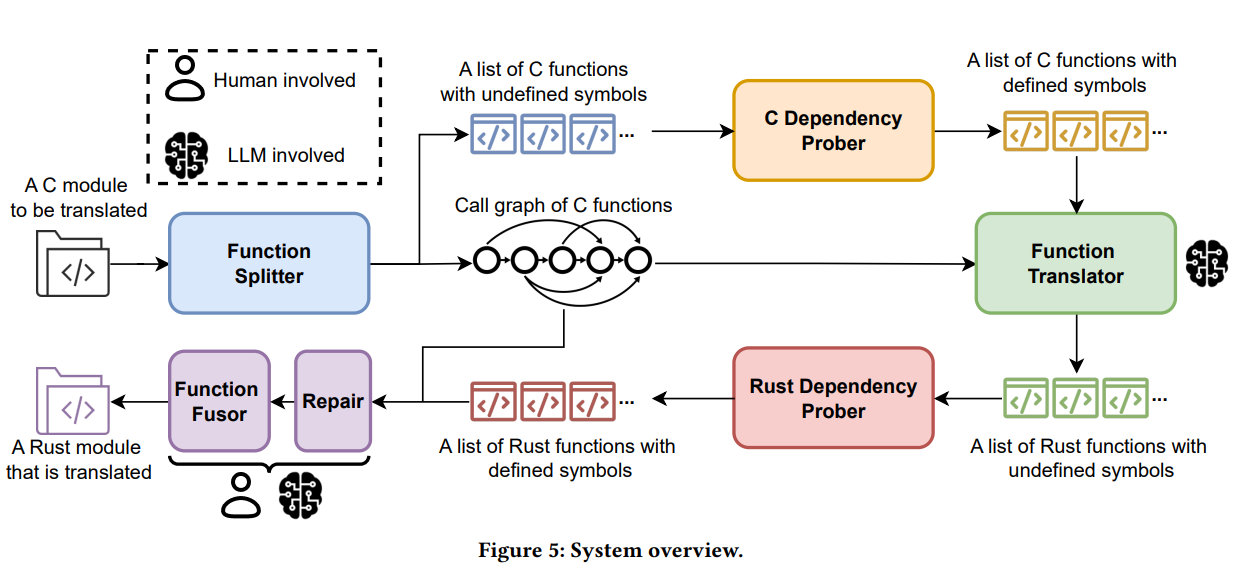
- A call-graph-guided workflow preserves essential context while keeping prompts small, reducing omissions and improving correctness (Figure 5, Figure 6).
- An iterative program repair loop uses compiler errors to guide targeted fixes; within three rounds, most functions compile (Table 5).
- On Linux kernel math, sort, and ramfs modules, human edits drop below 15 percent of final lines while safe Rust dominates, reaching up to 98.9 percent safe code in one module (Table 2).
- Compared to one-shot, whole-module translation with GPT-4o, function-level LLMigrate yields higher CodeBLEU, far fewer edits, and near-zero laziness (Table 4).
- The pipeline integrates rule-based tools for stability and coverage: C2Rust for hard cases and Bindgen for external types and macros; Tree-sitter powers function splitting and syntactic checks (Tree-sitter, n.d.).
Overview
LLMigrate targets a practical gap between two families of translators. Rule-based systems like C2Rust are precise but produce mostly unsafe Rust, leaving maintainers to hand-lift to safe idioms. While LLMs such as GPT-4o generate more idiomatic, safe Rust but struggle with long inputs, often omitting large chunks of code.
The paper calls this the “laziness” problem and quantifies it: omission probability rises sharply with input length, from about 1.67 percent below 200 lines to 47.4 percent around 700 lines (Figure 4).
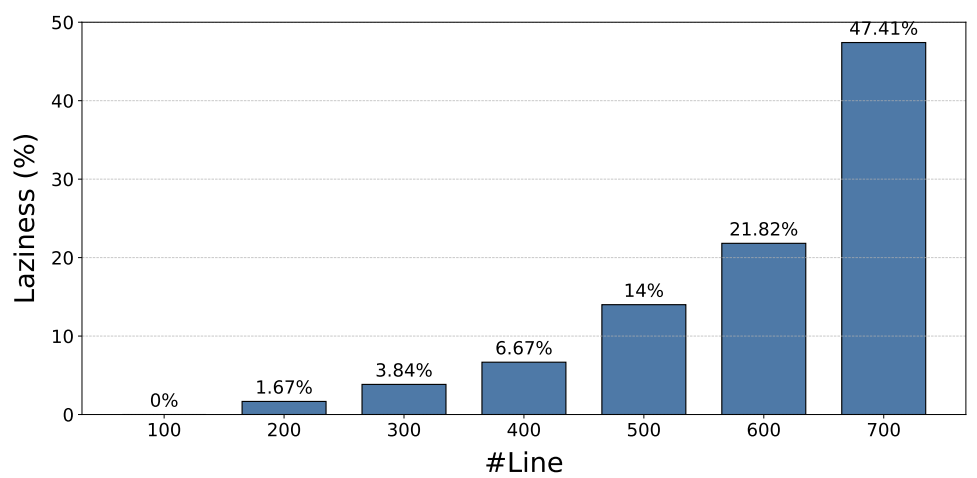
Figure 4: The Probability of Laziness Across Different # Line. As the number of code lines (# Line) increases, the probability of laziness exhibits a rising trend. Credit: Liu et al
The design responds with a function-centric pipeline. First, a Function Splitter uses Tree-sitter to extract functions and build a call graph, then a C Dependency Prober resolves undefined symbols by appending declarations for externally referenced variables and functions to each function’s context.

Figure 6: One splitted C function from the ramfs module, along with its contextual dependencies including external variables and functions it invokes. Credit: Liu et al
Crucially, it does not inline full implementations, keeping prompts compact and focused (Figure 6). The Function Translator calls an LLM to translate each function to Rust, following call-graph order.

Figure 8: The translation process of one C function from the ramfs module. BindGen translates the definitions of its external variables, while LLM translates the C function and its invoked external functions into Rust. The Rust Dependency Prober iteratively integrates these translations, resolving any undefined symbols and ensuring correctness through a compiler-driven process. Credit: Liu et al
Rather than accept model-generated headers and types, LLMigrate standardizes those with Bindgen. A Rust Dependency Prober compiles each translated function, iteratively adding missing external definitions and imported functions until unresolved symbols disappear (Figure 8). Finally, a Function Fusor assembles functions into a cohesive module in topological order, compiling at each merge step to catch regressions.
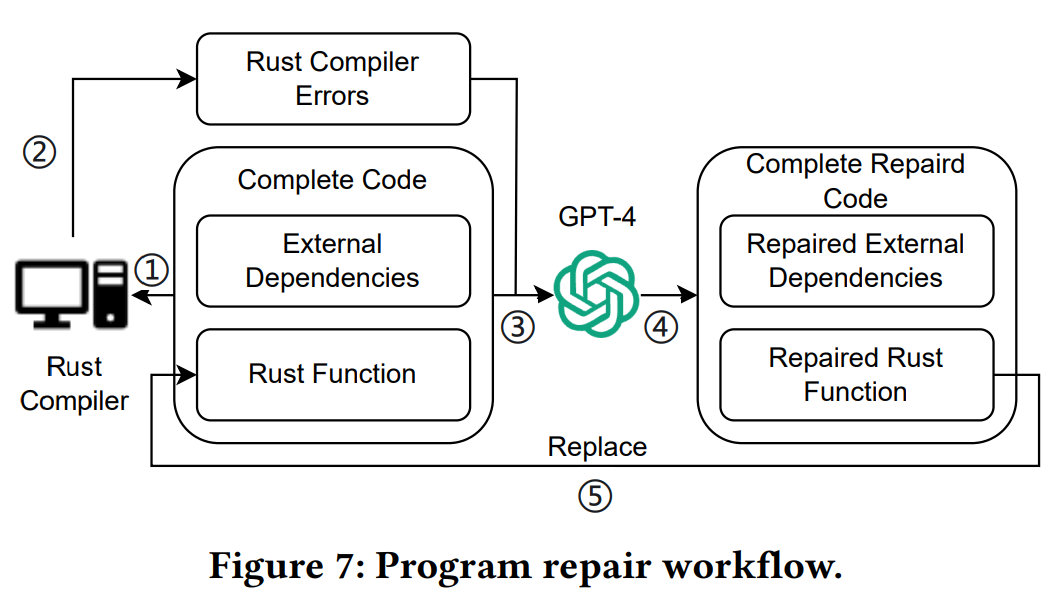
Two backup mechanisms guard against failure. A program Repair component feeds compiler error messages back to the LLM to request minimal fixes (Figure 7). If a function still fails after three repair iterations, LLMigrate swaps in an unsafe Rust version generated by C2Rust so overall translation can proceed. This hybrid approach uses LLMs for idiomatic, safe code where possible, and rule-based tools where necessary.
Why It Matters
Rust is gaining traction in the Linux kernel and other systems code because it removes whole classes of memory bugs ((Li et al., 2024); (Panter and Eisty, 2024)). Migration, however, is bottlenecked by scale: millions of lines, dense dependencies, and domain-specific constraints.
LLMigrate shows that careful orchestration of LLMs with static analysis and compilers can unlock practical workflows at module scale, with most output already in safe Rust.
Several trade-offs do exist and are targets for future development. Function-wise translation and iterative repair add control logic and compilation cycles. That costs time, and the authors note that human effort is uneven: a handful of hard errors can dominate engineering hours. The fallback to unsafe code in rare cases acknowledges reality while preserving progress. Still, the net result is compelling in practice: small, localized edits and a high ratio of safe code.
Discussion Of Results
The paper evaluates three kernel modules with diverse shapes and dependencies: math (18 functions, 809 lines), sort (12 functions, 291 lines), and ramfs (21 functions, 637 lines) (Table 1). The authors report per-function distributions and contextual characteristics (Figure 3) and focus on three questions: manual effort, error profiles, and function vs. module granularity.
Manual Effort and Safe Code.

Table 2: End-to-end results of translating three datasets using LLMigrate. For each dataset, we report the number of final code lines (# Line) after translation and the number of LLM-generated code lines (# Line-LLM). The final code consists of LLM-generated code augmented with Bindgen-generated code, external functions, and human modifications and we report the number and proportion (%) of Manually Modified Lines (MML) during this augmentation process. We also report the number and proportion of Safe Code (SC) in the final code, and in the LLM-generated code. Credit: Liu et al
Table 2 summarizes end-to-end outcomes. Despite hundreds to thousands of lines per module after translation and augmentation, manual modifications remain below 15 percent of final lines. Safe Rust dominates: up to 98.9 percent safe code in one module, and 41.7 percent in the lowest case, where a few unsafe functions weigh heavily because the module has very few functions.
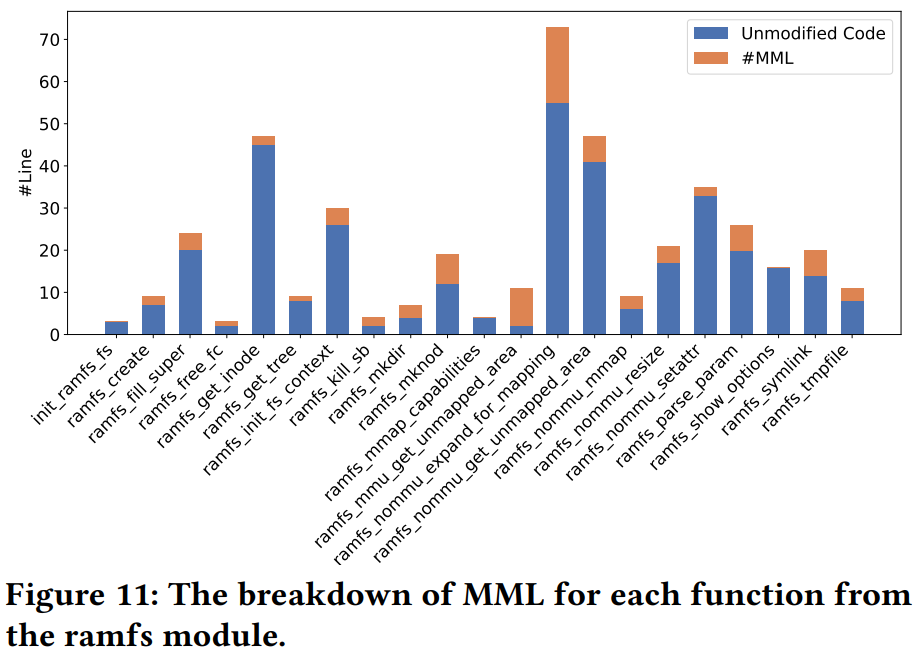
For ramfs, the percentage of manual edits appears small partly because Bindgen inflates context with complex headers and macros; a function-level breakdown (Figure 11) shows manual edits scale with function length, which aligns with translation difficulty.
Analysis of Error Types
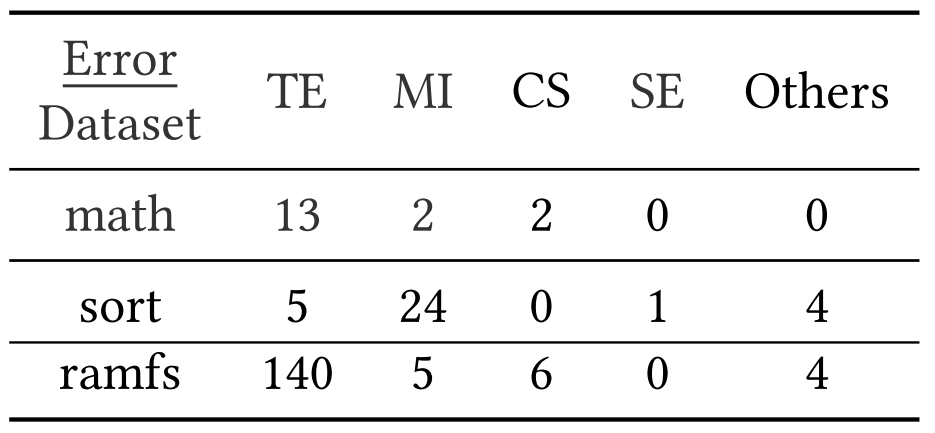
Table 3: The types and frequency of errors that require manual resolution when using LLMigrateto translate three datasets Credit: Liu et al
Table 3 categorizes issues that require human fixes into Type Errors (type mismatches and trait requirements), Missing Imports, Changed Symbols (naming mismatches or hallucinations), Semantic Errors, and Others. Type Errors dominate in math and ramfs.

The paper highlights a semantic pitfall from translating size & -size in C to Rust, where wrapping behavior differs; the correct Rust is size & !size.wrapping_add(1) (Figure 14). Examples also show hallucinated type names such as Inode instead of inode (Figure 13) and trait import gaps that block method calls.

Table 4: Performance comparison between GPT-4o and LLMigrate on translating three Linux kernel modules: math, sort, and ramfs. The evaluation includes three metrics: Manually Modified Lines (#MML), CodeBLEU, and Laziness. MMLs for GPT-4o are estimated based on the difference between the ground truth Rust code lines and the lines generated by GPT-4o. Credit: Liu et al
Function-level vs. Whole-Module Translation
Table 4 contrasts LLMigrate with a one-pass GPT-4o baseline. The function-wise method all but eliminates laziness on sort and ramfs and slashes manual edits across the board. CodeBLEU scores rise substantially, reflecting closer alignment with reference code ((Ren et al., 2020)). The authors argue that per-function translation enables fast human verification and targeted repair, raising the probability that all tokens are correct when reassembled.
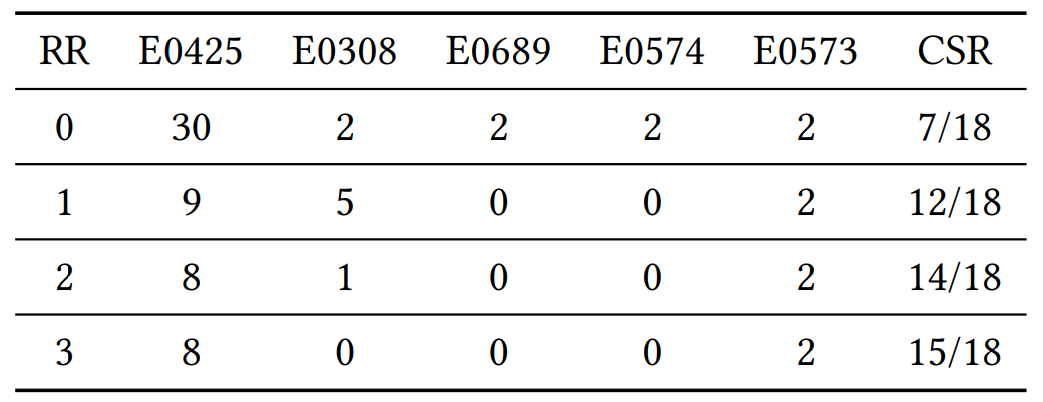
Table 5: The impact of program repair following the Rust Dependency Prober in addressing LLMs’ inability to translate complex functions. It presents the distribution of error types, categorized by error codes, encountered during the translation of 18 functions in the math module. Additionally, it shows the progression in the Compilation Success Rate (CSR) functions after zero, one, two, and three rounds of repair (RR). Credit: Liu et al
Repair Effectiveness
Table 5 tracks compiler error codes and compilation success rate across up to three repair rounds for the math module. Success rises from 7/18 functions compiling with zero repair to 15/18 after three rounds, then plateaus. The repair loop consistently clears symbol and type errors that models struggle to resolve in the first pass.
The Broader Context
The results echo a broader trend in code translation: hybrid pipelines outperform monolithic strategies. LLMigrate leans on foundational tools like Tree-sitter for structured splitting and syntax checks ((Tree-sitter, n.d.)), Bindgen for consistent FFI definitions ((Bindgen, n.d.)), and C2Rust for worst-case fallbacks ((C2Rust, n.d.)). Meanwhile, general-purpose LLMs such as GPT-4o and open models like Llama 3 continue to improve ((OpenAI, 2023); (Dubey et al., 2024)), and specialized code LLMs push translation quality and reliability further ((Zheng et al., 2023)).
Conclusion
LLMigrate offers a credible path to migrate complex C modules into mostly safe Rust with modest human effort. The key is discipline: split by function, preserve the right context, iterate with the compiler, and accept rule-based fallbacks when needed. For organizations planning Rust adoption in systems code, the paper is a practical blueprint. It also maps clear next steps: better model priors for low-level systems code, deeper static analysis to automate repairs, and broader evaluations across subsystems.
For details, figures, and prompts, read the preprint ((Liu et al., 2025)). Tooling referenced in the paper includes C2Rust ((C2Rust, n.d.)), Bindgen ((Bindgen, n.d.)), and Tree-sitter ((Tree-sitter, n.d.)).


LLMigrate Turns Lazy LLMs Into Reliable C-to-Rust Translators
LLMigrate: Transforming "Lazy" Large Language Models into Efficient Source Code Migrators