Today we are taking a look at LabOS: The AI-XR Co-Scientist That Sees and Works With Humans, a research preprint led by Le Cong (Stanford) and collaborators from Princeton and other institutions.
The paper proposes a unified system that pairs a self-evolving, multi-agent AI for computational (dry-lab) work with an extended-reality (XR) interface and a lab-specialized vision-language model (VLM) for real-time, physical (wet-lab) experimentation.
The researchers primary claim is that the same AI system can plan experiments, create analytical tools, interpret egocentric video from smart glasses, guide researchers at the bench, detect procedural errors, and automatically document experiments. The authors position LabOS as a step toward an "AI co-scientist" that actively participates in laboratory discovery rather than remaining purely digital.
The work is motivated by two trends: (1) rapid AI progress that has already reshaped dry-lab domains such as protein structure prediction and scientific analysis ((Jumper et al., 2021)) and (2) persistent bottlenecks in wet-lab practice, where perception, coordination, tacit skill, and reproducibility still limit throughput.
The paper also evaluates LabOS on biomedical reasoning benchmarks (for example, HLE: Biomedicine and LAB-Bench), and introduces a new egocentric laboratory video benchmark, LabSuperVision (LSV), used to post-train a tailored VLM. The work extends advancements made with the STELLA framework from both research principles. (Cong, Wang 2025) References to the HLE benchmark and LAB-Bench can be found at (Phan et al., 2025) and (Laurent et al., 2024).
Key Takeaways
- LabOS integrates a multi-agent "self-evolving" AI with XR glasses, enabling continuous loops from hypothesis generation to physical validation and documentation.
- A lab-specialized VLM trained on LabSuperVision (egocentric lab videos), JoVE, and FineBio is used to interpret first-person lab footage, align steps with protocols, and flag deviations in real time.
- On biomedical reasoning tasks, the authors report top scores on HLE: Biomedicine, LAB-Bench DBQA, and LAB-Bench LitQA, with performance scaling when given more inference-time compute; these are claims by the paper and should be assessed by future replication.
- For XR deployment, LabOS streams short video segments (for example, 5-10 seconds at ~4 fps) from glasses to a local or cloud server for VLM inference, returning JSON-structured guidance to the wearer.
- The system demonstrates three case studies: target discovery for NK cell immunotherapy, mechanistic identification of a cell-fusion regulator (ITSN1), and copiloting complex stem-cell workflows.
Overview
The LabOS architecture has two tightly coupled modules. First, a dry-lab "self-evolving" multi-agent system handles planning, analysis, and tool creation. The Manager/Planner decomposes a scientific objective into modules (molecules, reagents, steps, controls) then the Developer writes and runs code for bioinformatics analyses passing the result to the Critic who audits results and suggests refinements.
Crucially, a Tool-Creation agent expands a shared "Tool Ocean," auto-generating or integrating new utilities from literature and databases. By caching templates of successful reasoning and continuously adding tools, the system is designed to improve over time through use.
Second, a wet-lab module links the agent to physical execution via XR glasses and a lab-specialized VLM. Protocols are rendered step-by-step in a Unity/Android app on the glasses. The VLM consumes the wearer's video stream to detect objects and actions, align ongoing work to the protocol, and raise context-aware prompts.
Outputs are time-stamped and logged, enabling automatic documentation and later review. The authors also explore spatial grounding using 3D/4D scene reconstruction to support localization and spatio-temporal reasoning. For background on metric 3D reconstruction and modern Gaussian splatting pipelines that inform such digital twins, see (Keetha et al., 2025) and (Li et al., 2025).
To train the VLM for lab scenes, the authors assembled LabSuperVision (LSV), a dataset of more than 200 egocentric lab sessions recorded by seven researchers across benches, tissue culture rooms, and instrument bays.
Each session is aligned to a gold-standard protocol and annotated with step boundaries, deviations (for example, sterile breaches, timing errors), and critical materials or parameters. Off-the-shelf general VLMs reportedly struggled on LSV, so the team post-trained a Qwen-VL-based model via supervised fine-tuning with LoRA, followed by reinforcement learning using Group Relative Policy Optimization, a recent algorithm that replaces a value function with group-normalized rewards.
Why It's Important
For more than a decade, AI has accelerated computation-first science including protein folding, materials discovery, and modeling in physics and chemistry. Yet experiments remain a rate-limiter when expertise is tacit, protocols are fragile, and environments vary. LabOS is interesting because it fuses dry-lab reasoning with wet-lab perception and action.
If reliable, this fusion could reduce common failure modes such as step omissions, timing deviations, contamination, or mislabeling, it could make advanced protocols more transferable across labs and lower the learning curve for new researchers.
The authors emphasize reproducibility and skill transfer. By streaming egocentric video, aligning it to structured steps, and logging both intended and observed actions, LabOS creates a rich trace of what actually happened.
Expert-run recordings become training assets for junior scientists, while VLM prompts during "live" runs enforce sterile technique or correct timing. The integration with public resources such as The Cancer Genome Atlas (TCGA) is also notable for analysis workflows ((TCGA Research Network)), enabling the agent to connect screening hits to patient data and survival trends.
Discussion
The results are organized around four main components: an overview of the agentic system; the self-evolving agent's benchmark performance; training a lab VLM with LSV; and XR glasses for real-time guidance.
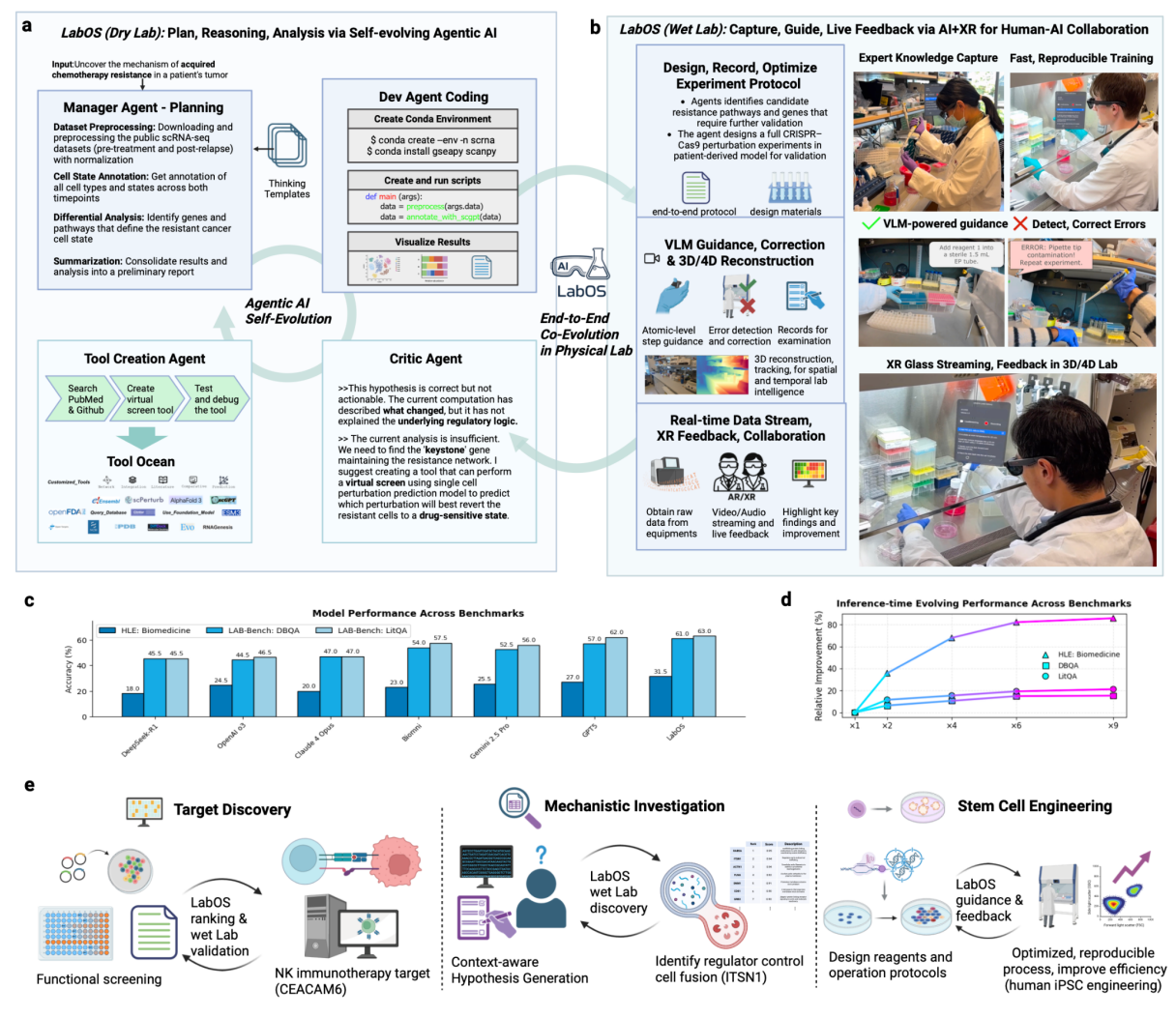
Figure 1. LabOS: Multi-Modal Human-AI Collaboration in Science Laboratory. LabOS comprises a self-evolving agentic AI for dry lab tasks and an XR interface for human-in-the-loop wet lab execution, creating an end-to-end system for lab research. a, Dry Lab: Agentic AI as computational core of LabOS. The system employs a multi-agent framework, including a Manager Agent for planning, a Dev Agent for coding and execution, and a Critic Agent for evaluation and refinement. The agents continuously improve analytical capabilities. A Tool Creation Agent expands the system's functions by generating new tools from sources like PubMed, which are then stored in a shared Tool Ocean. This component automates complex data analysis. b, Wet Lab: Capture, guide, live feedback via AR/XR for human-AI collaboration in the physical laboratory. A scientist wearing AR/XR glasses receives real-time guidance from the AI. A specially trained Vision-Language Model (VLM) monitors the procedure, providing on-the-fly error detection and correction to ensure correctness and reproducibility. c, Results on leading benchmarks— HLE: Biomedicine, LAB-Bench: DBQA, and LAB-Bench: LitQA—show LabOS outperforming frontier LLMs/agents in biomedical reasoning tasks. d, Self-evolving agent’s performance scales with inferencetime compute. e, Use Cases. The first case is drug target discovery: the agentic AI analyzes functional screening data to identify and rank NK cancer immunotherapy targets. Secondly, for mechanistic investigation, LabOS generates testable hypotheses that are then validated by a human scientist to identify a cell fusion regulator. Thirdly, LabOS enabled copiloted, reproducible processes for complex experiments like stem cell engineering. All photographs shown are of the authors. Credit Cong et al
The paper's Figure 1 depicts the full stack: (a) a multi-agent dry-lab core with Manager, Developer, Critic, and Tool-Creation roles; (b) the wet-lab interface with XR glasses and the lab VLM providing on-the-fly error detection and correction; (c) benchmark summaries (HLE: Biomedicine, LAB-Bench DBQA and LitQA); (d) scaling behavior with more inference-time compute; and (e) use cases including NK immunotherapy, mechanistic hypothesis testing, and stem-cell engineering.
Benchmarking claims include new highs on the selected biomedical benchmarks and state that performance scales with the amount of computer resources available at inference. Because both HLE and LAB-Bench are evolving community assets, future third-party replications will be crucial to validate relative gains and tease apart contributions from tool use, retrieval, and inference-time scaling. For the benchmarks themselves, see (Phan et al., 2025) and (Laurent et al., 2024).

Figure 2. LabOS-VLM for visual reasoning in laboratories. a, LabSuperVision (LSV) benchmark dashboard with egocentric and fixed-view lab videos paired to gold-standard protocols, including notes, issues or errors labeled by human experts. b, LSV benchmarking pipeline in four stages: (1) Data collection—multi-modal recordings from diverse facilities via fixed cameras and XR smart glasses; (2) Data processing—expert curation with light automation, aligned to reference protocols and parameters; (3) Dataset assembly—compressed corpus of 200+ experiment-session videos; (4) Evaluation—human and GPT-5 assessments of model performance on LSV. c, Benchmarking AI models on LSV via human experts (n=5) and GPT-5. Scores range 0–5 (5 = perfect). d, LabOS-VLM post-training using FineBio, JoVE, and LSV datasets via supervised fine-tuning (SFT) and reinforcement learning (GRPO). e, LabOSVLM family outperform baselines on protocol generation quality (left) and error-detection rate (right) on LSV. f–g, Real-world testing of LabOS-VLM: (f) error detection/correction in a tissue culture experiment; (g) context-aware AI generated step-by-step instructions grounded in visual understanding. Credit Cong et al
Figure 2 focuses on the VLM pipeline and LSV benchmarking. It shows the four-stage data flow (collection, processing, assembly, evaluation) and compares baseline general models against LabOS-VLM on two tasks: (1) protocol alignment, i.e., can the model reconstruct a stepwise procedure from video; and (2) issue identification, i.e., can it highlight deviations versus a gold standard.
The authors report that general-purpose VLMs underperform on fine-grained lab tasks, while the LabOS-VLM family substantially improves both protocol reconstruction and error detection after SFT and GRPO-based post-training. They further present qualitative tests on CRISPR delivery and Cas9-RNA complex preparation, where the VLM flags missteps and proposes the next action based on visual context.

Figure 3. LabOS on XR glasses enables spatially-grounded human–AI collaboration in physical laboratories. a, Live streaming from XR glasses to the LabOS VLM server enables real-time scene understanding, feedback, and interactions between human and AI agents. b, Deployment of LabOS AI+XR system across lab settings. c, Live action feed from the wearer’s perspective. d, LabOS AI+XR provides guidance and summary on the lab operation. e, Detected deviations trigger inline error prompts and suggested corrections, to mitigate human researcher’s oversight. f, Feed-forward Gaussian splatting supports camera tracking and multi-view, metric-depth 3D reconstruction, enabling object localization and spatio-temporal reasoning for scientific workflows. All photographs shown are of the authors. Credit Cong et al
Figure 3 shows XR deployment in the lab. Live video from the glasses is chunked and sent to the server for analysis; the server returns JSON with step alignment and suggestions. The UI displays guidance, warnings, and summaries to the wearer.
The paper also highlights spatial grounding via feed-forward 3D reconstruction and Gaussian splatting, which can support object localization and trajectory-aware reasoning in constrained lab environments. Readers interested in the underlying 3D technology trends can compare the goals with recent work on universal metric reconstruction (Keetha et al., 2025) and language-guided 4D splatting (Li et al., 2025).
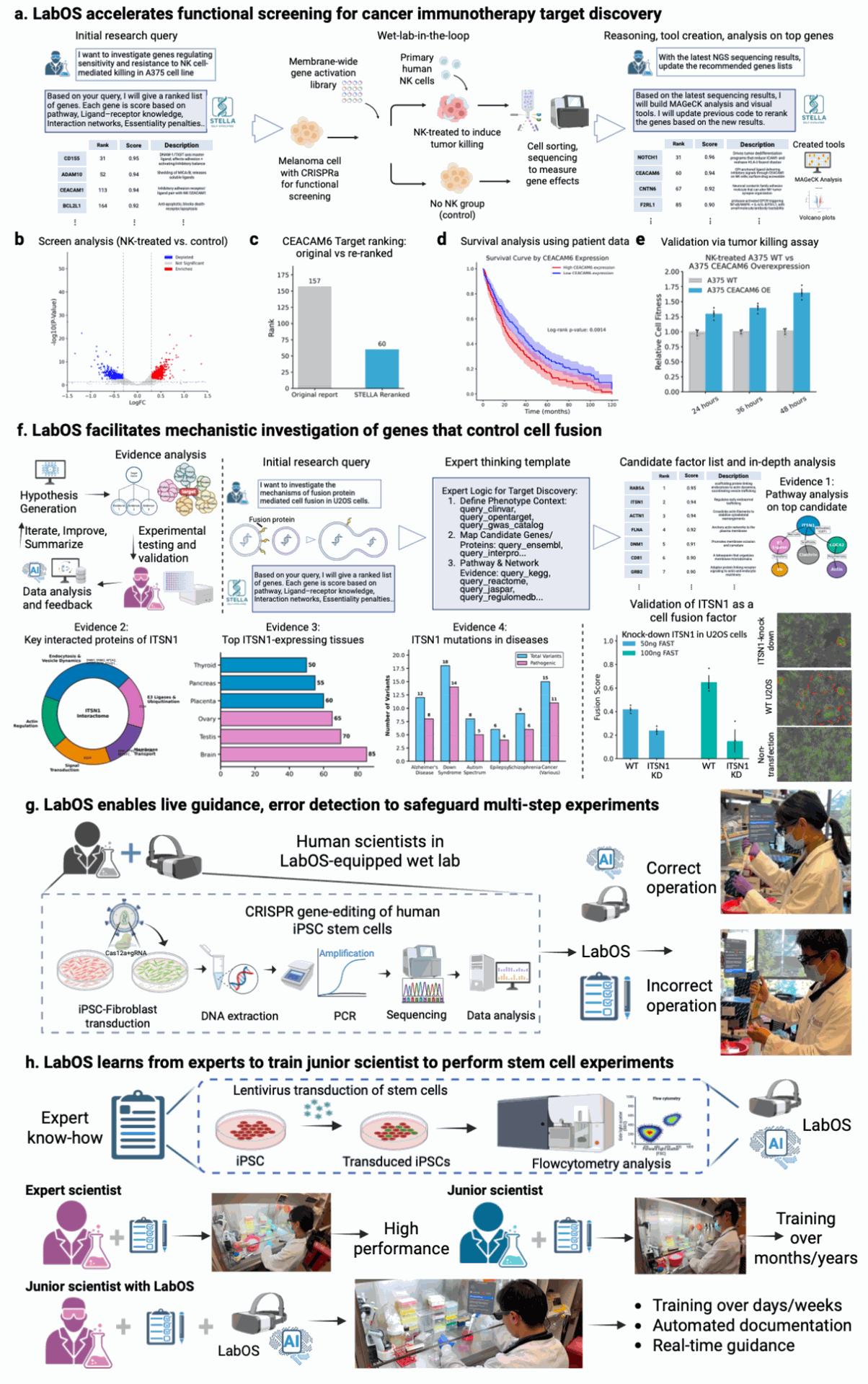
Figure 4. LabOS applications in target discovery, mechanistic investigation, and stem cell research. a-e, Functional screening study for Natural Killer (NK) immunotherapy target identification. LabOS was prompted with the research task to identify regulators of tumor resistance to NK killing, based on results from a CRISPR activation screen in A375 melanoma cells co-cultured with primary human NK cells. b-e, AI-generated screen analysis reveals differential gene enrichment upon NK treatment (b), and the AI agent re-ranked key target—CEACAM6—moving it from low to top-ranked position (c) and automated survival analysis using cancer patient data, stratified by CEACAM6 expression (d). Wet-lab functional validation confirms enhanced NK resistance upon CRISPRa activation of CEACAM6 (e). f, LabOS applies to mechanistic investigation of cell fusion factors. LabOS proposes ITSN1 as a regulator of cell-cell fusion, providing its found evidence and reasoning trajectories. Experimental knock-out of top candidate gene ITSN1 confirmed this gene’s impact on cell fusion in the wet lab, validating the AI co-scientist’s hypothesis. g, LabOS provides live copiloting to researchers in stem cell gene-editing experiments. The AI-XR agent enables live guidance, error detection to safeguard multi-step experiments, where scientists can use LabOS to monitor and track issues automatically. h, The AI-XR agent can learn advanced skills in experiments and document them such as the lentiviral transduction of human iPSC stem cells. All photographs shown are of the authors. Credit Cong et al.
Figure 4 presents end-to-end case studies. In an NK cell immunotherapy screen, the agent analyzes CRISPRa results from melanoma cells co-cultured with primary human NK cells, re-ranking candidate regulators and nominating CEACAM6 as a target for increased tumor resistance to NK killing.
The team links the nomination to patient outcomes by automatically stratifying TCGA survival curves by CEACAM6 expression, then validates in wet-lab assays. In a second study, the system focuses on cell-cell fusion and prioritizes ITSN1 as a regulator; CRISPRi knockdown decreases fusion in U2OS cells. Finally, two stem-cell experiments show the XR copilot in action: real-time error detection in gene knockout and automatic documentation of lentiviral transduction in iPSCs for later training of juniors.
Limitations and Open Questions
First, LSV is introduced and used in-house. Community access, licensing, and a clear evaluation protocol will determine whether others can reproduce the VLM results.
Second, the reported >90% error-detection accuracy for the largest LabOS-VLM should be stress-tested across new labs, lighting, PPE, and instrument variation to check robustness.
Third, safety and ergonomics matter: XR comfort for long sessions, data privacy, and the latency budget between capture, VLM inference, and guidance.
Fourth, agentic self-improvement introduces provenance questions: how are new tools vetted before use in critical analyses; how does the system guard against tool drift or reward hacking during reinforcement learning?
Finally, the benchmarking story would benefit from side-by-side ablations: with and without XR/VLM; with and without Tool-Creation; and varying inference-time scaling.
Conclusion
LabOS proposes an ambitious pattern for scientific AI: multi-agent reasoning that not only plans and analyzes, but also perceives and helps execute experiments in real time. The system's dry-lab agent, lab-specialized VLM, and XR interface are designed to close the loop between hypothesis and validation, while accumulating reusable tools and step traces for skill transfer.
The early demonstrations in immuno-oncology, mechanistic biology, and stem cells are promising, but external access to LSV, careful replication on public benchmarks, and broader testing in heterogeneous lab conditions are essential next steps. Readers can consult HLE (Phan et al., 2025), LAB-Bench (Laurent et al., 2024), and TCGA (TCGA Research Network) for related context and baselines.
Definitions
Agentic AI: An AI system that plans, decomposes tasks, calls tools, and critiques its own outputs while iterating toward a goal.
Vision-Language Model (VLM): A model that aligns visual and textual representations to interpret scenes and generate grounded language about them.
Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that replaces a learned critic with group-normalized rewards to improve learning stability in language-model post-training ((DeepSeek Team, 2025)).
Gaussian Splatting: A family of real-time 3D scene representations that render millions of ellipsoidal Gaussian primitives and can be extended to encode semantics or language features ((Li et al., 2025)).
TCGA: The Cancer Genome Atlas, a large, publicly accessible multi-omics program from the U.S. National Cancer Institute; data are accessible via the Genomic Data Commons ((TCGA Research Network)).


LabOS: An AI-XR Co-Scientist That Sees And Works With Humans
LabOS: The AI-XR Co-Scientist That Sees and Works With Humans