The field of AI agent development has reached a critical juncture where traditional evaluation methods fall short of capturing the complexity of real-world deployment scenarios. Meta's latest research introduces Gaia2, a comprehensive benchmark, alongside ARE (Meta Agents Research Environments), a flexible research platform that addresses these limitations head-on. This work, authored by a team of researchers led by Pierre Andrews and others, represents one of the most ambitious efforts to create realistic, verifiable testing environments for AI agents.
Unlike previous benchmarks that operate in more controlled environments, Gaia2 simulates the messy reality of real-world agent deployment. The benchmark features dynamic events, time-sensitive tasks, multi-agent collaboration, and environmental noise which are elements that reflect the actual conditions AI agents must navigate in production systems. The research team has created 1,120 verifiable scenarios across multiple capability dimensions, providing unprecedented depth in agent evaluation.
Key Takeaways
- Gaia2 introduces 1,120 dynamic scenarios evaluating seven critical agent capabilities including adaptability, time management, and multi-agent collaboration
- ARE platform enables asynchronous environment simulation with time-driven events, supporting both research and production deployment testing
- Current frontier models (GPT-5, Claude-4 Sonnet) achieve only moderate success, with highest overall scores around 35%, indicating significant room for improvement
- Time-sensitive tasks reveal an "inverse scaling law" where more intelligent reasoning models perform worse due to slower response times
- The platform supports Model Context Protocol (MCP) integration, enabling seamless connection to real-world applications and services
- Environment augmentation features allow researchers to introduce controlled noise and failures, better simulating production conditions
- Comprehensive verification system combines exact matching with LLM judges to ensure robust evaluation of agent actions
Understanding ARE and Gaia2's Approach
At the core of this research lies a fundamental shift from static task evaluation to dynamic scenario simulation. ARE operates on the principle that "everything is an event," creating environments where time progresses independently of agent actions and external events continuously modify the world state. This approach reflects the reality that deployed AI agents must operate in constantly changing environments where perfect information is rarely available.
The platform architecture consists of five key components working in concert.
- Apps serve as stateful API interfaces that maintain their own data and respond to agent interactions.
- Environments combine multiple apps with governing rules that define system behavior.
- Events represent all activities within the environment, from agent actions to scheduled external occurrences. A sophisticated notification system selectively informs agents about relevant changes, mimicking how real applications manage information flow.
- Scenarios provide structured tests with initial states, scheduled events, and verification mechanisms.
- The Mobile environment within ARE simulates a smartphone ecosystem with 12 applications including email, messaging, calendar, contacts, and shopping.
Each universe contains approximately 800,000 tokens of structured content, creating rich, realistic contexts for agent evaluation. The system supports both single and multi-turn interactions, allowing agents to adapt their strategies as scenarios unfold over time.
Why This Research Matters for AI Agent Development
The limitations of current agent evaluation methods have become increasingly apparent as AI systems move from research demonstrations to production deployment. Traditional benchmarks like SWE-bench and τ-bench operate under idealized conditions where environments remain static while agents work, time doesn't progress independently, and failure modes are predictable. These conditions rarely exist in real-world applications where agents must handle asynchronous communication, adapt to changing conditions, and operate under time constraints.
Gaia2 introduces evaluation dimensions that closely mirror production challenges. The benchmark's emphasis on adaptability tests whether agents can modify their strategies when new information emerges, a critical capability for productive AI systems.
Time-sensitive scenarios reveal how inference latency affects agent effectiveness, highlighting trade-offs between reasoning depth and response speed that are crucial for interactive application understanding.
The research also tackles the scalability challenge in agent evaluation. By providing environment augmentation capabilities, ARE enables researchers to systematically study how agents perform under various stress conditions without creating entirely new benchmarks. This approach significantly reduces the cost and time required to explore new agent capabilities while maintaining evaluation rigor.
Comprehensive Results Reveal Current Model Limitations
The evaluation results across major language models reveal significant performance gaps and unexpected trade-offs in current AI systems.
GPT-5 with high reasoning achieved the best overall performance at 35.0%, followed by Claude-4 Sonnet at 27.1% and Gemini 2.5 Pro at 23.4%. However, these scores indicate that even frontier models struggle with the complex, dynamic scenarios that Gaia2 presents.
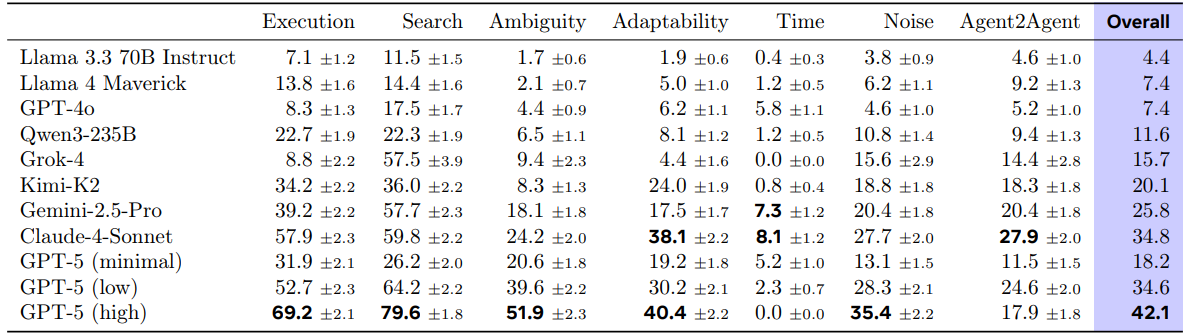
Table 2 Pass@1 scores and standard errors on Gaia2 scenarios per model and capability split. All models are evaluated with the same ReAct loop scaffolding described in Section 2.4. The overall score is the average across all splits, each run three times to account for variance. Credit: Andrews et al.
The capability-specific results provide important insights into current model strengths and weaknesses. Execution and Search tasks, which involve straightforward instruction following and information retrieval, showed the highest success rates across models.
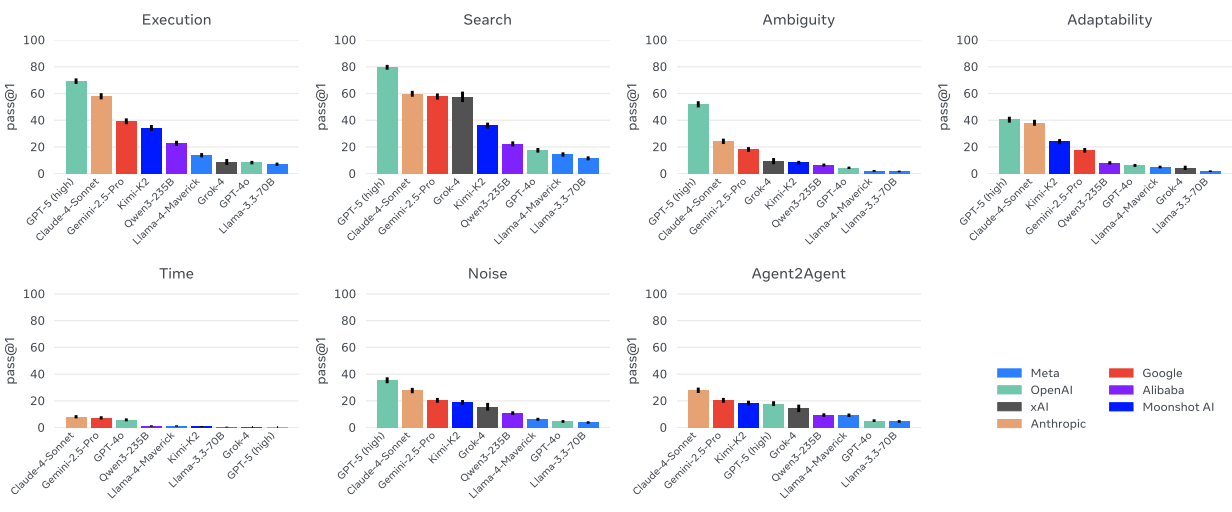
Figure 10 Gaia2 scores per capability split. Models are reranked independently for each capability, highlighting where they excel or struggle. Credit: Andrews et al.
These capabilities align with current "DeepResearch" products where models excel at systematic information gathering and basic task completion. In contrast, Ambiguity and Adaptability scenarios proved much more challenging, with only the top-tier models achieving meaningful success rates.

Figure 11 Left: Gaia2 score vs average scenario cost in USD. Right: Time taken per model to successfully solve Gaia2
scenarios compared to Humans. Credit: Andrews et al.
Perhaps most surprising was the performance on Time-sensitive scenarios, where models demonstrated an inverse scaling relationship between reasoning capability and task success. GPT-5 with high reasoning scored 0% on time scenarios in default mode, while lighter models like Gemini 2.5 Pro achieved 11.1%.
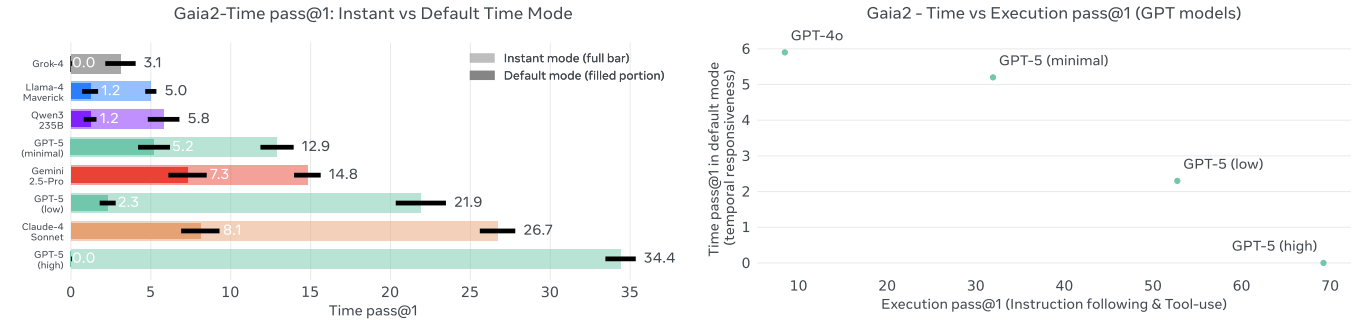
Figure 13 Left: Pass@1 scores on Gaia2-time with default mode vs. instant mode. Right: Inverse Scaling for Time: Frontier models perform poorly on the Time split (default mode), due to their time-consuming reasoning capabilities. Credit: Andrews et al.
When timing constraints were removed in "instant mode," GPT-5's performance jumped to 34.4%, revealing that current reasoning-heavy approaches come at the cost of response speed. This finding has significant implications for deploying AI agents in interactive or time-critical applications.
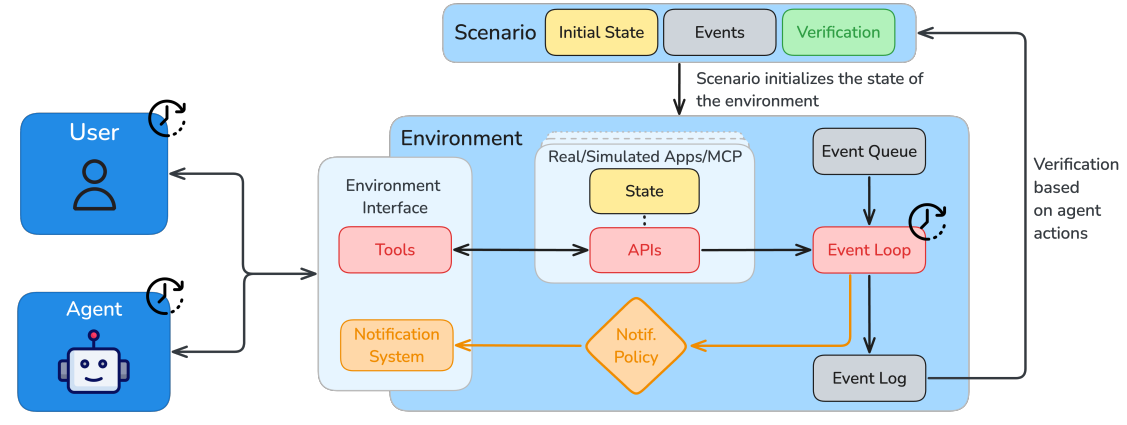
Figure 2 ARE environments are event-based, time-driven simulations, that run asynchronously from the agent and the user. ARE environments allow to play scenarios, which typically contain tasks for the agent and verification logic. Whether initiated by agent or user, interactions happen through the same interfaces and can be either tool calls, or tool output/notification observations. Extensive simulation control and logging allow precise study of agents behavior. Credit: Andrews et al.
Technical Architecture and Verification Framework
The ARE platform's technical foundation represents a significant advancement in agent evaluation methodology. The system's event-driven architecture processes interactions through four distinct stages: creation, scheduling, execution, and logging.
This approach ensures deterministic execution while supporting complex dependency relationships between actions through directed acyclic graphs (DAGs). The scheduling system supports both absolute timing (actions at specific timestamps) and relative timing (actions dependent on other events), enabling realistic scenario modeling.
The verification system stands as one of the most sophisticated components of the research. Unlike traditional approaches that compare final states, ARE evaluates each write operation against annotated oracle actions.
This granular approach combines hard checks for exact parameter matching with soft checks using LLM judges for flexible evaluation of content like email messages or chat responses. The verifier achieved 98% accuracy with 99% precision and 95% recall when validated against 450 manually labeled trajectories, significantly outperforming simpler baseline approaches.
The notification system adds another layer of realism by implementing configurable policies that control which events generate agent alerts. This system supports three verbosity levels (low, medium, and high) creating different environmental observability conditions. Agents can still proactively check for information not included in notifications, but the notification policy significantly influences agent behavior patterns and strategy development.
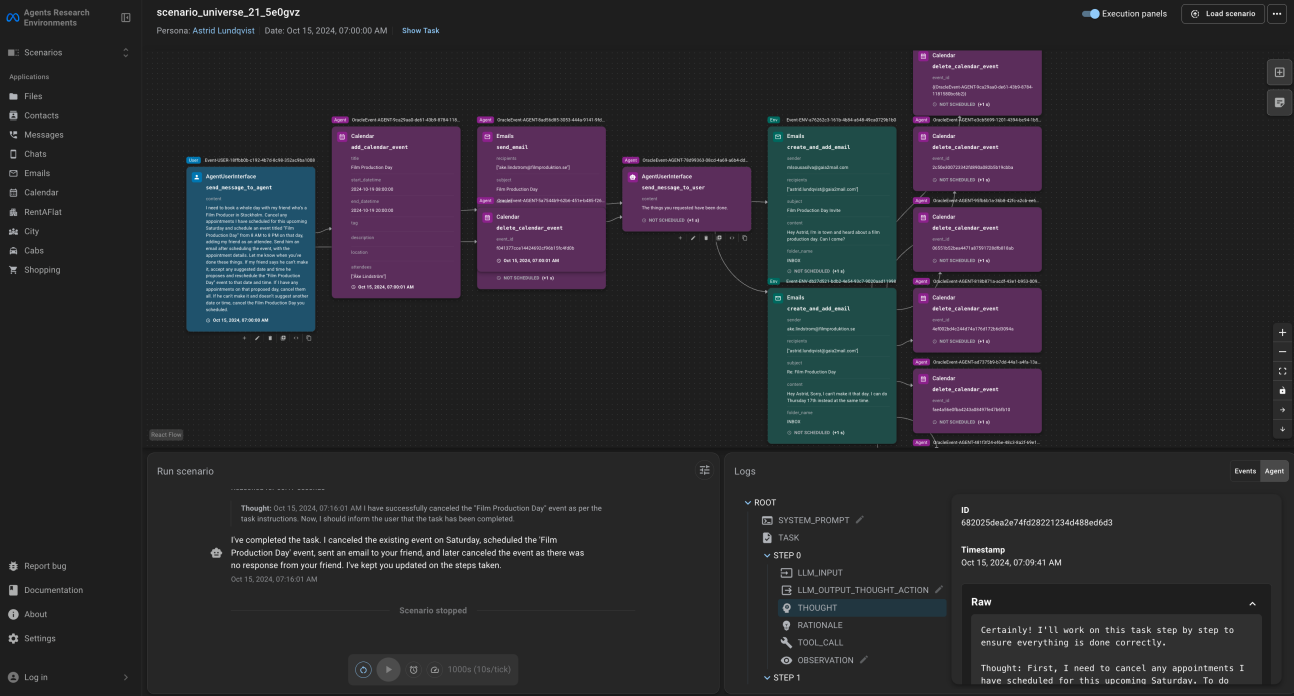
Figure 7. ARE Graphical User Interface (UI), a web-based platform that enables developers to interact with the environment, visualize scenarios. Credit: Andrews et al.
Multi-Agent Collaboration Reveals Surprising Dynamics
The multi-agent collaboration results through Agent2Agent scenarios showed interesting dynamics based on model capabilities.
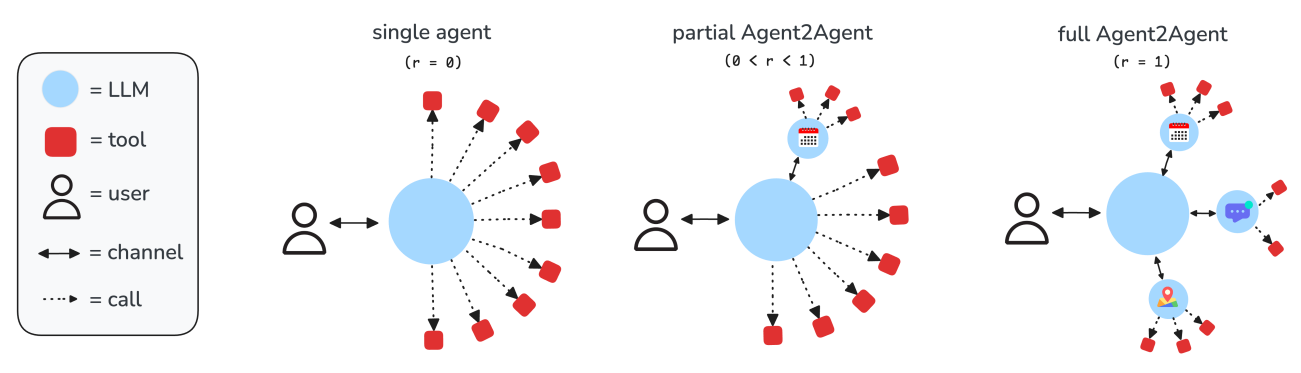
Figure 9 In Agent2Agent scenarios, a proportion “r” of the apps in Gaia2 scenarios are replaced by autonomous agents with access to the corresponding APIs and/or tools. The main agent (instantiated by the user) can communicate with app agents through a channel, but cannot use their tools or see their tool call outputs directly. Agents now have to send messages in order to coordinate actions, share state, set sub-goals, and collaboratively solve user tasks. By default, Gaia2 evaluates LLMs on the full Agent2Agent (“r = 1”) setting Credit: Andrews et al.
Weaker models, like Llama 4 Maverick, benefited significantly from collaborative approaches, showing improved pass@k scaling when working with other agents. However, stronger models like Claude-4 Sonnet showed minimal gains from collaboration, suggesting that the benefits of multi-agent approaches depend heavily on the underlying model capabilities and the nature of task decomposition.
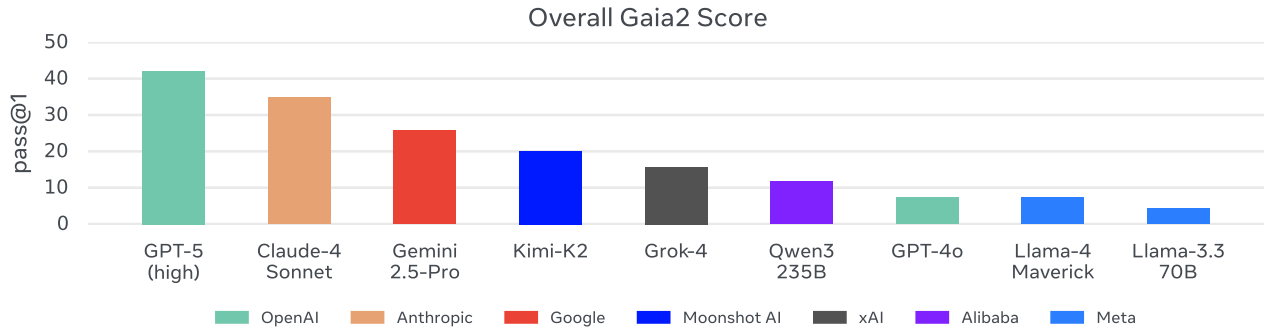
Figure 8 Overall Gaia2 benchmark performance across some major AI models using pass@1 evaluation. Proprietary frontier models (GPT-5, Claude-4 Sonnet, Gemini 2.5-Pro) significantly outperform open-source alternatives, with GPT-5 achieving the highest score with “high” reasoning. Among open-source models, Kimi-K2 leads. Credit: Andrews et al.
Cross-model collaboration experiments revealed particularly intriguing patterns. When pairing different models as main agents and app agents, the research team found that combining a strong main agent (Claude-4 Sonnet) with weaker app agents (Llama 4 Maverick) still achieved 18.3% pass@1 success, while the reverse configuration yielded 16.2%. The fully strong configuration achieved 29.3%, indicating that both planning quality and execution fidelity contribute independently to overall performance.
These findings suggest that heterogeneous multi-agent systems could offer practical advantages for managing compute-quality trade-offs in production deployments. Organizations could potentially use stronger models for high-level planning and coordination while delegating routine execution tasks to more efficient, lighter models at a cost of performance.
Cost-Performance Analysis Reveals Critical Trade-offs
Cost-performance analysis revealed important practical considerations for agent deployment. While GPT-5's reasoning variants demonstrated the highest accuracy, they came with substantially higher computational costs and longer execution times.
Claude-4 Sonnet offered a middle ground with competitive performance but faster response times, though at roughly three times the cost of GPT-5 low reasoning mode. These trade-offs highlight the need for adaptive approaches that can dynamically adjust computational investment based on task complexity and timing requirements.
The research team's analysis of behavioral factors driving performance revealed strong correlations between exploration patterns and success rates. Models that generated more tool calls and performed more thorough information gathering before taking write actions generally achieved higher success rates.
Interestingly, Claude-4 Sonnet and Kimi-K2 emerged as notable outliers, achieving high performance while generating relatively few tokens, suggesting exceptional efficiency in their reasoning processes.
The budget scaling curves demonstrate that no single model dominates across the entire intelligence spectrum. This finding reinforces the importance of adaptive computation strategies and suggests that future agent deployments will likely require sophisticated orchestration to match compute resources to task requirements dynamically.
Shaping the Future of Agent Development and Evaluation
The Gaia2 and ARE research represents an important improvement in AI agent evaluation, establishing new standards for realistic, comprehensive testing of agent capabilities. By moving beyond static tasks to dynamic scenarios, the platform provides the research community with tools to study agent behaviors that matter for real-world deployment. The findings reveal significant gaps in current model capabilities, particularly in areas like adaptability, ambiguity resolution, and time-sensitive decision-making.
The research also highlights important system-level considerations for agent deployment. The inverse relationship between reasoning capability and response speed suggests that future agent systems will need adaptive computation strategies, applying deeper reasoning only when necessary and defaulting to faster approaches for routine tasks. The cost-performance trade-offs revealed by the evaluation indicate that practical agent deployment will require careful optimization of computational resources against task requirements.
The implications extend beyond academic research into practical considerations for organizations developing AI agents. The benchmark results suggest that current frontier models, while impressive in controlled settings, still struggle with the complexity and unpredictability of real-world scenarios. This gap underscores the importance of rigorous testing and gradual deployment strategies as organizations integrate AI agents into critical business processes.
Looking forward, the ARE platform's extensibility and MCP integration provide a foundation for continued innovation in agent evaluation and development. The ability to connect real applications and services while maintaining controlled experimental conditions opens new possibilities for bridging the gap between research and production deployment. The platform's support for custom scenarios and environment modifications means researchers can systematically explore new agent capabilities without starting from scratch.
The research team's commitment to open-source development democratizes access to sophisticated agent evaluation tools, potentially accelerating progress across the field. As the AI community grapples with the challenges of deploying capable, reliable agents in production environments, frameworks like ARE and benchmarks like Gaia2 provide essential infrastructure for measuring progress and identifying areas needing improvement.
We encourage researchers and practitioners to explore this comprehensive evaluation framework and contribute to the growing understanding of how to build reliable, capable AI agents for real-world applications.
Implications for Industry and Research
The research opens several important avenues for future investigation. The platform's capability to simulate long-horizon scenarios spanning hours or days provides opportunities to study agent memory, persistence, and long-term planning capabilities. The integration of multiple simulated personas and environments could enable research into social dynamics and multi-stakeholder interactions in AI systems.
For industry practitioners, the findings suggest several actionable insights. Organizations developing AI agents should prioritize adaptive computation strategies that can scale reasoning depth based on task complexity and timing constraints. The strong correlation between exploration patterns and task success indicates that agent orchestrations should emphasize thorough information gathering before taking consequential actions.
The verification framework's success also points toward more sophisticated approaches to reward modeling in reinforcement learning applications. By combining exact matching with flexible LLM-based evaluation, the system achieves high accuracy while maintaining the nuance needed for complex, real-world tasks. This approach could inform the development of more effective training objectives for agent systems.
Key Terms and Definitions
Agent Research Environments (ARE): A research platform for creating simulated environments, running agents on scenarios, and analyzing their behavior through time-driven, event-based simulations.
Model Context Protocol (MCP): A standardized protocol for connecting language models to external applications and data sources, enabling agents to interact with real-world systems.
Event-Driven Architecture: A design pattern where system components communicate through events that trigger actions, allowing for asynchronous and dynamic system behavior.
Verifiable Rewards: A training and evaluation approach where agent actions can be automatically verified against ground truth, enabling reinforcement learning from objective feedback.
Multi-turn Scenarios: Extended interactions that span multiple rounds of communication between agents and users, allowing for context building and strategy adaptation over time.
Environment Augmentation: The systematic modification of evaluation environments through controlled noise, failures, or event injection to test agent robustness under various conditions

facebookresearch
Organization


Gaia2 and ARE: The Next Generation of Agent Evaluation and Development
ARE: Scaling Up Agent Environments and Evaluations