Language in the wild is messy and continuous. People interrupt, pause, speak over each other, and weave context over minutes and hours. The paper by Goldstein et al. takes this complexity seriously.
Rather than relying on short, controlled stimuli, the authors recorded electrocorticography (ECoG) continuously across roughly 100 hours of open-ended conversations (approx 500k words) and asked a direct question: does a single multimodal model of speech and language provide a representational space that maps onto human brain activity during both speaking and listening in everyday settings?
The team uses Whisper, a popular speech-to-text model that learns from paired audio and transcripts, to extract three types of embeddings per word: low-level acoustic, mid-level speech, and higher-level language.
With simple linear encoding models, they show that these embeddings predict neural activity across hours of held-out conversations and that the model’s internal hierarchy aligns with a cortical hierarchy from sensorimotor to language areas.
Just as critically, the timing of these signals flips as expected between production and comprehension, capturing planning before articulation and perception after word onset.
Key Takeaways
- Dense, ecological recordings: ECoG captured continuous brain activity while participants engaged in natural conversations, then segments were labeled as production or comprehension.
- Unified embeddings: Acoustic, speech, and language embeddings from Whisper each explain distinct parts of the neural signal across cortex and time.
- Predicts unseen conversations: Linear models trained on one slice of data generalize to hours of conversations not used in training.
- Hierarchy matches cortex: Sensorimotor regions align better with speech embeddings, higher-order temporal and frontal areas align better with language embeddings.
- Timing matches function: Language-to-speech activity precedes articulation in production; speech-to-language activity follows articulation in comprehension.
- Beats symbolic baselines: Distributed embeddings capture neural variance better than features like phonemes or parts of speech.
- Generalization holds with reduced training data, suggesting robust mapping rather than overfitting to specific conversations.
Overview
The study introduces a dense-sampling ECoG paradigm: four patients were recorded continuously in an epilepsy monitoring unit while conversing freely with staff, family, and friends. This yielded approximately 50 hours of speech comprehension (about 290k words) and 50 hours of speech production (about 230k words).
The authors segmented audio and transcripts into word-level events and aligned them with ECoG time courses for 644 left-hemisphere electrodes, focusing analyses there due to limited right-hemisphere coverage.
Whisper is a large-scale model trained on weakly supervised audio-text pairs, designed to be robust and multilingual ((Kim et al., 2022)). Its encoder learns contextual speech features from audio, and its decoder produces word tokens conditioned on both speech features and prior text.
This architecture affords a principled way to study acoustic-to-speech-to-language transformations in continuous conversation, complementing unimodal LLMs that capture rich linguistic context from text alone ((Radford et al., 2018); (Brown et al., 2020)).
At the heart of the study is the idea that a shared, continuous embedding space can bridge multiple levels of processing. Whisper provides that bridge. The authors extract three representations for each word token:
1) Acoustic embeddings from a static encoder that summarizes local audio cues.
2) Speech embeddings from the top encoder layer that capture higher-level speech features useful for recognition.
3) Language embeddings from the decoder that situate words in their sentence context. Each vector is reduced to 50 dimensions via principal component analysis (PCA) to standardize input size across models and to mitigate overfitting.
On the neural side, four patients with left hemisphere ECoG grids were recorded continuously in an epilepsy monitoring unit. Conversations with staff, family, and friends were transcribed. Word onsets served as temporal anchors.
For every electrode and every 25 ms window from -2000 ms to +2000 ms around each word, the authors fit a linear regression that maps embeddings to neural activity.
Model performance is the correlation between predicted and actual signals on left-out test words, repeated over many words and hours. This procedure was run independently for the three embedding types, yielding spatiotemporal performance maps across cortex.
Why it matters
Most brain-language studies use symbolic features such as phonemes or parts of speech. Those are interpretable but brittle, and they often fail to capture the mixed, context-sensitive nature of conversation.
Whisper’s embedding space replaces discrete labels with continuous vectors that implicitly carry information about acoustics, articulation, and context. Showing that these vectors linearly predict neural activity in both production and comprehension suggests a deep structural correspondence between modern speech-language models and cortical processing.
The implications are interesting and practical. For brain-computer interfaces, embedding spaces can serve as priors or constraints when decoding attempted speech, potentially improving robustness in noisy, real-world settings.
For cognitive neuroscience, these models provide quantitative probes for where and when different information types emerge in cortex during everyday language use, narrowing the gap between lab tasks and real-life behavior.
Discussion of results
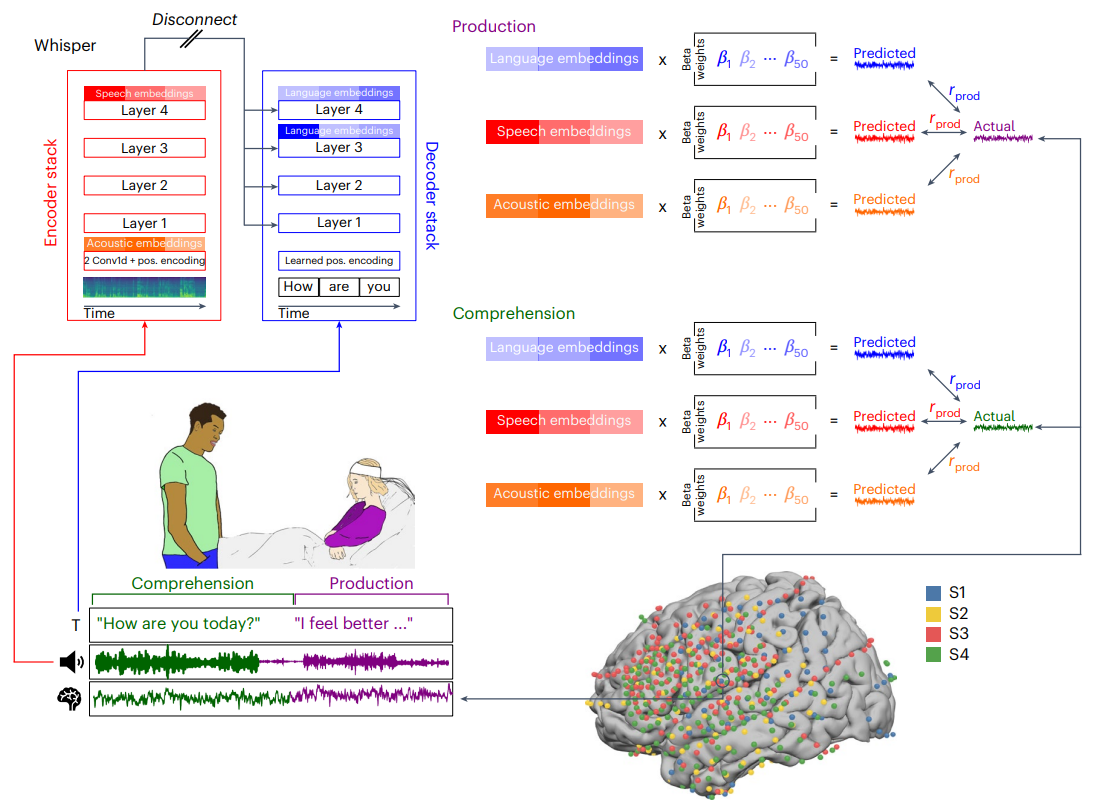
Fig. 1 | An ecological, dense-sampling paradigm for modelling neural activity during real-world conversations. We monitored continuous neural activity in 4 ECoG patients during their interactions with hospital staff, family and friends, providing a unique opportunity to investigate real-world social communication. Simultaneously recorded verbal interactions are transcribed and segmented into production (purple) and comprehension (green) components (bottom left). We used Whisper, a deep speech-to-text model, to process our speech recordings and transcripts, and extracted embeddings from different parts of the model: for each word, we extracted ‘acoustic embeddings’ from Whisper’s static encoder layer, ‘speech embeddings’ from Whisper’s top encoder layer (red), and ‘language embeddings’ from Whisper’s decoder network (blue) (top left). The embeddings were reduced to 50 dimensions using PCA. We used linear regression to predict neural signals from the acoustic embeddings (orange), speech embeddings (red) and language embeddings (blue) across tens of thousands of words. We calculated the correlation between predicted and actual neural signals for left-out test words to evaluate encoding model performance. This process was repeated for each electrode and each lag, using a 25-ms sliding window ranging from −2,000 to +2,000 ms relative to word onset (top right). Bottom right: brain coverage across 4 participants comprising 654 left hemisphere electrodes. Credit: A Goldstein et al.
Experimental design and performance: (Figure 1 and Figure 2). Figure 1 lays out the full pipeline and the dense-sampling paradigm: 24/7 recordings, segmentation into production vs. comprehension, extraction of acoustic, speech, and language embeddings, PCA to 50 dimensions, and linear encoding across lags. The brain coverage map includes 654 left hemisphere electrodes across four participants, which is critical context for interpreting spatial patterns.
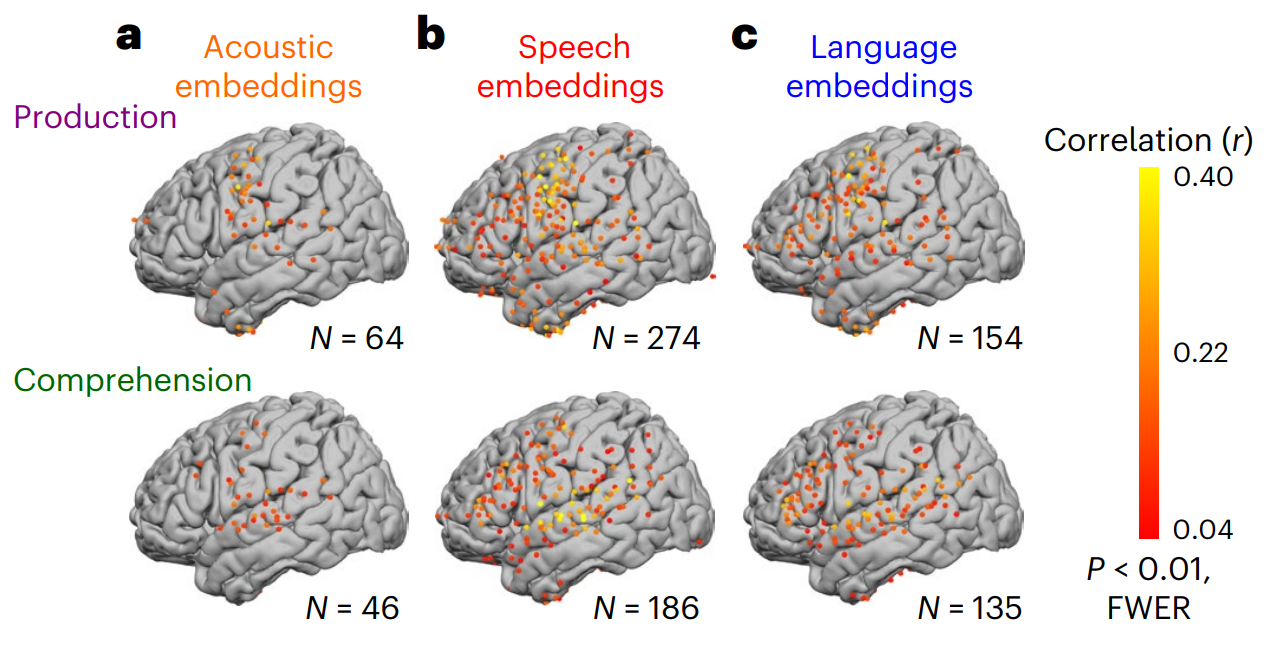
Fig. 2 | Acoustic, speech and language encoding model performance during speech production and comprehension. Encoding performance (correlation between model-predicted and actual neural activity) for each electrode for acoustic embeddings, speech embeddings and language embeddings during speech comprehension (~50 h, 289,971 words) and speech production (~50 h, 230,238 words). The plots illustrate the correlation values associated with the encoding for each electrode, with the colour indicating the highest correlation value across lags (P < 0.01, FWER). a, Encoding based on acoustic embeddings revealed significant electrodes in auditory and speech areas along the superior temporal gyrus (STG) and somatomotor areas (SM). During speech production, we observed enhanced encoding in SM, and during speech comprehension, we observed enhanced encoding in the STG. b, Encoding based on speech embeddings revealed significant electrodes in STG and SM, as well as the inferior frontal gyrus (IFG; Broca’s area), temporal pole (TP), angular gyrus (AG) and posterior middle temporal gyrus (pMTG; Wernicke’s area). c, Encoding based on language embeddings highlighted regions similar to speech embeddings (b) but notably fewer electrodes (with lower correlations) in STG and SM, and higher correlations in IFG. Credit: A Goldstein et al.
Figure 2 emphasizes spatial dissociations consistent with a cortical hierarchy. In sensory and motor regions involved in hearing and articulation, speech embeddings often yield higher predictive correlations than language embeddings. In contrast, regions typically linked to higher-level language processing show stronger alignment with language embeddings. This pattern supports the central claim that the model’s internal levels correspond to functionally distinct brain areas.
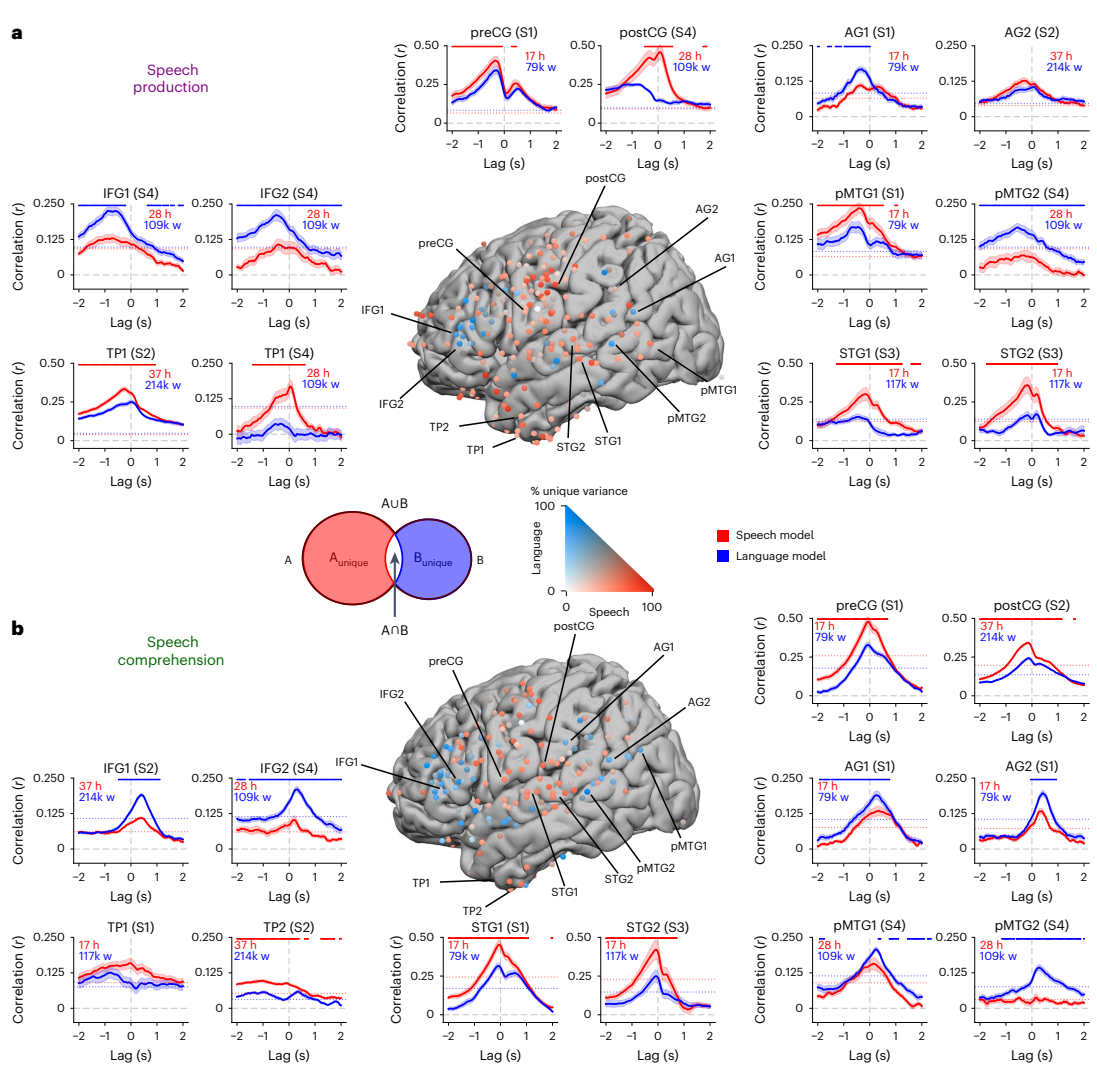
Fig. 3 | Mixed selectivity for speech and language embeddings during speech production and comprehension. a, Variance partitioning was used to identify the proportion of variance uniquely explained by either speech or language embeddings relative to the variance explained by the joint encoding model during speech production. Surrounding plots display encoding performance during speech production for selected individual electrodes across different brain areas and patients. Models were estimated separately for each lag (relative to word onset at 0 s) and evaluated by computing the correlation between predicted and actual neural activity. Data are presented as mean ± s.e. across the 10 folds. The dotted horizontal line indicates the statistical threshold (q < 0.01, two-sided, FDR corrected). During production, the speech encoding model (red) achieved correlations of up to 0.5 when predicting neural responses to each word over hours of recordings in the STG, preCG and postCG. The language encoding model yielded significant predictions (correlations up to 0.25) and outperformed the speech model in IFG and AG indicated by blue dots (q < 0.01, two-sided, FDR corrected). The variance partitioning approach revealed a mixed selectivity for speech and language embeddings during speech production. Language embeddings (blue) better explain IFG, while speech embeddings (red) better explain STG and SM. b, During comprehension, we observed a similar pattern of encoding performance. Language embeddings better explain IFG and AG, while speech embeddings better explain STG and SM indicated by red dots (q < 0.01, two-sided, FDR corrected). The variance partitioning analysis also revealed mixed selectivity for speech (red) and language (blue) embeddings during comprehension. Matching the flow of information during conversations, encoding models accurately predicted neural activity ~500 ms before word onset during speech production and 300 ms after word onset during speech comprehension. Data are presented as mean ± s.e. across the 10 folds. Credit: A Goldstein et al.
Cortical selectivity and integration: figure 3 focuses on timing. During production, the alignment with language embeddings rises before articulation, consistent with planning and lexical selection preceding motor execution. During comprehension, alignment with speech embeddings rises after word onset, reflecting the transformation from acoustics toward word-level context. The analysis across -2000 ms to +2000 ms provides a clear look at these role reversals around the same event boundary.
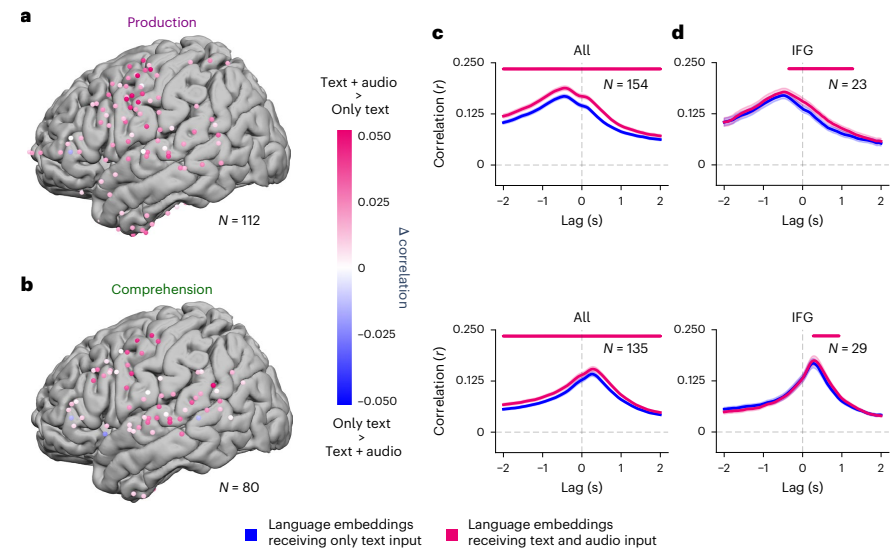
Fig. 4 | Enhanced encoding for language embeddings fused with auditory speech features. Comparing electrode-wise encoding performance for language embeddings receiving only text input (that is, conversation transcripts) and language embeddings receiving audio and text inputs (that is, speech recordings and conversation transcripts). Language embeddings fused with auditory features outperform text-only language embeddings in predicting neural activity across multiple electrodes. a, During speech production, language embeddings fused with auditory features (pink) significantly improved encoding performance in SM electrodes (q < 0.01, FDR corrected). b, During speech comprehension, language embeddings fused with auditory features (pink) significantly improved encoding performance in STG and SM electrodes (q < 0.01, FDR corrected). c, The advantage of the language embedding fused with auditory features (pink) persists across multiple time points at all significant electrodes. Data are presented as mean ± s.e.m. across the electrodes. d, Even though the IFG is associated with linguistic processing, it can be seen that across multiple lags, the audio-fused language embeddings (pink) yield higher encoding performance during both production and comprehension. Pink markers indicate lags with a significant difference (q < 0.01, FDR corrected) between text-only and audio-fused language embeddings. Data are presented as mean ± s.e. across electrodes. Credit: A Goldstein et al.
Audio-text fusion in language areas: figure 4 benchmarks against symbolic baselines. While symbols like phonemes and parts of speech are informative, the distributed Whisper embeddings explain more variance in the neural signal across many electrodes and lags. The likely reason is that continuous vectors mix information across levels and context, capturing the rich dependencies that symbolic inventories struggle to represent in natural conversation.
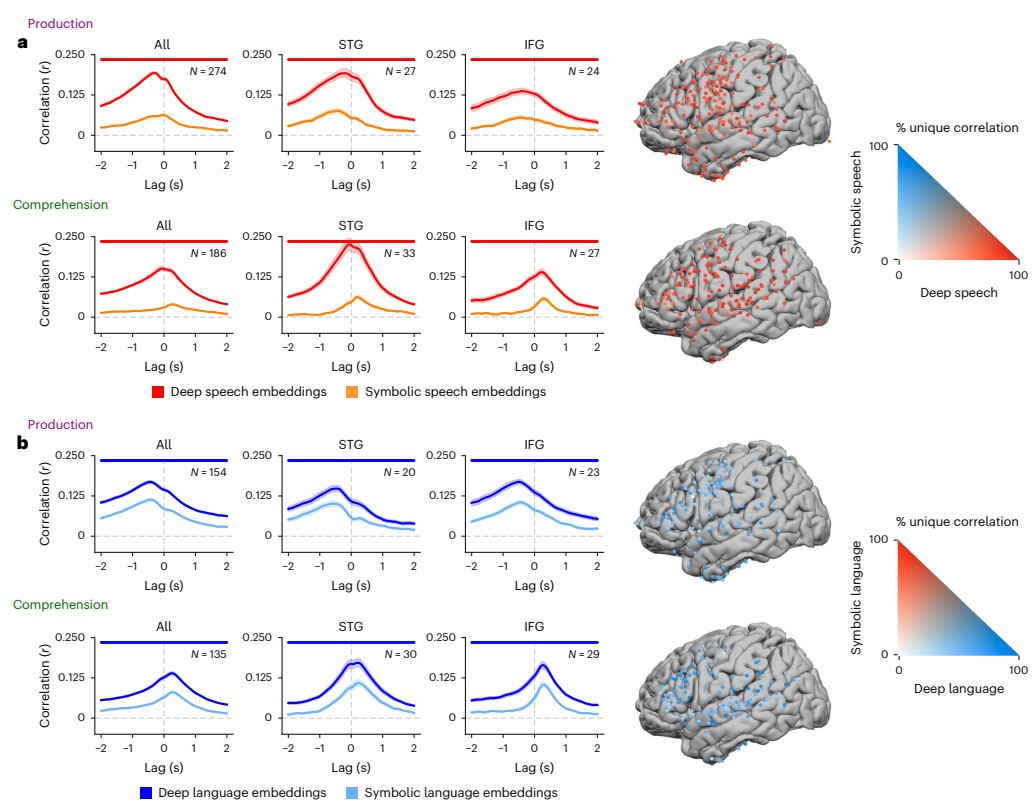
Fig. 5 | Comparing speech and language embeddings to symbolic features. a, We used a variance partitioning analysis to compare encoding models on the basis of speech embeddings (red; extracted from Whisper’s encoder) and symbolic speech features (orange; phonemes, manner of articulation, place of articulation, speech or non-speech). Data are presented as mean ± s.e.m. across electrodes. Red dots indicate lags with a significant difference (q < 0.01, FDR corrected) between deep speech embeddings and symbolic speech features. Encoding performance for deep speech embeddings is consistently higher than encoding performance for symbolic speech features across all significant electrodes, specifically in IFG and STG. b, We used a variance partitioning approach to compare encoding models on the basis of deep language embeddings (dark blue; extracted from Whisper’s decoder) and symbolic language features (light blue; part of speech, dependency, prefix, suffix, stop word). Data are presented as mean ± s.e.m. across electrodes. Blue dots indicate lags with a significant difference (q < 0.01, FDR corrected) between deep speech embeddings and symbolic speech features. Encoding performance for deep language embeddings is consistently higher than encoding performance for symbolic language features across all significant electrodes, specifically in IFG and STG Credit: A Goldstein et al.
Deep embeddings vs. symbolic features (Figure 5). Encoding models built on deep speech and language embeddings outperform models built from binarized symbolic features (phonemes, place/manner of articulation; parts of speech, dependencies, affixes, stop words). Variance unique to symbolic features is small once deep embeddings are included, suggesting that distributed, learned representations capture the lion's share of neuro-relevant variance in naturalistic settings.
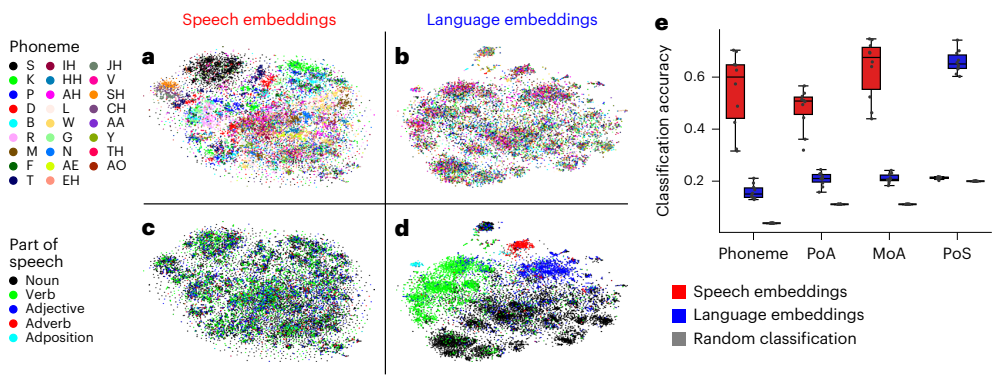
Fig. 6 | Representations of phonetic and lexical information in Whisper. a–d, Speech embeddings and language embeddings were visualized in a twodimensional space using t-SNE. Each data point corresponds to the embedding for either an audio segment (speech embeddings from the encoder network) or a word token (language embeddings from the decoder network) for a unique word (averaged across all instances of a given word). Clustering according to phonetic categories is visible in speech embeddings (a) but far less prominent in language embeddings (b). Clustering according to lexical information (part of speech) is visible in language embeddings (d) but not in speech embeddings (c). e, Classification of phonetic and lexical categories based on speech and language embeddings. We observed robust classification for phonetic information based on speech embeddings. We also observed robust classification for parts of speech based on language embeddings. The classification was performed using logistic regression, and the performance was measured on held-out data using a 10-fold cross-validation procedure.
Emergent linguistic structure (Figure 6). Despite not relying on explicit symbols, the embedding spaces exhibit emergent clustering: speech embeddings organize by phonetic categories, and language embeddings organize by parts of speech. Simple classifiers reach around 54 percent phoneme accuracy from speech embeddings (chance 4 percent) and about 67 percent PoS accuracy from language embeddings (chance 20 percent), indicating that classical linguistic descriptors are encoded implicitly in the distributed space.
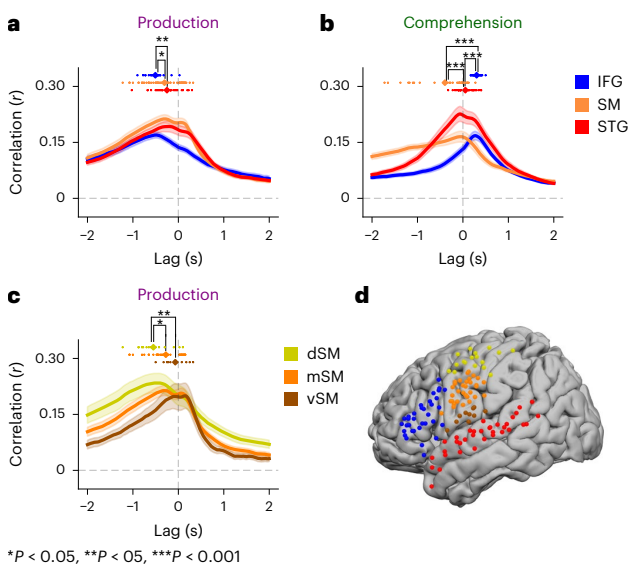
Fig. 7 | Temporal dynamics of speech production and speech comprehension across different brain areas. On the basis of tuning preferences for each ROI, we assessed temporal dynamics using the language model for IFG and the speech model for STG and SM. Coloured dots show the lag of the encoding peak for each electrode per ROI. Data are presented as mean ± s.e. across electrodes. To determine significance, we performed independent-sample t-tests between encoding peaks; P values are one-sided. a, During speech production, encoding for language embeddings in IFG peaked significantly before speech embeddings in SM and STG. b, The reverse pattern was observed during speech comprehension: encoding performance for language embeddings encoding in IFG peaked significantly after speech encoding in SM and STG. c, For speech production, we observed a temporal pattern of encoding peaks shifting towards word onset within SM, proceeding from dorsal (dSM) to the middle (mSM) to ventral (vSM). d, Map showing the distribution of electrodes per ROI.
Information flow (Figure 7). By scanning lags around word onset, the authors trace flow consistent with cortical dynamics: during production, language-related encoding in IFG peaks around 500 ms before articulation, with speech-related encoding in somatomotor areas peaking nearer to onset. During comprehension, the sequence reverses, with speech features leading in STG followed by language features in IFG. This mirrors the acoustic-to-speech-to-language cascade in the model, and the language-to-speech cascade during planning and articulation.
Methodological details worth noting
Two design choices strengthen the study.
First, the authors evaluate on long stretches of held-out conversation. This helps establish that the models generalize beyond specific sentences and that correlations are not driven by overfitting idiosyncratic episodes.
Second, the analysis uses linear encoders. That keeps the focus on representational alignment in the embedding space rather than the capacity of a complex model to fit neural data. If a simple linear map works, the structure must already be present in the embeddings.
There are also constraints. The electrode coverage is limited to left hemisphere grids in four patients, which means spatial inferences are restricted and may miss right-hemisphere contributions or subcortical dynamics.
Ecological recordings introduce noise from overlapping speakers and environmental sounds. And correlations do not imply causation. The authors’ conclusions are carefully framed as alignment between representational spaces, not as claims about the neural implementation of Whisper’s architecture.
Limitations and scope
The study focuses on four patients with left-hemisphere coverage; right-hemisphere contributions and inter-individual variability warrant broader sampling. Linear mappings may understate possible nonlinear correspondences between embeddings and neural codes, potentially leaving predictive performance on the table. Finally, while the results generalize across hours of held-out speech, the ecological context is confined to the hospital setting. These are natural constraints for current ECoG work and motivate future datasets and modeling approaches.
Conclusion
As language models integrate audio and text at scale, they offer a testbed for unifying theories of speech and language processing. This paper shows that a single, multimodal embedding space can explain a wide slice of cortical activity across both speaking and listening in realistic settings. That helps bridge three gaps: between lab and real life, between acoustics and language, and between engineering models and cognitive theories.
Looking ahead, these embedding-based encoders could become a standard tool for mapping the spatiotemporal cascade of language in the brain. They can also expose where models fail, for example if alignment drops in discourse-level areas or for pragmatic nuances, pointing to directions for model improvement and targeted experiments.
Definitions
- ECoG (Electrocorticography): A procedure that uses electrodes placed directly on the exposed surface of the brain to record electrical activity. In this study, it was used to capture continuous brain activity during natural conversations.
- Unified Embedding Space: A shared, continuous mathematical space where different types of information, such as acoustics, speech, and language, are represented as vectors. This allows for a unified model to bridge these multiple levels of processing.
- Whisper: The speech-to-text AI model used in the study to generate embeddings from audio and transcripts.
- Acoustic Embeddings: Low-level vector representations that summarize local audio cues from the raw sound of speech.
- Speech Embeddings: Mid-level vector representations that capture more abstract features of speech that are useful for word recognition.
- Language Embeddings: High-level vector representations that place words within their broader sentence and conversational context, capturing semantic meaning.
- Linear Encoding Models: A type of model used to predict neural activity by finding a direct, linear mapping from the embeddings to the brain signals. Its simplicity helps test if the structure of the embeddings already mirrors the brain's structure.
- Cortical Hierarchy: The organization of the brain's cortex into different regions that process information at increasing levels of complexity, from basic sensory input to higher-order cognitive functions.
- Symbolic Baselines: Traditional, discrete features used in language studies, such as phonemes (sound units) or parts of speech (e.g., noun, verb). These are contrasted with the continuous, distributed representations of embeddings.


From Acoustics to Words: How a Unified Embedding Space Mirrors the Brain in Natural Conversation
A unified acoustic-to-speech-to-language embedding space captures the neural basis of natural language processing in everyday conversations