A new arXiv preprint, LiveMCPBench: Can Agents Navigate an Ocean of MCP Tools, from the Chinese Academy of Sciences and UCAS, introduces a benchmark to test AI agents in realistic tool-rich environments.
The work is grounded in the Model Context Protocol, an open standard for connecting AI systems to external tools and data through a common interface. MCP was introduced by Anthropic and is now supported by an open ecosystem of servers, SDKs, and client integrations.
Key Takeaways
- LiveMCPBench contributes a real, large-scale MCP benchmark with 95 tasks, 70 MCP servers, and 527 tools, emphasizing time-varying, multi-step, and practical daily scenarios (Mo et al., 2025).
- The benchmark package includes LiveMCPTool (a plug-and-play toolset), LiveMCPEval (LLM-as-a-Judge), and an MCP Copilot Agent baseline.
- Across 10 models, the best recorded success rate is 78.95% for Claude Sonnet 4, but overall variance is large and many models underperform in tool-dense settings.
- Evaluation is automated via an LLM judge and shows about 81 percent agreement with human reviewers using DeepSeek V3 as evaluator.
- The paper highlights frequent retrieval mismatches and parameter errors as key failure modes, pointing to retrieval quality and memory/precision as major research targets.
What the authors built
The benchmark targets a gap in current evaluation. Many tool-use tests rely on simulated or unstable APIs that drift over time, limiting generalization and realism. MCP offers a standardized, stable call surface for tools, which enables experiments at larger scale and with fewer brittle dependencies. LiveMCPBench organizes evaluation around three components:
LiveMCPTool is a curated collection of 70 servers and 527 tools. The team began with thousands of public server configurations and filtered out deployments that require private API keys, then manually validated functionality and taxonomy to emphasize reproducibility. The resulting set spans discovery, visualization, file access, code, entertainment, finance, location, and miscellaneous utilities.
LiveMCPEval is an automated LLM-as-a-Judge pipeline that grades agent trajectories for success or failure given the task description, a set of key points, the tool sequence, and tool descriptions. Key points are either human-annotated or LLM-generated. With DeepSeek V3 as the judge, the pipeline achieves around 81 percent agreement with human annotators, which is competitive with other LLM-as-a-Judge setups and provides scale advantages (Liu et al., 2025).
MCP Copilot Agent is a ReAct-style agent that can retrieve tools, plan, and execute multi-step sequences across MCP servers. Retrieval prioritization combines similarity between server descriptions and tool descriptions, inspired by prior large-scale retrieval work. The agent is framed as a Partially Observable Markov Decision Process (POMDP) where the system must act under partial observability using tool outputs and descriptions.
Why it matters
Tool-use is a critical capability for practical AI systems. As organizations standardize on MCP, the question shifts from "can an LLM call a tool" to "can an agent dynamically discover the right tools and compose them into robust workflows".
Traditional benchmarks often abstract away the hardest parts of this problem. LiveMCPBench places agents in a setting that resembles day-to-day usage: dynamic information, incomplete knowledge, hierarchical tool catalogs, and the need to troubleshoot failures.
The community has started to formalize MCP evaluation with efforts like MCP-RADAR, which proposes multi-dimensional metrics including accuracy, efficiency, and parameter construction quality (Gao et al., 2025), and MCPEval, which automates generation and evaluation across diverse domains (Liu et al., 2025). LiveMCPBench complements these by focusing on scale and realism with a plug-and-play toolset and time-varying daily tasks.
How the benchmark is structured
The task suite spans six domains: Office, Lifestyle, Leisure, Finance, Travel, and Shopping. The authors emphasize three properties: time-varying outcomes, long-horizon multi-tool use, and genuine utility.
Annotation followed a two-pass process where proposers designed and executed tasks with the toolset and validators de-duplicated and enforced quality.
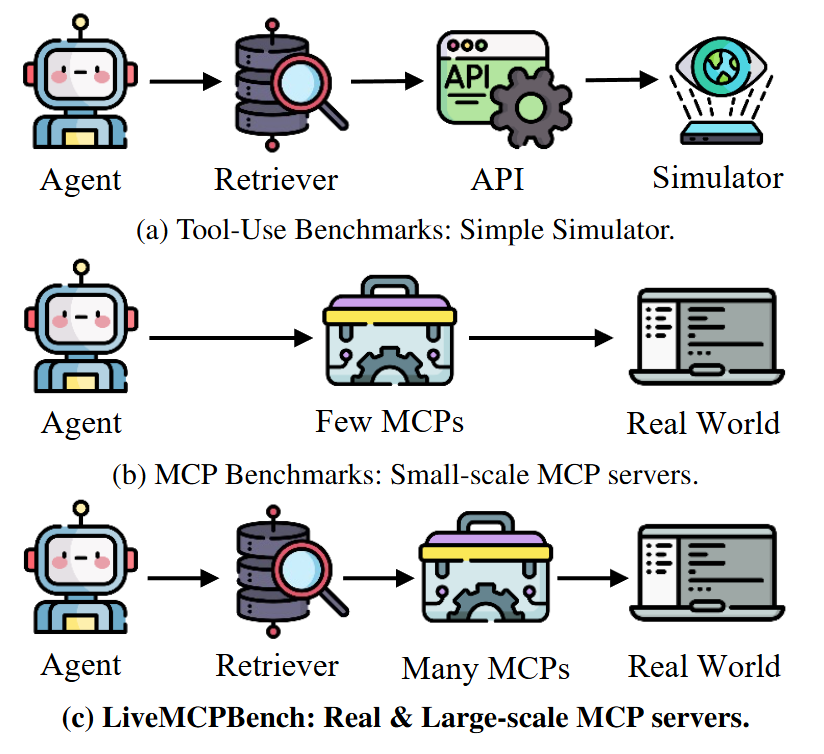
Figure 1 compares LiveMCPBench to prior tool-use and MCP benchmarks. The key distinction is the scale and realism of the MCP tool environment, moving beyond small static tool lists toward a larger and more dynamic setting.
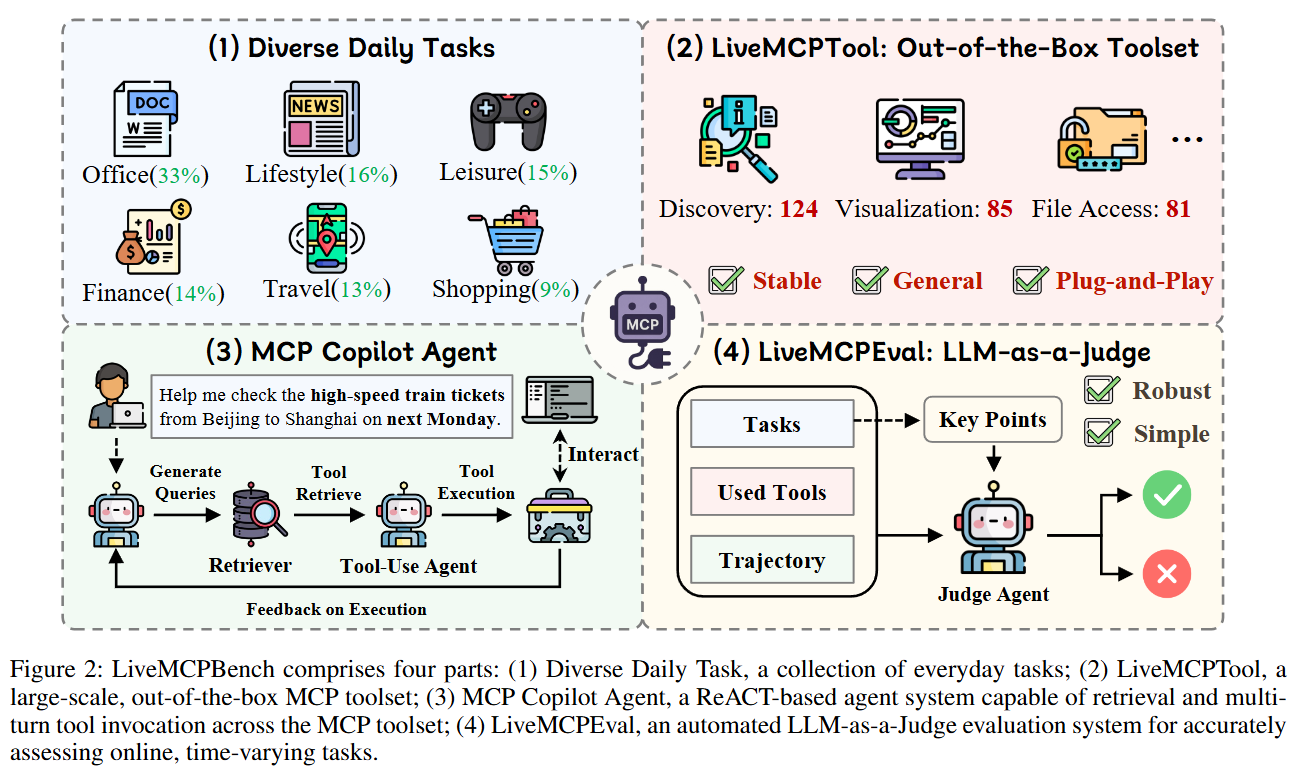
Figure 2 outlines the system: task set, toolset, baseline agent, and automated evaluation.
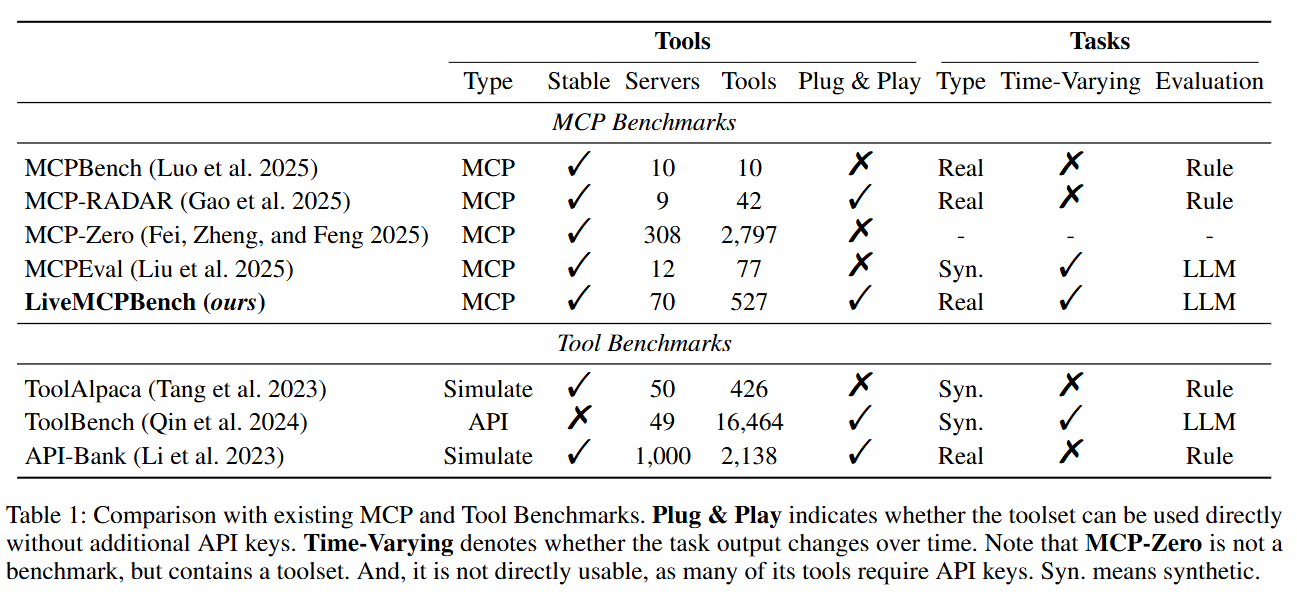
Table 1 contrasts LiveMCPBench with other datasets and shows that it is plug-and-play and time-varying, while many alternatives are simulated or require private keys.
Results at a glance
The authors evaluate 10 leading models with the MCP Copilot Agent policy. Using DeepSeek V3 as the evaluator, Claude Sonnet 4 reaches a 78.95 percent success rate, followed by Claude Opus 4 at 70.53 percent. Most other models land around 30 to 50 percent. Domain-wise, Claude models are especially strong on Office and Lifestyle tasks.
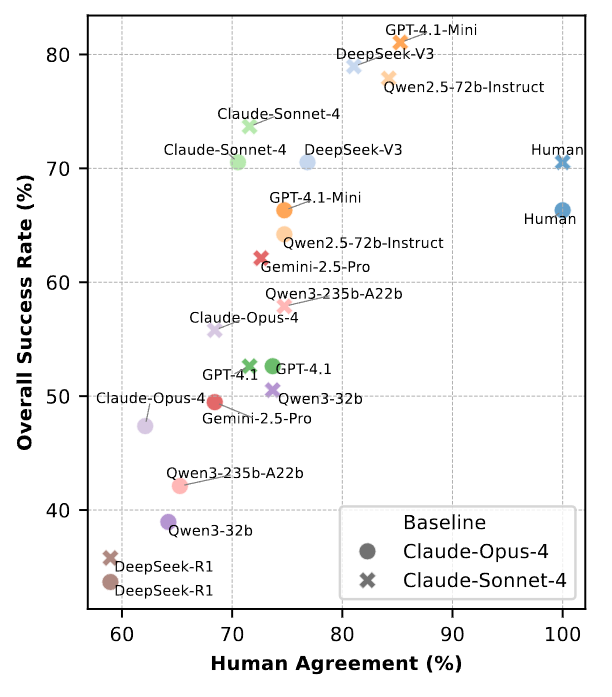
Figure 3 examines correlation between model performance and human agreement across evaluators. DeepSeek V3 delivers the best agreement in these tests, around 79 to 81 percent, with GPT-4.1 Mini and Qwen2.5-72B-Instruct in the mid 70s.
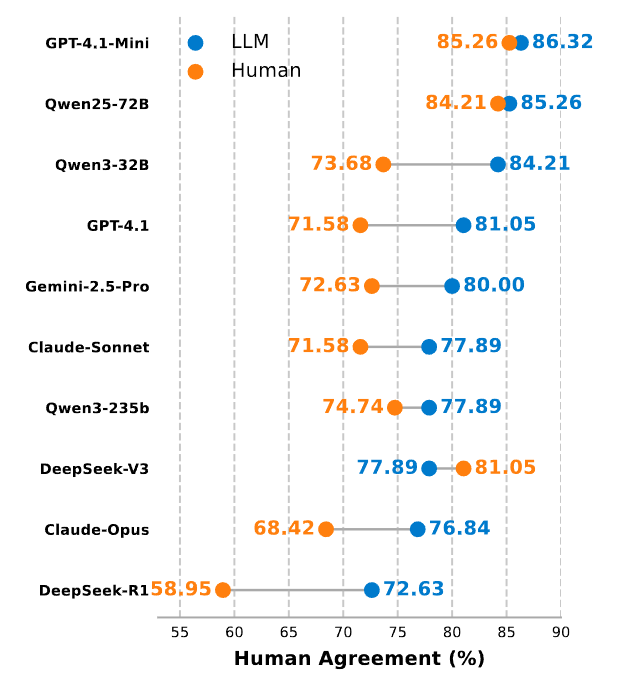
Figure 4 shows that LLM-generated key points can work as a reasonable substitute when human references are unavailable, which is useful for scaling evaluation.
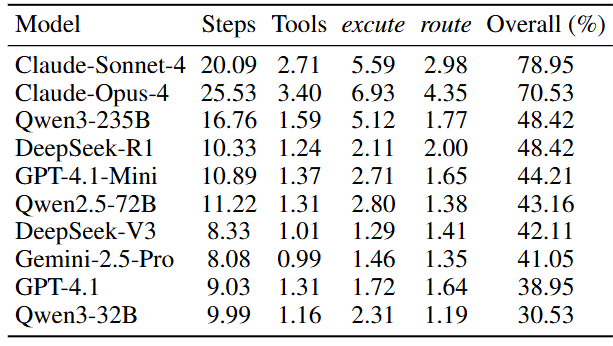
Table 3 sheds light on behavior: Claude agents retrieve and execute more frequently and employ more tools per task, suggesting a stronger tendency to explore and exploit the tool environment. Many models underutilize the toolset, often settling on a single tool and not revisiting retrieval even when progress stalls.
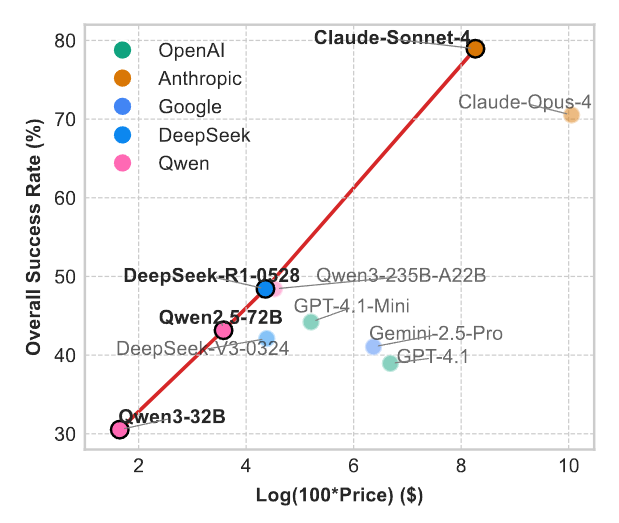
Figure 5 plots cost versus performance and highlights a near-linear Pareto frontier; depending on budget, candidates like Qwen3-32B, Qwen2.5-72B-Instruct, DeepSeek-R1-0528, and Claude Sonnet 4 offer distinct cost-performance trade-offs.
Where agents fail
The error analysis groups failures into four categories: Query, Retrieve, Tool, and Other.
- Query errors happen when the agent crafts an unhelpful retrieval query or chases an omnipotent tool rather than composing specialized ones.
- Retrieve errors are the dominant category and point to semantic gaps in matching queries to tools, especially in hierarchical server-tool directories.
- Tool errors arise from parameter mistakes or misreading required fields.
- Other covers network timeouts and brittle framework behaviors without recovery. Figures 12 through 15 illustrate these cases.
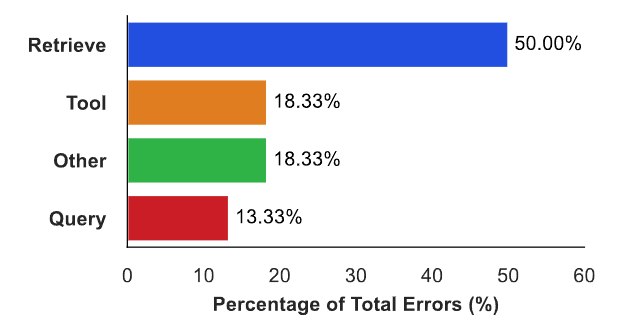
Figure 6 summarizes error distributions for advanced Claude agents and reinforces the retrieval bottleneck. The takeaway is clear: even strong reasoners struggle when retrieval pipelines miss semantically equivalent capabilities, and agent frameworks need more resilient retry and feedback strategies.
Limitations and context
The authors are careful to state limitations. LiveMCPEval depends on LLM judgment, which introduces model bias despite reasonably high human agreement.
Evaluation assumes that trajectories and tool descriptions accurately reflect task completion, which can drift as toolsets grow.
Finally, long trajectories can challenge evaluators, occasionally leading to false positives when a step like file creation is mistaken for task completion. The paper suggests more stepwise assessments could mitigate this but at a cost to throughput.
More broadly, LiveMCPBench sits alongside a growing body of MCP-focused evaluation and retrieval work, including MCPEval (Liu et al., 2025) and MCP-RADAR (Gao et al., 2025). It also aligns with Anthropic's push for an open MCP ecosystem spanning server implementations and clients (Anthropic, 2024).
Conclusion
LiveMCPBench is a timely step toward more realistic and scalable evaluation of agentic tool use in MCP ecosystems. The combination of a large plug-and-play toolset, time-varying tasks, an automated evaluator, and a baseline agent offers a practical way to compare models beyond synthetic or narrow settings.
The results show that leading models can approach 80 percent success, but also that many systems struggle to retrieve and compose tools reliably.
For practitioners, the benchmark suggests focusing on retrieval quality, parameter accuracy, and robust failure handling. For researchers, it raises questions about meta-tool-learning, hierarchical retrieval, and long-horizon evaluation.
The authors say code and data will be public at the project page: https://icip-cas.github.io/LiveMCPBench (Mo et al., 2025). Read the paper for full details.


Introducing LiveMCPBench: Evaluating Models on Large Tool Set Usage
LiveMCPBench: Can Agents Navigate an Ocean of MCP Tools?