Long-context reasoning is still a weak spot for many large language models, even as context windows grow. The ACL 2025 paper EpMAN: Episodic Memory AttentioN for Generalizing to Longer Contexts by from researchers at IBM proposes a simple but effective refinement:
Compute an episodic attention over chunked context, then use it to reweight decoder self-attention to the stored KV cache.
The authors report stronger, more robust performance from 16k up to 256k tokens on recall and single-hop QA benchmarks compared with standard decoders and retrieval-augmented generation.
The work appeared in the Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025), pages 11696-11708 (DOI: 10.18653/v1/2025.acl-long.574). The paper’s central idea is to pair fast self-attention with a slower, more deliberative episodic memory signal that emphasizes semantically relevant chunks, aligning with a dual-process view of inference. In practice, this means learning to attend broadly, then focusing with a lightweight, chunk-level gate.
Two practical observations motivate the method: (i) models often struggle with content placed in the middle of long contexts ((Liu et al., 2023)), and (ii) strong needle-in-a-haystack scores can overstate true long-context abilities ((Hsieh et al., 2024)). EpMAN addresses both by letting a separate episodic signal guide what the decoder actually reads from the KV cache.
In this review, we outline EpMAN’s mechanism, highlight empirical results across 16k–256k tokens, and discuss when its denoising and broader-attention variants matter, with practical notes for researchers and engineers shipping long-context QA.
Key Takeaways
- EpMAN adds an episodic memory module that ranks context chunks by relevance to the query and reweights decoder self-attention to the stored KV cache.
- A noisy training scheme randomizes weights among the top-K retrieved chunks and permutes their order, improving robustness to retrieval noise and out-of-distribution contexts.
- BroadAttn expands attention at inference to include immediate neighbors of top-K chunks, helping when evidence is split across adjacent entries.
- Results: near-perfect recall on Needle-in-the-Haystack across Paul Graham essays and PG19; best overall performance on Factrecall-en with LV-Eval; competitive or better results on MultifieldQA and Loogle SD at 16k–256k tokens.
- Trade-offs: storing full KV cache per chunk costs memory and increases CPU–GPU transfer time; performance can depend on retriever quality and top-K choices.
- Inference time is comparable to RAG in NarrowAttn settings; BroadAttn adds modest overhead.
- The approach complements, rather than replaces, retrieval. Order-preserving chunk selection and chunk-level weighting align with recent evidence that carefully structured RAG still excels in long-context regimes ((Yu et al., 2024)).
Overview
Long-context models face several well-documented issues: attention dilution as softmax mass spreads over many irrelevant tokens, recency/middle-position effects that reduce effective recall in the center of long inputs, and susceptibility to distractors. Many prior solutions reduce complexity or extend positional representations, but performance often degrades near or beyond the training context window ((Beltagy et al., 2020); (Chen et al., 2023); (Liu et al., 2023); (Hsieh et al., 2024); (Kuratov et al., 2024)).
Retrieval-augmented generation (RAG) helps by fetching relevant snippets, but it can conflict with parametric memory, propagate retrieval mistakes, or cause the generator to ignore supplied context.
This work instead integrates retrieval signals into the attention pathway itself. EpMAN stores context in episodic entries (e.g., 256-token chunks), computes a relevance score for each chunk (using a fixed dense retriever in the main experiments), and broadcasts the chunk score to all tokens of that chunk. The episodic attention vector then multiplicatively reweights the decoder’s self-attention over the context KV cache.
Formally, if the standard attention uses softmax over dot-products, EpMAN modifies it by applying chunk-level weights to the values:
Here,
# Chunk-level reweighting (pseudocode)
# scores: [num_chunks] relevance from retriever
# a_mem: [num_tokens] broadcast chunk score to each token index
+a_mem = broadcast_chunk_scores(scores, chunk_map)
# Standard attention
attn = softmax(q @ K.T / sqrt(d)) # [T_q, T_k]
# EpMAN: reweight values token-wise using a_mem
V_weighted = V * a_mem[:, None] # [T_k, d_v]
out = attn @ V_weighted # [T_q, d_v]
Training uses synthetic corpora and questions with added distractors and hard negatives. Critically, the authors introduce a noisy training variant: top-K chunks receive randomized weights in a narrow band (e.g., 1.0 to 0.9) and are permuted to decouple positional continuity from rank. This denoising objective makes the decoder less brittle when the retriever misranks relevant evidence at test time, and it reduces reliance on a perfect top-1 chunk.
At inference, EpMAN supports two scopes. NarrowAttn uses only the top-K chunks. BroadAttn augments each top-K chunk with its immediate neighbors, a small change that helps when entities and attributes are split across adjacent chunks. The retriever in the main experiments is Dragon ((Lin et al., 2023)), chosen for its strong generalization, and results are also discussed when read/write are trained.
For evaluation context, LV-Eval provides five sequence-length levels (16k, 32k, 64k, 128k, 256k), intentionally injects confusing facts, and replaces keywords/phrases; it also proposes a keyword-recall-based metric to reduce evaluation bias (Yuan et al., 2024).
RULER highlights that vanilla needle-in-a-haystack success may not translate to more complex long-context behaviors, especially as the number of needles or task hops grows ((Hsieh et al., 2024)).
Why It Matters
As context windows extend, simply scaling standard attention or plugging in RAG is not always enough. The EpMAN approach offers a pragmatic middle path: keep the decoder and self-attention, but guide it with a second, chunk-level signal that can resist distractors and recency bias.
In challenging long-context QA scenarios where keywords are replaced and confusing facts are inserted, relevance signals often become noisy. The denoising strategy directly targets this problem by improving generalization when the top-1 chunk is not the most relevant.
The benefits are particularly visible on LV-Eval, which intentionally pits models against replaced keywords and carefully crafted confounders. The approach is also computationally sensible: the extra work is mostly in training. Inference overhead relative to RAG is limited, especially in NarrowAttn mode. This makes EpMAN attractive for production pipelines that already rely on retrieval and KV caches.
Recent analyses also suggest that long-context models can underperform diversified, order-preserving retrieval pipelines as the number of retrieved chunks grows, due to diminished focus ((Yu et al., 2024)). EpMAN’s chunk-level weighting and optional neighbor expansion bring some of these retrieval best practices directly into the attention mechanism while maintaining a single, coherent decoding pass.
Discussion & Figures
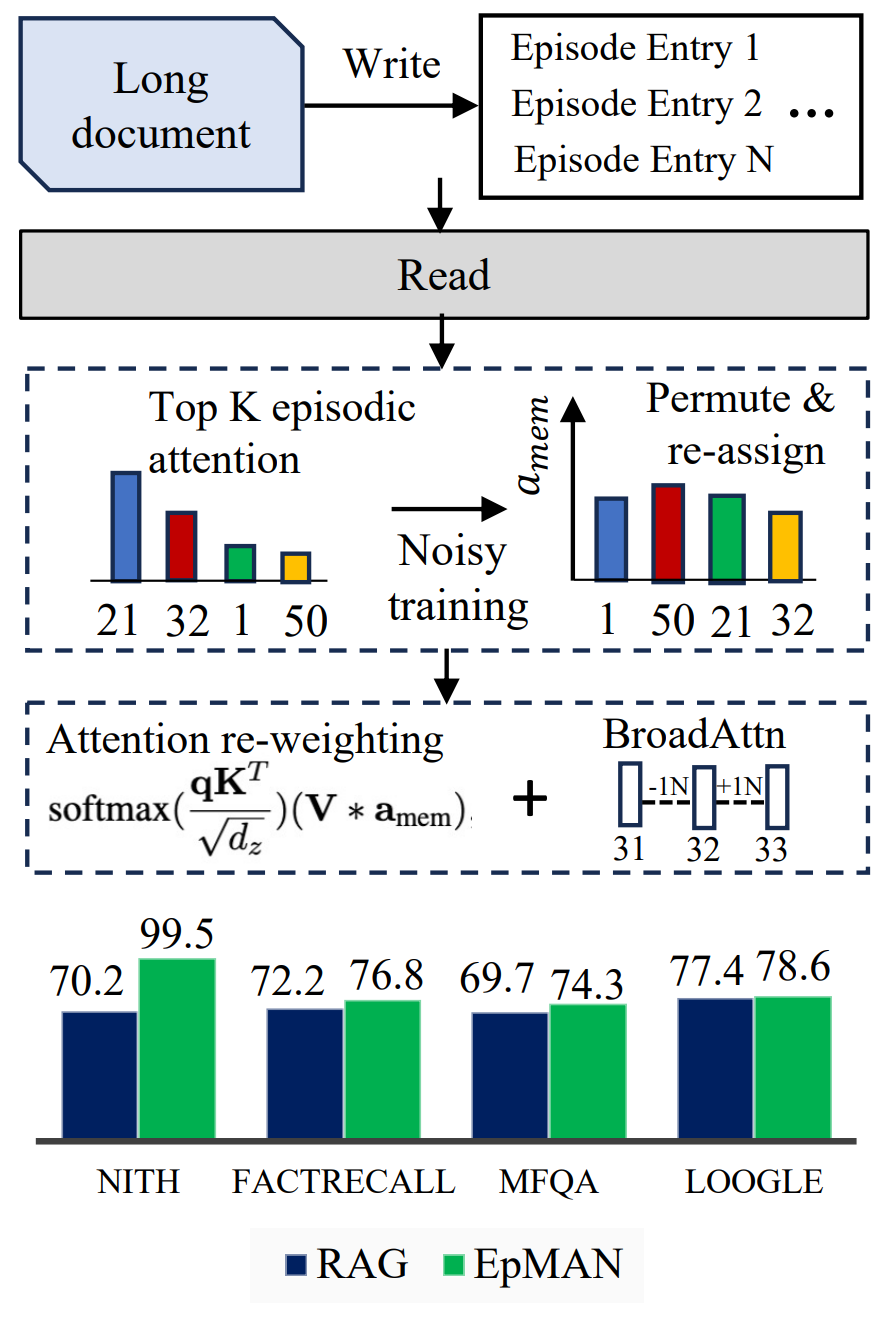
Figure 1: EpMAN uses episodic attention and noisy training for robust long context performance on recall and QA tasks (mean over 16k - 256k context lengths)
Figure 1 in the paper schematically shows the processing flow: chunk the long document into episodic entries, compute top-K episodic attention, apply a noisy weighting and permutation during training, and reweight self-attention to the KV cache. The figure also previews NarrowAttn and BroadAttn. The design reflects a clear intent: preserve the speed and locality of the decoder’s self-attention while injecting a global relevance prior from the episodic store.
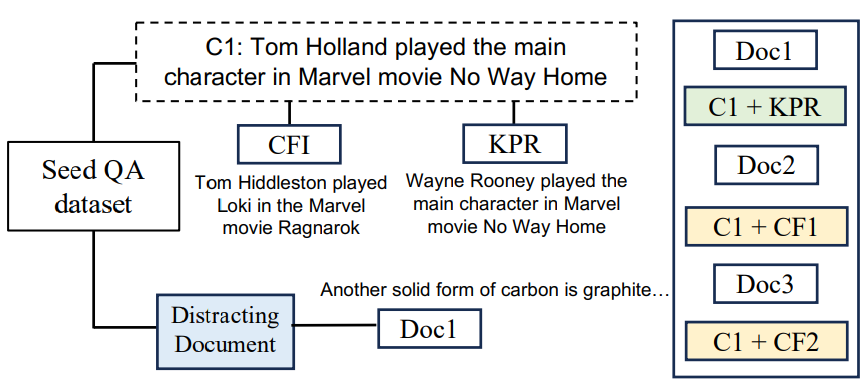
Figure 2 illustrates LV-Eval’s two stressors: Confusing Facts Insertion (CFI) and Keyword or Phrase Replacement (KPR). CFI places plausible but wrong statements near the real answer to mislead the model. KPR replaces proper nouns or key terms to reduce the usefulness of parametric memory. These manipulations make naive retrieval or naive attention less reliable and can reveal middle-position weaknesses ((Liu et al., 2023)).
Results back up the design choices:
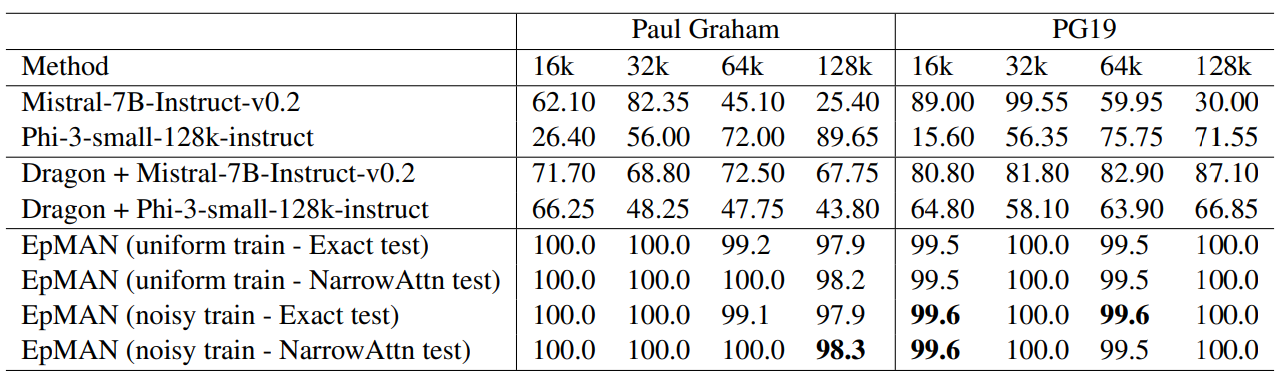
Table 1 (Needle-in-the-Haystack, sentence completion) shows EpMAN achieving near-perfect recall across Paul Graham essays and PG19 at lengths up to 128k tokens. Large-context baselines fluctuate and RAG improves over raw decoders but does not consistently close the gap. Because the task puts all information in one place, both NarrowAttn and BroadAttn behave similarly here, and noisy versus uniform training matters less.
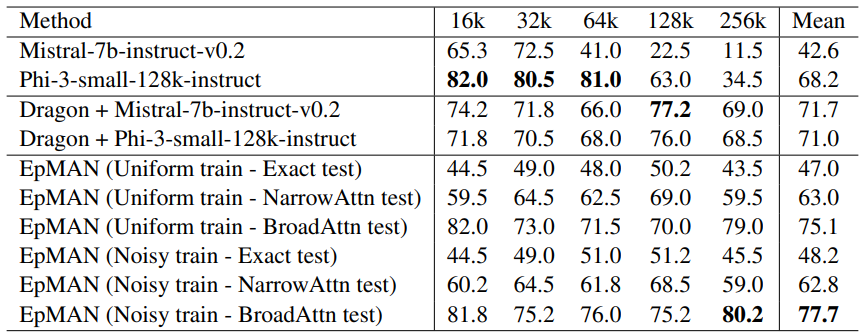
Table 2 (Factrecall-en, LV-Eval recall metric) highlights the core advantage. The noisy-trained EpMAN with BroadAttn posts the best mean score across 16k–256k, outperforming both instruction-tuned baselines and RAG variants built on the same decoders. A strict top-K focus without neighbor expansion can underperform here because the retriever may down-rank the truly relevant chunk under CFI and KPR, a mismatch the noisy training is designed to tolerate.
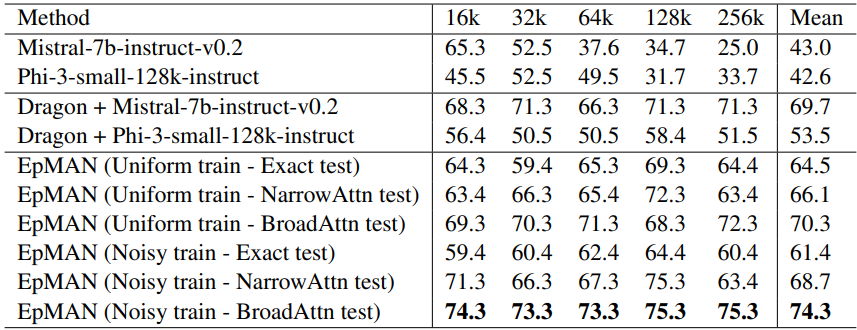
Table 3 (MultifieldQA, LLM-as-Judge) again favors EpMAN with BroadAttn under noisy training, indicating gains when questions require synthesizing fields within a single document. The LLM-as-Judge protocol mitigates surface-form mismatch issues that standard token-overlap metrics can penalize ((Zheng et al., 2023)).
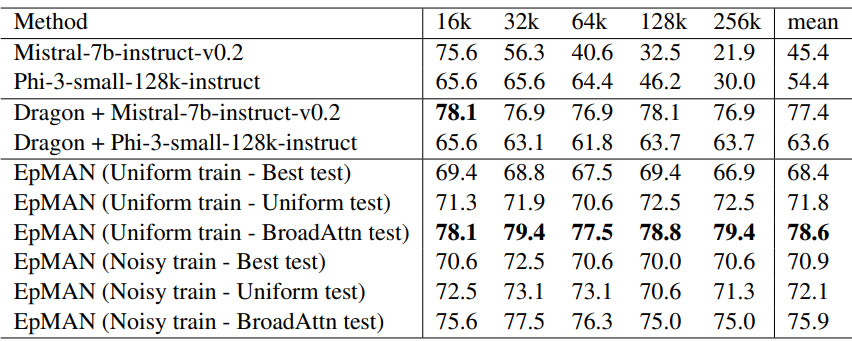
Table 4 (Loogle SD) is closer: Dragon + Mistral forms a strong baseline, but EpMAN with BroadAttn is competitive and edges ahead under the best reported configuration. The authors note that Loogle draws heavily from Wikipedia, matching both their synthetic training sources and the retriever’s domain, which may reduce the benefit of denoising relative to Factrecall-en.
The appendix explores two additional themes. First, learning the memory read and write operations, rather than fixing the retriever, further improves scores, though for fairness the main paper compares to RAG with the same fixed retriever.
Second, time measurements indicate EpMAN’s inference time is close to RAG in NarrowAttn and only modestly higher with BroadAttn, because the heavier denoising mechanics appear only during training.
Two practical tuning notes from the paper’s appendices: (i) a smaller top-K (e.g., K=2) with BroadAttn sometimes helps by reducing neighbor-induced distractors, but this is dataset-dependent; (ii) training used K=5 and random weights in [1.0, 0.9], which encourages diversity in attention without collapsing onto a single chunk.
The authors are candid about the current limitations. Storing full chunked KV caches is memory intensive and can bottleneck on CPU-GPU transfers, especially at large K or with larger models. The authors point to future work on KV cache compression and pruning for areas of optimization and also note that performance also depends on the retriever’s ability to surface useful neighbors for BroadAttn, the choice of K, and domain shift between training and deployment corpora.
Conclusion
EpMAN offers a clean, general pattern for long-context modeling: keep self-attention, but modulate it with an episodic relevance prior, then train to be robust when the prior is imperfect. The wins are clearest under adversarial long-context settings with distractors and keyword replacements, and the implementation aligns well with today’s retrieval and KV-cache infrastructures. If you work on long-context QA, recall, or tools that mix retrieval with generation, the full paper is worth a read: (Chaudhury et al., 2025).
From a systems perspective, EpMAN marries retrieval signals with the decoder’s native attention path, and it stress-tests that marriage with noise so the model learns to cope when retrieval is imperfect.
The authors note that source code will be made available; practitioners should watch for an implementation that exposes read/write training, top-K controls, and neighbor expansion to make these ideas easy to adopt.
Have you tried chunk-level reweighting in your long-context pipelines? Share results, pitfalls, or open questions, I’d love to compare notes and update this review with practitioner insights.
Definitions
Episodic Memory: A chunked store of the input context used to compute chunk-level relevance scores and to hold the per-chunk KV cache.
Episodic Attention (a_mem): The vector of chunk-level relevance weights, broadcast to all tokens in each chunk and used to reweight decoder self-attention.
NarrowAttn: Inference using only top-K chunks from episodic attention.
BroadAttn: Inference that augments each top-K chunk with its immediate neighbors, preserving original order.
Attention Dilution: Loss of focus when softmax attention distributes probability mass across many irrelevant tokens.
CFI/KPR: Confusing Facts Insertion and Keyword or Phrase Replacement, two LV-Eval stressors that confound naive context use.
Order-Preserving Retrieval: A RAG strategy that maintains the original sequence order of retrieved chunks to preserve local coherence and discourse structure ((Yu et al., 2024)).
References
(Chaudhury et al., 2025) ACL 2025. EpMAN: Episodic Memory AttentioN for Generalizing to Longer Contexts.
(Beltagy et al., 2020) Longformer: The long-document transformer.
(Chen et al., 2023) Extending context window via positional interpolation.
(Liu et al., 2023) Lost in the Middle: How language models use long contexts.
(Hsieh et al., 2024) RULER: What’s the real context size of your long-context models?
(Kuratov et al., 2024) Babilong: Reasoning-in-a-haystack for long contexts.
(Kamradt, 2023) Needle-In-A-Haystack test.
(Lin et al., 2023) Dragon: Diverse augmentation for generalizable dense retrieval.
(Das et al., 2024) Larimar: LLMs with episodic memory control.
(Wu et al., 2022) Memorizing Transformers.
(Yuan et al., 2024) LV-Eval benchmark.
(Zheng et al., 2023) LLM-as-Judge with MT-Bench and Chatbot Arena.
(Yu et al., 2024) In Defense of RAG in the Era of Long-Context Language Models.


EpMAN Reweights Attention With Episodic Memory To Tackle 256k-Token Contexts
EpMAN: Episodic Memory AttentioN for Generalizing to Longer Contexts