Researchers Pasan Bhanu Guruge and Y.H.P.P. Priyadarshana propose a proactive autoscaling framework for Kubernetes that combines Facebook Prophet and Long Short-Term Memory (LSTM) forecasting to predict HTTP request rates and plan replica counts using a Monitor-Analyze-Plan-Execute (MAPE) loop.
The study targets a key limitation of reactive HorizontalPodAutoscaler (HPA) policies, which can lag on sudden spikes because they scale from trailing CPU or memory usage rather than anticipated demand.
The hybrid approach assigns seasonality and trend to Prophet, then feeds residuals to LSTM to capture non-linear structure. Predictions over short horizons (minutes) drive planned replica counts, executed via Kubernetes APIs.
The authors evaluate on two canonical web traffic datasets: NASA Kennedy Space Center HTTP logs (July-August 1995) and the 1998 FIFA World Cup access logs, with accuracy summarized via MSE, RMSE, MAE, R^2, and latency (TPT).
They report that the hybrid model improves accuracy versus single-model baselines (ARIMA, LSTM, Bi-LSTM) and offers a blueprint for Kubernetes integration using Prometheus and KEDA for metric collection and trigger delivery ((Prometheus, n.d.); (KEDA, 2024)).
Key Takeaways
- Hybrid Prophet+LSTM forecasting improves prediction error on NASA and WorldCup98 web logs relative to ARIMA, LSTM, and Bi-LSTM baselines.
- MAPE control loop turns forecasts into planned replica counts with an adaptation step inspired by prior proactive autoscaling work ((Dang-Quang & Yoo, 2021)).
- HPA's reactive ratio-based algorithm can miss abrupt load shocks; pairing Prometheus metrics with KEDA enables request-rate driven triggers ((Kubernetes Documentation, 2024); (KEDA, 2024)).
- WorldCup98 logs contain 1.35B requests in 88 days; NASA 1995 logs include outages and clear daily/weekly seasonality ((Arlitt & Jin, 1998); (NASA-HTTP, 1995)).
- Trade-off: hybrid models often yield higher accuracy at the cost of added latency and compute; suitability depends on application SLOs.
Overview
The paper frames autoscaling as a forecasting-and-control problem: predict near-future request rate and derive target replica counts to satisfy demand.
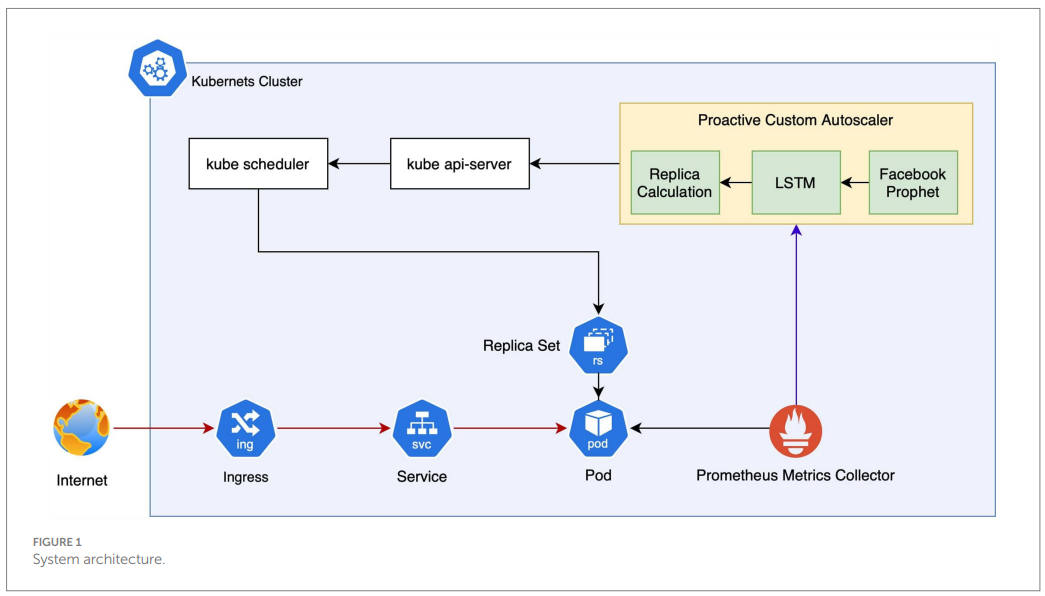
Prophet models multi-seasonal structure and changepoints (Taylor & Letham, 2018), while LSTM estimates residual dynamics the statistical model does not capture. Figure 1 in the paper depicts the system architecture: Prometheus scrapes request-rate metrics; a hybrid forecaster outputs a short-horizon forecast; a planner applies a ratio to compute desired replicas; and the executor scales deployments via Kubernetes API.
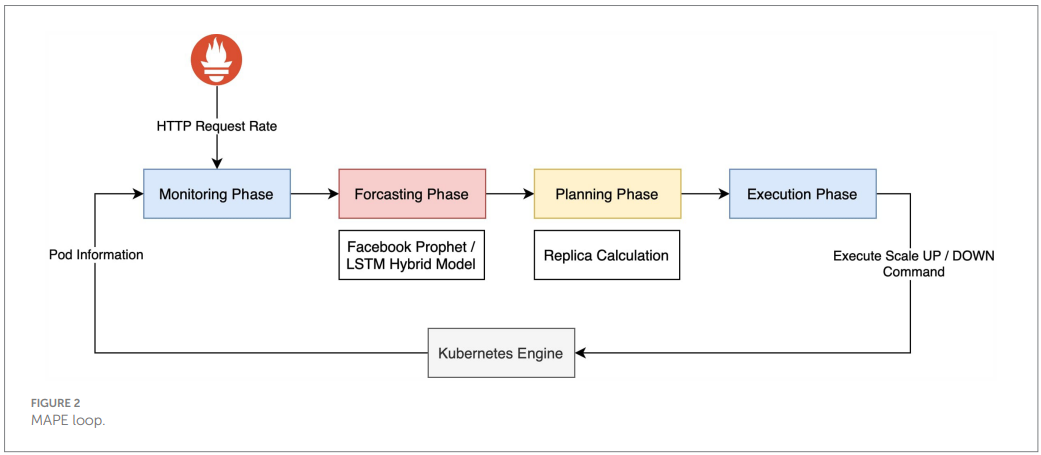
MAPE details are illustrated in Figure 2: Monitoring (Prometheus), Forecasting (Prophet+LSTM), Planning (adaptation manager that computes desired replicas from request-rate capacity per pod), Execution (scale up/down through the API). The request-rate metric is emphasized as more directly aligned with demand than CPU or memory usage, which is consistent with HPA's support for custom and external metrics when used with event-driven systems like KEDA.
Why It Matters
Reactive autoscaling is robust and simple, but it reacts after the fact. For services with bursty traffic, cold starts and ramp-up can degrade latency and availability. Proactive autoscaling closes the gap by forecasting demand and planning ahead, potentially reducing overprovisioning while maintaining SLOs.
The hybrid design is pragmatic: Prophet efficiently captures stable seasonal baselines; LSTM adds flexibility for residuals. This division of labor reduces the risk of mis-specifying a single model while retaining interpretability of trends and seasonality.
Operationally, the architecture maps cleanly onto common Kubernetes stacks: Prometheus for metrics, KEDA for event-driven triggers and scale-to-zero semantics, and HPA for policy execution. It also aligns with prior proactive designs that embed forecasting in a MAPE loop for cloud resource control ((Dang-Quang & Yoo, 2021)). Teams considering adoption should prototype with a small forecasting horizon and enforce stabilization windows to avoid oscillations.
Discussion of Results
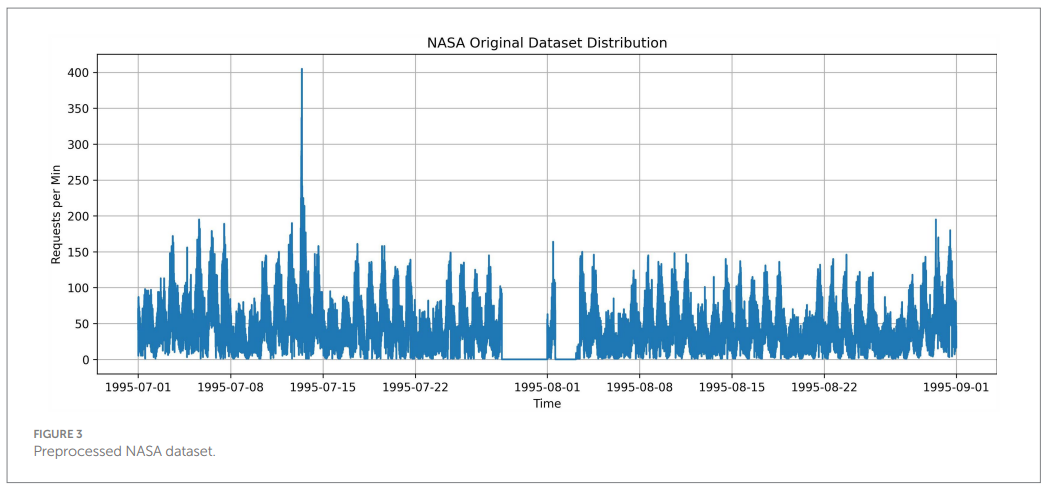
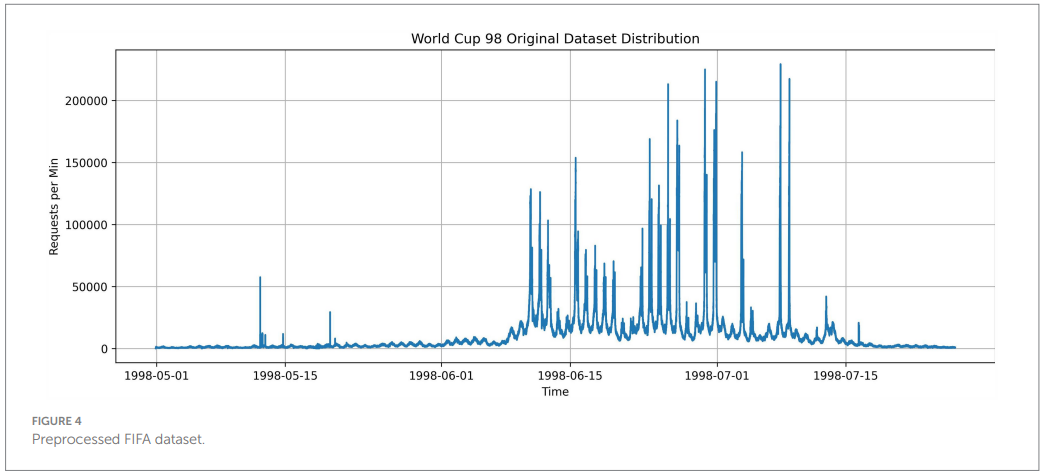
Datasets and preprocessing (Figures 3 and 4). The NASA HTTP logs (July-August 1995) and WorldCup98 logs (April-July 1998) were aggregated to per-minute request rates. The NASA set exhibits clearer seasonality and includes a multi-day "no data" gap late July to early August. The WorldCup98 set contains pronounced spikes near key matches and totals 1.35B requests ((NASA-HTTP, 1995); (Arlitt & Jin, 1998)).
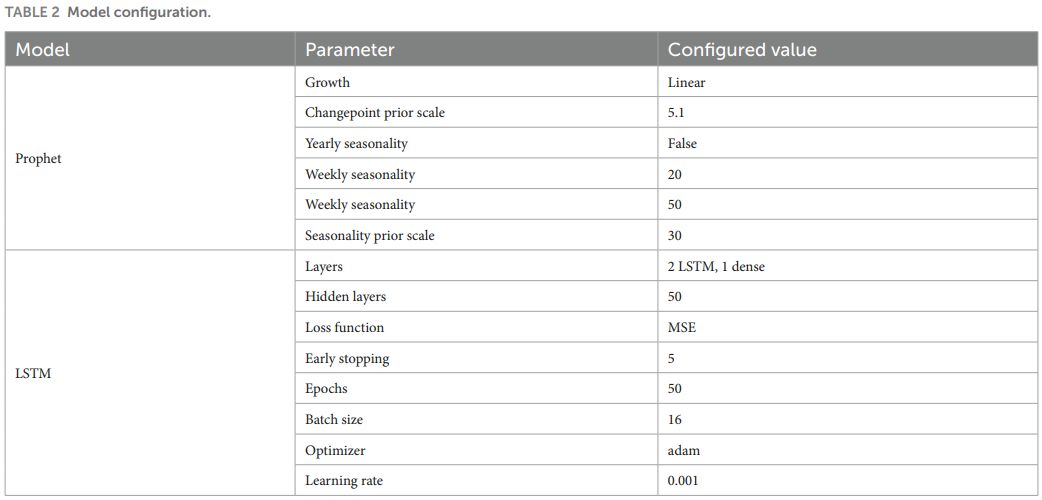

Model configuration (Tables 2 and 3). The study reports concrete Prophet and LSTM hyperparameters and grid ranges (e.g., seasonality scales, hidden sizes, optimizers) and evaluates with MSE, RMSE, MAE, R^2, and total prediction time TPT (Equations 10-14). While Prophet-LSTM has higher latency than fast single-step Bi-LSTM or LSTM, accuracy gains are consistent on both datasets.
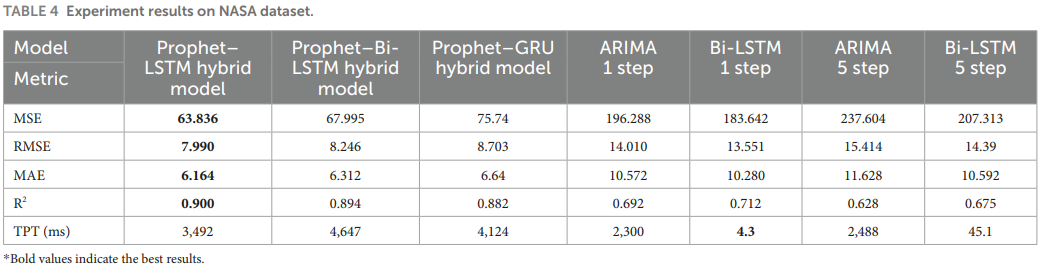
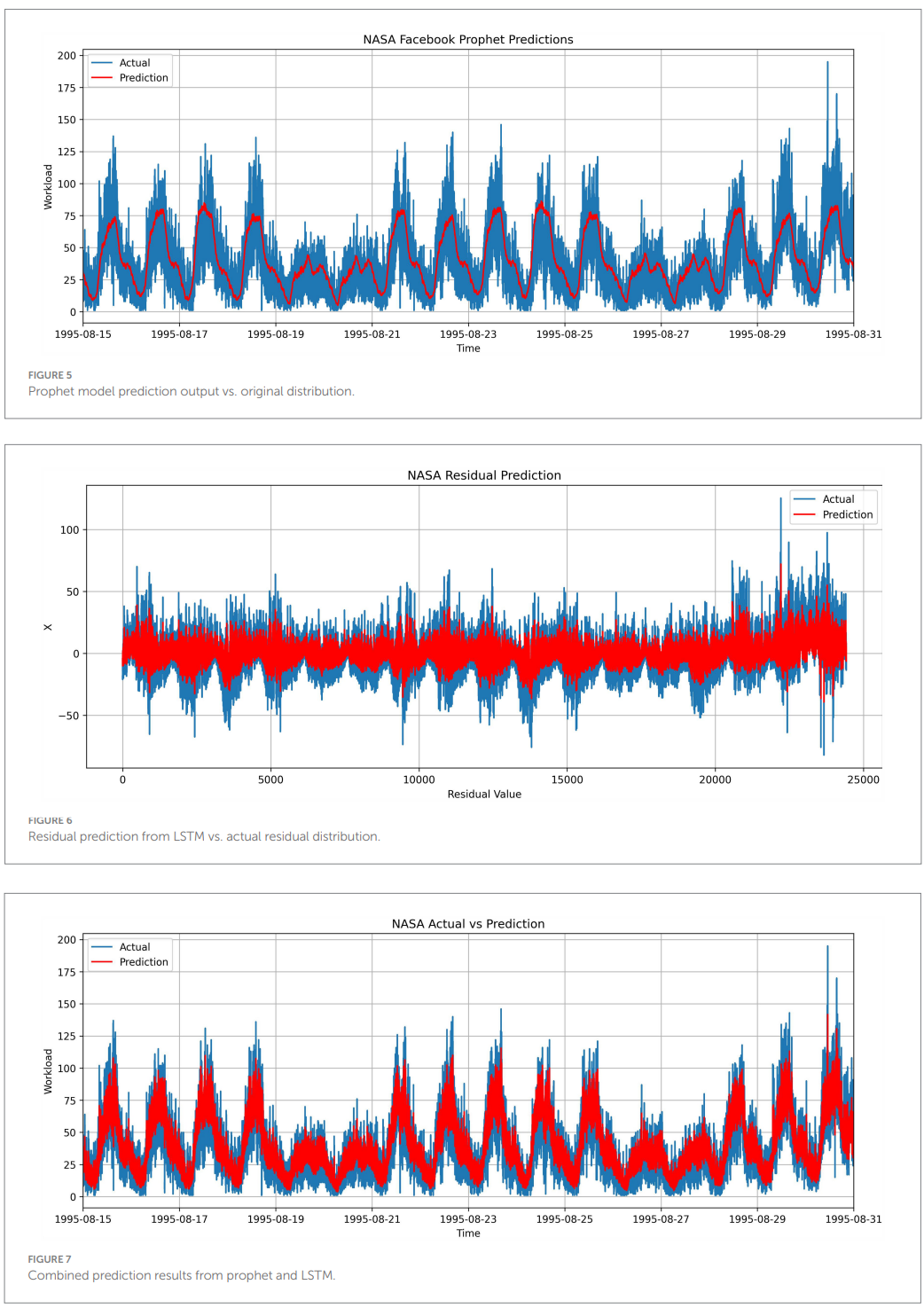
NASA results (Table 4; Figures 5-7). The hybrid model attains the lowest error metrics and highest R^2 among tested models on NASA, consistent with the advantage of explicit seasonality capture. Visuals show Prophet capturing trend/seasonality, LSTM modeling residuals, and the combined output closely tracking observed traffic.
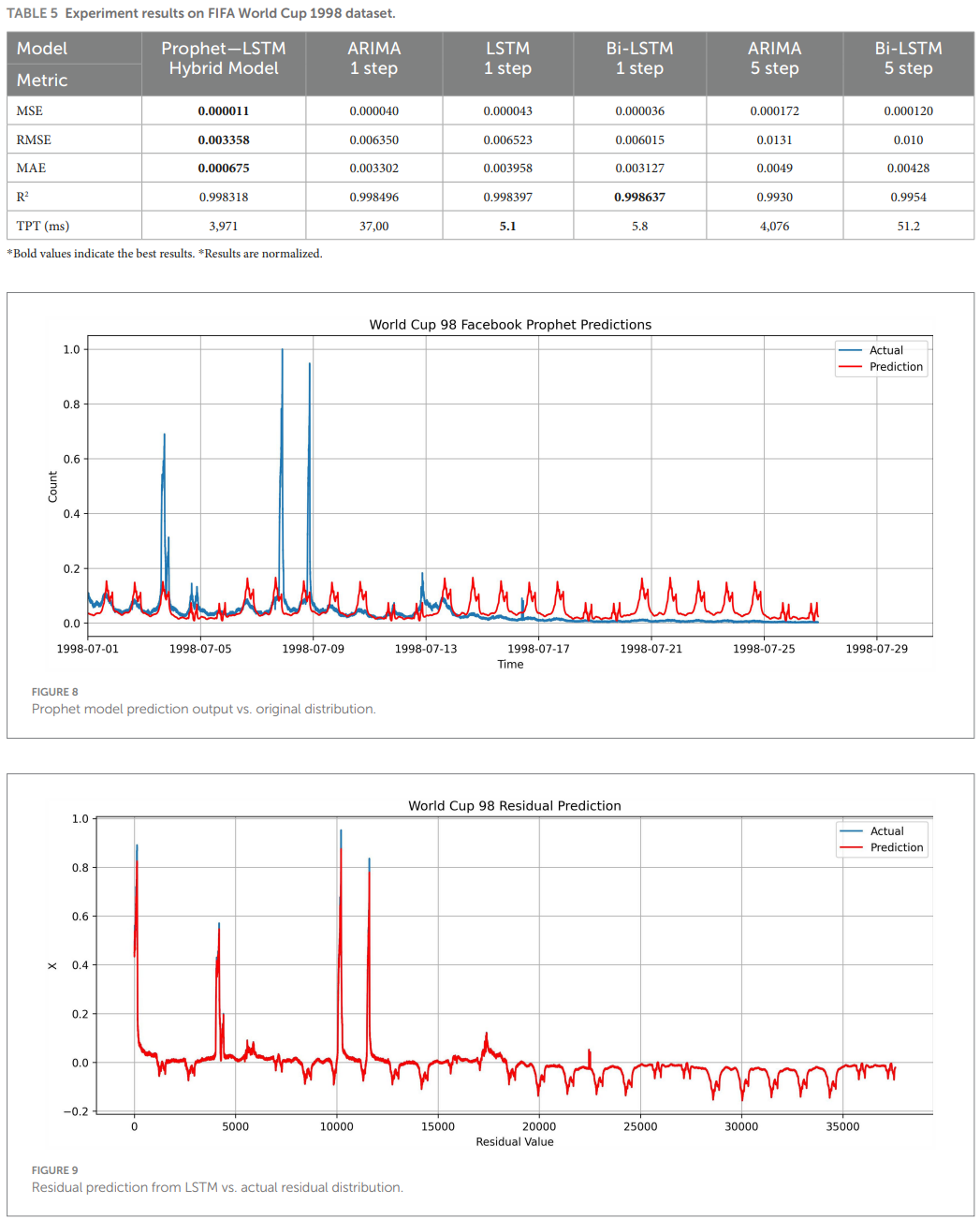
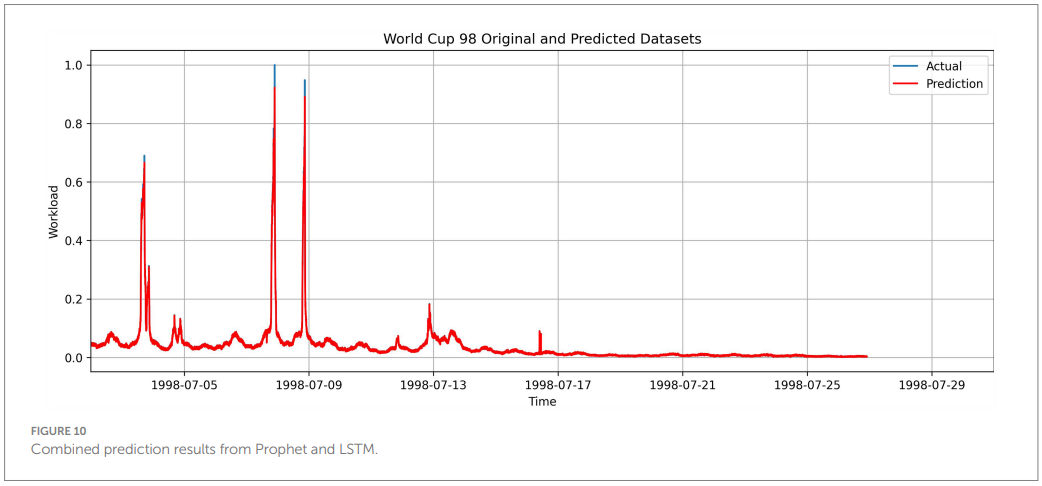
WorldCup98 results (Table 5; Figures 8-10). The hybrid also leads on MSE/RMSE/MAE, though R^2 trails a strong Bi-LSTM in one comparison due to complex, spiky patterns. The authors note that seasonality capture can introduce variance when irregularities dominate, which the residual model partially corrects.
Elasticity and SLO impact.
Improvements in MSE, RMSE, and MAE translate to tighter tracking of demand, which typically reduces both under-provisioning (risking SLO violations and tail latency spikes) and over-provisioning (wasted cost). In Kubernetes, the HPA's decision cadence and guardrails matter: stabilization windows prevent rapid oscillations, scaling policies cap replica changes per unit time, and tolerance avoids jitter around the target. Combining forecast-driven targets with these controls can yield smoother, more anticipatory scaling than CPU- or memory-only triggers.
Dataset realism, changepoints, and seasonality.
The contrast between the NASA and WorldCup98 outcomes is instructive. NASA's clearer daily-weekly seasonality suits Prophet's trend-seasonality formulation and changepoint handling, helping the hybrid achieve higher R^2. WorldCup98's match-driven spikes stress any seasonal model; the partial R^2 dip observed is consistent with Prophet's tendency to underfit extreme, irregular bursts when the changepoint prior is conservative. In hybrid form, LSTM residuals recover some of this variance, but not all, which aligns with the authors' narrative ((Taylor & Letham, 2018)).
Control loop timing and forecast horizon.
Practical deployments should align the forecast horizon, model latency, and control cadence. HPA typically reconciles every tens of seconds by default; forecast horizons in the order of one to a few minutes can provide actionable lead time without accumulating error. The study reports higher TPT for hybrids than single models, which is an expected trade-off. In production, you can amortize compute by batching predictions, running the forecaster on a sidecar or control-plane service, and using KEDA to translate forecasted metrics to scale actions.
Robustness and guardrails.
Forecast error and concept drift are inevitable. Two pragmatic safeguards are (1) fallback to reactive signals when forecast confidence drops or error exceeds a threshold, and (2) safety buffers on desired replicas to absorb misprediction. Rolling-origin backtesting and walk-forward validation help quantify error under changing regimes; drift detection plus periodic hyperparameter refresh for Prophet and LSTM can sustain performance over time ((Prometheus, n.d.); (Taylor & Letham, 2018)).
Context from prior proactive autoscaling.
Prior work using Bi-LSTM within a MAPE loop also found proactive scaling preferable to reactive in many regimes and highlighted cooling strategies to avoid flapping. Notably, Bi-LSTM can outperform ARIMA and vanilla LSTM on highly non-stationary traces - which resonates with the observed R^2 edge for Bi-LSTM on the spiky WorldCup98 slice here. The present hybrid narrows error further on average by capturing seasonality explicitly, suggesting that combining statistical and neural views is advantageous when seasonality is strong.
Practical guidance for adoption.
Start with a short forecast horizon aligned to your HPA sync period and pod cold-start time. Use KEDA to expose a forecasted requests-per-pod target, then apply autoscaling/v2 policies with stabilization and step limits. Prefer per-service capacity models (requests-per-pod) over CPU-only triggers for web workloads. Add a small safety margin to desired replicas and set a confidence threshold to fall back to reactive metrics. Finally, monitor over- and under-provisioning minutes, p95-p99 latency, and scale action counts to verify that proactive control improves both performance and cost.
Conclusion
This study argues that pairing a statistical forecaster (Prophet) with a neural residual model (LSTM) improves proactive autoscaling decisions in Kubernetes compared to single-model or reactive approaches. The approach is compatible with existing observability stacks and autoscaling APIs, and it performs well on two established workload traces. Limitations include added latency and compute overhead of a two-stage model and sensitivity of seasonality capture under heavy irregularities. For teams facing predictable diurnal demand with occasional bursts, the hybrid MAPE loop is a credible, testable upgrade path.
Definitions
- Kubernetes: An open-source platform for automating the deployment, scaling, and management of containerized applications.
- Horizontal Pod Autoscaler (HPA): A Kubernetes feature that automatically scales the number of pods in a replication controller, deployment, replica set, or stateful set based on observed CPU utilization or other select metrics.
- MAPE loop (Monitor-Analyze-Plan-Execute): A control loop used in autonomic computing to manage systems. It continuously monitors the system, analyzes the data, plans a course of action, and executes that plan.
- Facebook Prophet: An open-source forecasting tool from Facebook that is designed for forecasting time series data with strong seasonal effects and historical trends.
- Long Short-Term Memory (LSTM): A type of recurrent neural network (RNN) architecture that is well-suited for learning from and predicting time series data.
- KEDA (Kubernetes-based Event-driven Autoscaling): An application that provides event-driven autoscaling for Kubernetes workloads. It can scale applications based on the number of messages in a queue or other event sources.
- ARIMA (Autoregressive Integrated Moving Average): A statistical model used for analyzing and forecasting time series data.
- Bi-LSTM (Bidirectional Long Short-Term Memory): A variant of the LSTM network that processes sequence data in both forward and backward directions, allowing it to capture context from both past and future elements.


Forecasting-Driven Kubernetes Autoscaling With Prophet + LSTM
Time series forecasting-based Kubernetes autoscaling using Facebook Prophet and Long Short-Term Memory