In-context learning (ICL) is the claim that an autoregressive large language model can learn a task from a handful of examples in its prompt, then generalize without updating weights. The paper Is In-Context Learning Learning? by Adrian de Wynter (Microsoft and University of York) pairs a clear theoretical framing with one of the largest empirical ICL studies to date. The study looked at four LLMs, nine formal and programmatic tasks, multiple prompting strategies, and 1.89 million predictions per model.
The headline is nuanced. Mathematically, ICL fits the definition of learning in the PAC framework, but its practical behavior is constrained. With more exemplars, models become less sensitive to the particular prompt and even to natural-language phrasing. Yet the same setup is brittle under out-of-distribution (OOD) shifts and shows large performance gaps across tasks that look similar on paper.
The work builds on the few-shot learning narrative popularized by GPT-3 ((Brown et al., 2020)), evaluates reasoning-style prompting like chain-of-thought ((Wei et al., 2022)), and compares against a compositional strategy known to aid robust generalization in formal languages ((Dan et al., 2022)).
Key Takeaways
- ICL qualifies as learning in the PAC sense, but the mechanism is ad hoc and tied to autoregression rather than stable task representations.
- Performance improves steadily with more shots. In the limit, accuracy becomes insensitive to prompt style, exemplar order, and even natural-language wording.
- OOD (out-of-distribution) brittleness is persistent. Chain-of-thought and automated prompt optimization are the most sensitive when train and test distributions diverge.
- Formally similar tasks show surprisingly different peak accuracies. Pattern Matching is essentially solved, while Reversal, Maze (Solve), and Vending Machine (Sum) lag significantly.
- Traditional baselines like decision trees or k-NN sometimes beat ICL on average, despite LLMs winning best-of configurations.
- Word-salad prompts approach baseline performance as shots grow, suggesting lexical cues matter less than exemplar-induced regularities.
Overview
The study asks a crisp question: does ICL learn, and how robust is that learning? The authors ground ICL in a PAC-style (
probably approximately correct ) formulation. A learner observes a set of labeled exemplars drawn from distribution
In ICL, the learner is an LLM conditioning on a system prompt plus exemplars, then performing next-token prediction to output labels. This makes the representation highly dependent on the prompt and exemplar formatting, but still admits the formal notion of learning if error bounds hold across shifts
Tasks are framed using formal language theory (CalTech)(Merill et al, 2021). Several problems fall under finite state automata (FSA), like PARITY and Pattern Matching. Others require pushdown automata (PDA)-like behavior, like Reversal and Stack, which need a form of external memory. The authors treat LLMs as recognizers of unknown expressive power and explicitly test both FSA-like and PDA-like regimes.
Prompting strategies span:
- n-shot (Modus Ponens): exemplars without a description.
- Description: a system prompt describing the task.
- Automated Prompt Optimization (APO): a meta-prompt tuned on a dev set ((Xu et al., 2023/2025) is related background).
- Direct Encoding (DE): pass an explicit encoding of the automaton.
- Chain-of-Thought (CoT): require intermediate steps ((Wei et al., 2022)).
- Word Salad / Salad-of-Thought (SoT): randomize the natural-language strings.
The dataset generator builds synthetic corpora per task by sampling from automata with controlled state transitions and emissions. The train set has 2,000 examples from
Why It Matters
ICL underpins a wide range of practical workflows. From operations teams that rely on prompt templates to product engineers who use examples to steer behavior, ICL is often treated as a drop-in replacement for training.
This work shows where that mental model holds and where it cracks. In short: more shots generally help and lexical phrasing matters less in the limit, but distribution shift remains a real risk. Users who expect robustness when input lengths grow, alphabet changes, or structures differ should test for those shifts explicitly.
The analysis connects to two important threads. First, earlier demonstrations of few-shot behavior in GPT-3 gave the field a powerful narrative ((Brown et al., 2020)). Second, compositional strategies that expose internal automaton states can improve robustness in formal languages ((Dan et al., 2022)). The present paper’s negative results for OOD shifts under CoT and APO suggest that prompt-only strategies may bias models toward surface regularities in the observed exemplars.
Discussion
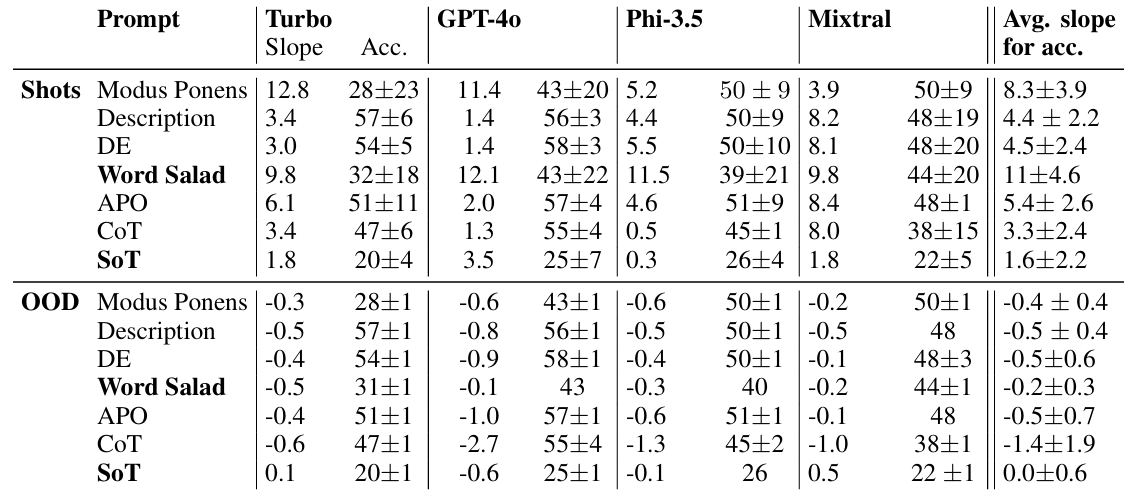
Table 2: Slopes and accuracies for every LLM, averaged over prompts and tasks. On the rightmost column is the average slope for all LLMs. Rows in bold (word salad and SoT) are not factored in our main results, but discussed in Section 6.1. The effectiveness of the prompts depended on the slope and the accuracy and σ: large σ and a positive slope means an increasing trend in accuracy, with larger slopes implying a larger change. Shot slopes are positive, while the δ slopes are near zero, and slightly negative. This suggests that more shots continuously improve accuracy; but in OOD this improvement is ineffective under any prompt, defaulting to the average and decreasing overall. Credit: Wynter
The results break down into three buckets: aggregate performance, OOD sensitivity, and fine-grained effects of prompts and exemplars. At a high level, more shots consistently improve accuracy. Ordinary least squares fits over shots show positive slopes across prompts, with the steepest average improvements for Modus Ponens and the lowest for CoT. Mixtral shows the largest gains from adding shots among the tested models.
By task, Pattern Matching reaches 94 ± 1 percent average accuracy, effectively solving the problem. Hamiltonian verification and Vending Machine (Verification) cluster in the 80s on average. On the other end, Vending Machine (Sum) is very low (peak around 16 ± 1 percent), Reversal is 61 ± 11 percent, and Maze (Solve) sits near the low 60s. The authors highlight a striking observation that closely related tasks can have large accuracy gaps, up to 31 percent, despite similar formal structure. That is a red flag for claims of broad generalization.
Prompt strategy matters, but less as the number of shots grow. CoT often yields the best peak per problem, but it is also the most sensitive under distribution shift. APO shows a similar pattern. Description and Modus Ponens improve steadily and are comparatively less brittle.
DE helps in some cases but does not overcome OOD sensitivity in aggregate. As the number of exemplars increases, the variance across prompts narrows and the models behave more similarly. This supports the core thesis that ICL is learning regularities from the exemplars rather than fully internalizing task structure in a robust way.
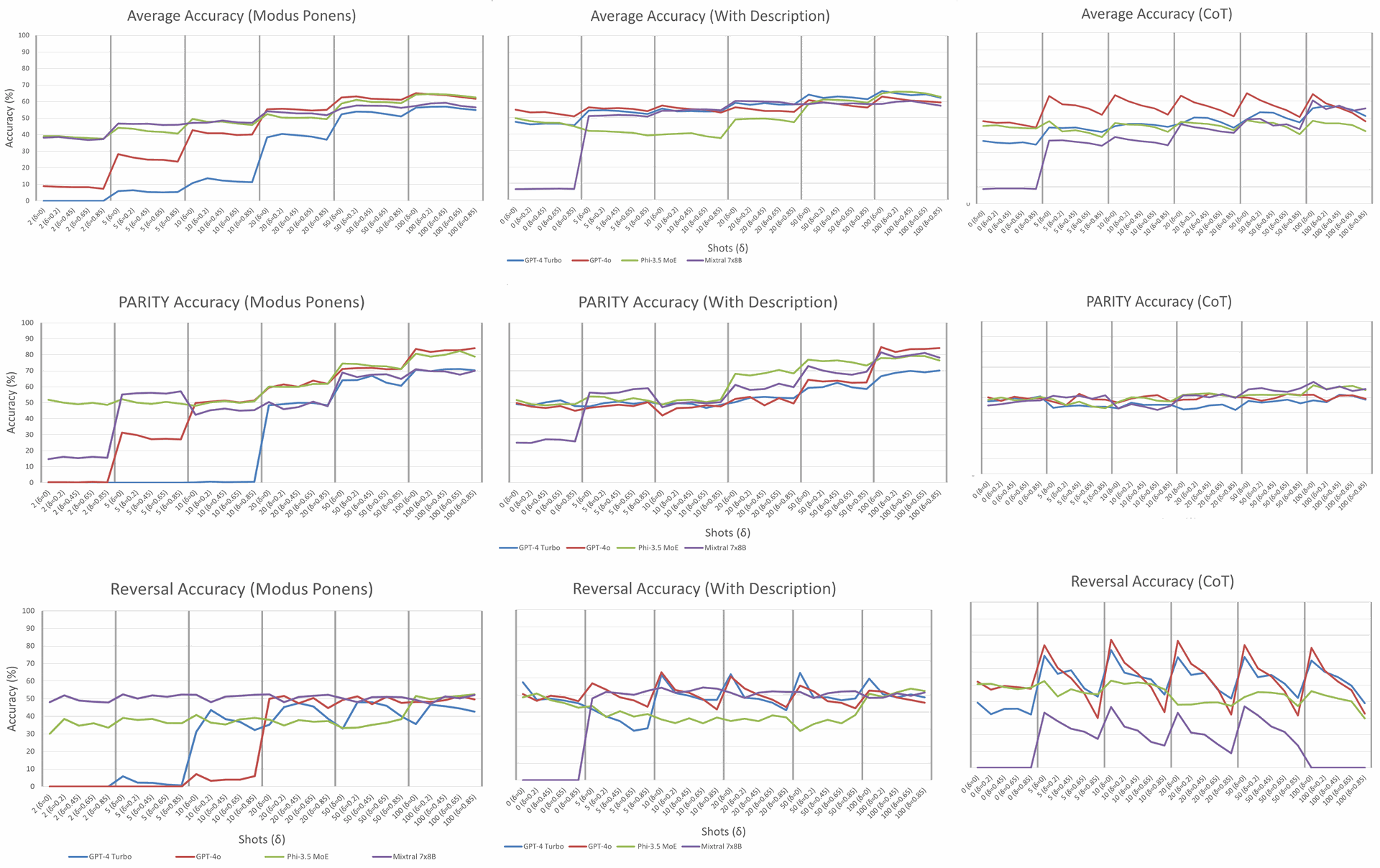
Figure 2: Average accuracy results for (rows, top to bottom) all-task, PARITY, and Reversal in (left to right) modus ponens, description, and CoT; plotted over shots (thick vertical lines) and per-shot δ between them. PARITY showed good performance even though it considered difficult for LLMs (Hahn & Rofin, 2024). Reversal had low average accuracy and was brittle to OOD, with sharp decreases per-shot w.r.t. δ, even as shots increased. Credit: Wynter
Figure 2 plots average accuracy for all tasks, PARITY, and Reversal across shots and
The lexical ablation is particularly interesting. Word-salad versions of Description start poorly but approach the non-randomized baselines as shots increase, with the largest slopes among prompts. SoT, which randomizes CoT exemplars themselves, is much worse on average, yet some models achieve above-random performance on specific tasks. Together these findings suggest that models can separate signal from lexical noise when exemplars are plentiful, but they still struggle to capture relational structure consistently across tasks.
Finally, the exemplar position ablation finds small differences between fixed and shuffled orders when the exemplar set is the same, but fully re-sampling exemplars degrades accuracy and alters shot and shift slopes. This aligns with the view that the model latches on to regularities induced by a specific exemplar set. The distribution alternations with imbalanced or random label regimes further show that measured improvements can reflect superficial regularities rather than deeper task rules.
Conclusion
The study delivers a careful answer to the titular question. Yes, ICL is learning in a formal sense, and with enough exemplars it becomes surprisingly insensitive to prompts and even to natural language itself. But that learning is fragile under distribution shift and uneven across tasks that share formal structure.
The mechanism appears to be an ad hoc encoding tied to autoregression and the exemplar set, not a robust abstraction of task rules. For practitioners, two principles follow: test for OOD explicitly and prefer many exemplars when possible.
For researchers, the results argue for probing beyond best-of numbers, reporting sensitivity curves over shots and shifts, and exploring compositional interfaces that expose structure rather than inferring it from text alone.
Readers can consult the paper for full methodology, appendix prompts, and the released resources. The arXiv version is licensed for non-commercial share-alike use and provides clear references to related work questioning reproducibility and measurement in LLM evaluation ((de Wynter, 2025); (Altmeyer et al., 2024)).
Definitions
- In-Context Learning (ICL): Conditioning a model on examples at inference time and using next-token prediction to perform a task without weight updates.
- n-shot Prompting: Providing
labeled exemplars before the query.
- Chain-of-Thought (CoT): Prompting a model to produce intermediate reasoning steps before the final answer ((Wei et al., 2022)).
- Automated Prompt Optimization (APO): A meta-prompting strategy that tunes a system prompt on a development set; related literature explores expert prompting and agent roles ((Xu et al., 2023/2025)).
- OOD Shift: A change from
to in the data generating process, measured here by .
- Finite State Automaton (FSA) / Pushdown Automaton (PDA): Formal models used to recognize classes of languages that differ in memory requirements.
References
(de Wynter, 2025) Is In-Context Learning Learning?
(Brown et al., 2020) Language Models are Few-Shot Learners
(Wei et al., 2022) Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
(Dan et al., 2022) Understanding Robust Generalization in Learning Regular Languages
(Altmeyer et al., 2024) Position: Stop Making Unscientific AGI Performance Claims


Is In-Context Learning - Learning? Evidence From 1.89M Predictions
Is In-Context Learning Learning?