This article analyzes a Meta FAIR technical report introducing the Code World Model (CWM), a 32-billion-parameter decoder-only transformer trained to model program execution and agentic software engineering workflows.
Unlike conventional code LLMs trained primarily on static code corpora, CWM mid-trains on large-scale Python execution traces and agent-environment interaction trajectories inside Dockerized repositories. The authors argue that learning a “code world model” — a transition function from program state to state conditioned on executed actions — strengthens coding, debugging, and planning.
CWM integrates long-context attention (up to 131k tokens) with an alternating local-global sliding window design and proceeds through pre-training, mid-training on world-modeling data, supervised finetuning, and large-scale multi-task reinforcement learning (RL).
Reported results include 65.8% pass@1 on SWE-bench Verified with test-time scaling and 53.9% without, competitive LiveCodeBench scores, and strong math and algorithmic complexity reasoning. The release includes intermediate checkpoints and a preparedness assessment.
Key Takeaways
- CWM mid-trains on two world-modeling data streams: (1) Python execution traces that capture line-level state transitions, and (2) agentic SWE trajectories generated in Dockerized repos with tools for edit, create, bash, and submit.
- A 32B dense decoder-only transformer with alternating local-global attention supports up to 131k tokens; training spans pre-training, world-model mid-training, SFT, and multi-task RL.
- On SWE-bench Verified, CWM reports 65.8% pass@1 with test-time scaling and 53.9% without. It shows strong LiveCodeBench and math scores, and robust algorithmic complexity prediction and generation.
- Execution-trace prediction acts as a learned “neural interpreter,” enabling grounded reasoning about code behavior without running it — useful for debugging, verification, and planning.
- Agentic RL uses a simple but general toolset, long-horizon interaction (up to 128 turns), and a hybrid reward combining hidden tests with patch similarity when tests fail.
- Mid-training ablations indicate Python tracing boosts CruxEval performance, ForagerAgent improves agentic SWE likelihoods and pass rates, and GitHub PR trajectories help oracle-patch likelihoods.
- Preparedness analysis concludes open release is unlikely to increase catastrophic risks beyond the current ecosystem baseline; the model is for noncommercial research.
Overview
The core premise here is that code models should not only learn the syntax of programs but also their dynamics. CWM therefore learns from observation-action trajectories where observations are program states (e.g., locals, frames) and actions are executed statements or tool calls in a computational environment. Two major data sources drive this mid-training: Python execution traces and ForagerAgent’s agentic interactions.
Python tracing yields over 120M traced functions plus repository-level traces aligned to test runs. Each step logs the local variable state and the next executed line, represented in a compact, JSON-like, tokenized format.
The model learns to predict per-line state updates and return values. Complementing this, ForagerAgent generates 3M multi-step SWE trajectories across 10.2k images and 3.15k repositories. Tasks include mutate-fix (synthetic bug injection followed by repair) and issue-fix (real GitHub issues), emphasizing realistic tool use and long-horizon reasoning. Trajectories are near-deduplicated and include both successful and unsuccessful runs to improve robustness.
Architecturally, CWM is a 32B-parameter dense decoder-only transformer using Grouped-Query Attention, SwiGLU activations, RMSNorm, and scaled RoPE with long-context alternating attention: three local blocks interleaved with one 131k-tokens global block.
Training uses AdamW, large token batches, and careful long-context bucketization. Post-training includes SFT on a mixed distribution and a joint, asynchronous RL setup that blends agentic SWE, competitive programming, agentic coding, and math reasoning.
Why It Matters
Grounding LLM predictions in execution dynamics can stabilize coding outcomes and reduce brittle pattern-matching. Execution-trace learning forces the model to track state, not just tokens, making it more reliable when stepping through logic, propagating invariants, or assessing the impact of edits.
In agentic settings, a world model enables more sample-efficient RL: the agent starts with an internal simulator that anticipates environment feedback, then RL focuses on which actions yield rewards.
Practically, this approach moves coding models closer to what engineers do: reason about what each line will do and how to fix errors. It is especially relevant for debugging workflows and tools that operate in containers against large repos under unit tests. It also opens paths to neural debuggers that can “jump ahead,” predict required inputs to reach target states, and integrate symbolic checks or constraints.
Discussion
CWM’s reported results place it among the strongest open-weight models of its size on software engineering tasks. On SWE-bench Verified, the authors report 53.9% pass@1 without test-time scaling and 65.8% pass@1 with a best@k strategy that ranks multiple agentic candidate patches using generated tests.
The test-time scaling pipeline asks the model to propose new verification tests that both validate the fix and reproduce the original bug. Patches are filtered by existing test pass counts, then ranked by performance on the generated tests, with ties broken by majority and brevity. Majority voting alone, without new tests, still improves performance but less than best@k.
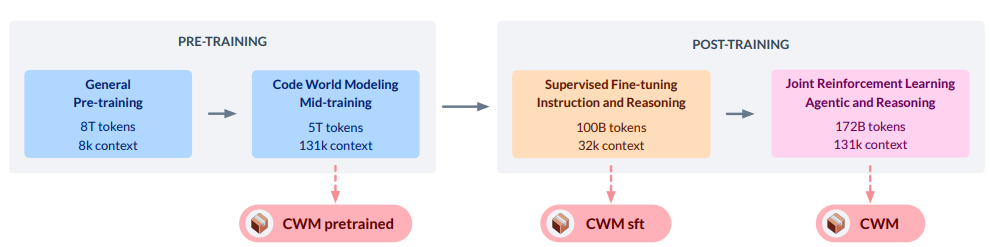
Figure 1 Overview of the CWM training stages and the model checkpoints.
Figure 1 summarizes the multi-stage recipe and public checkpoints. The key design is to inject world-modeling data in mid-training, not only in post-training.

Figure 3 formalizes the Python trace format: given the source context and a trace start marker, the model predicts a sequence of frames (JSON-formatted locals) and actions (executed lines) with custom separators. On synthetic and real trace corpora, the model achieves high exact-match rates for both observations and actions.
Agentic examples show how CWM plans, writes code, runs it, compares predicted outputs against execution, and revises.
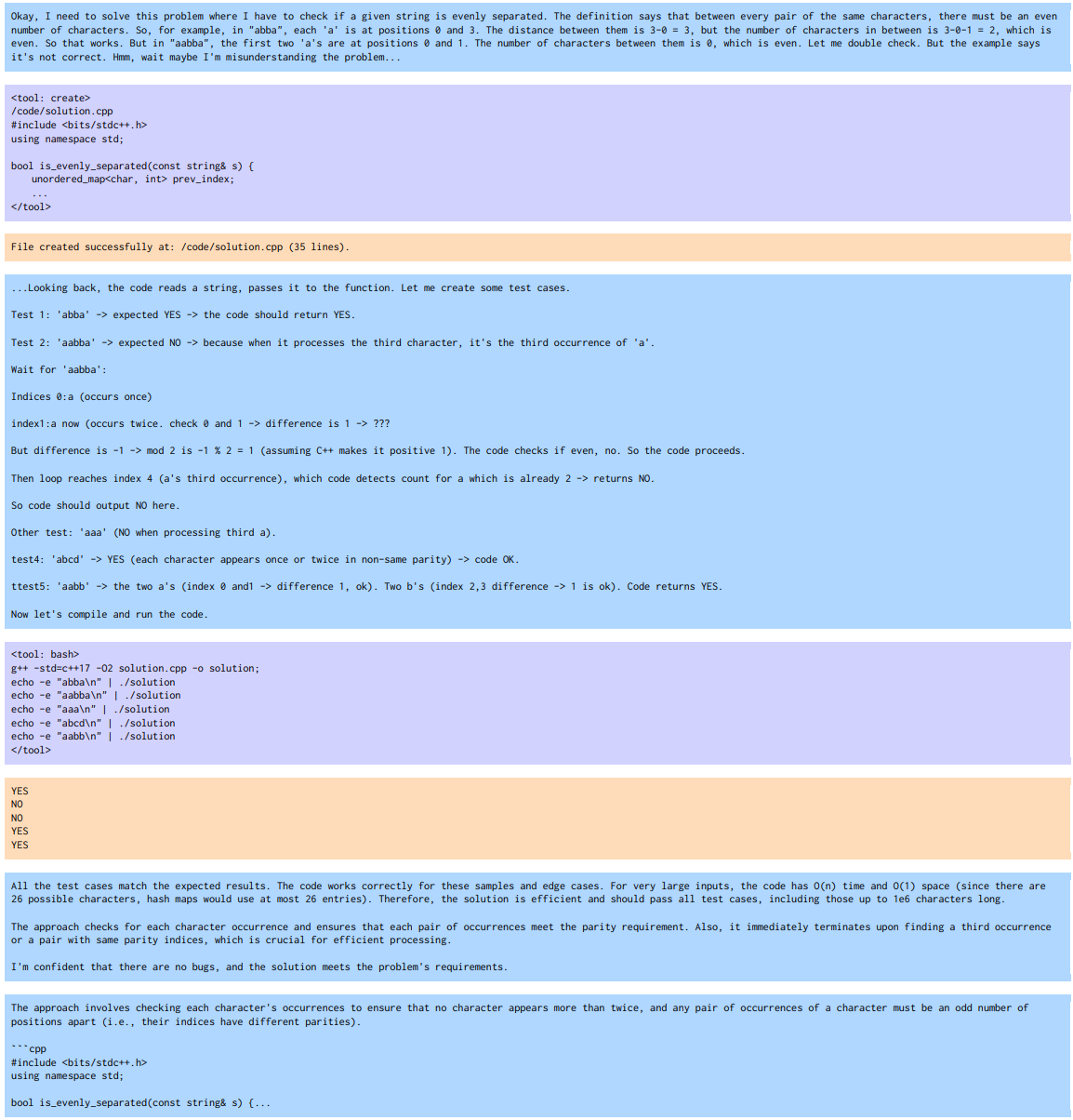
Figure 4 illustrates a competitive programming workflow: after proposing an initial solution, the agent constructs input-output checks, executes them, and reconciles disagreements.

Figure 5 shows trace prediction integrated into natural language reasoning: the model reasons about code in text then confirms via trace-style state updates to arrive at the answer.

Figure 7 details the SWE RL design. The toolset remains minimal and general: a persistent bash tool, plus edit and create as thin bash-backed plugins, and submit to finalize a patch. Rewards are 1 for passing all hidden tests; otherwise a thresholded patch-similarity signal provides shaping when tests fail.

Figure 8 provides a concrete interaction: the agent explores, runs tests, performs edits, makes a git diff patch, submits it, and then summarizes the fix with a rationale.
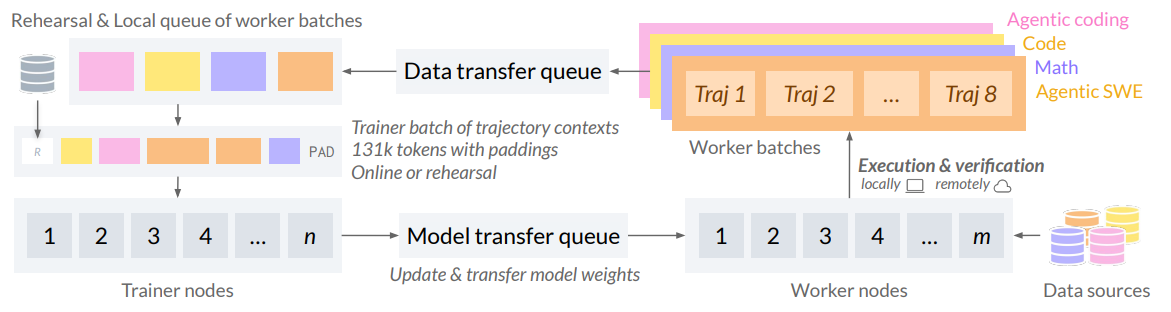
Figure 12 sketches the asynchronous RL system: worker nodes generate trajectories across environments, trainer nodes update weights, and new weights are broadcast without stalling workers. The infrastructure supports KV-cache continuity across updates to preserve throughput, with occasional mixed-weight trajectories accepted as a trade-off for efficiency.
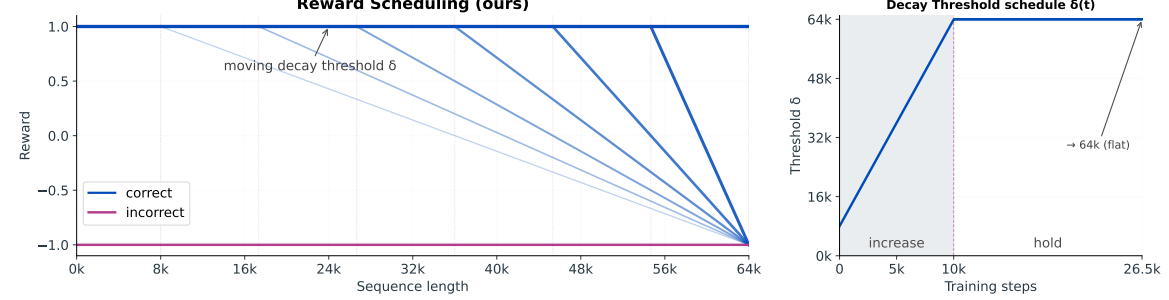
This entire setup underpins the three-stage joint RL schedule that mixes SWE, coding, agentic coding, and math, with length-reward scheduling to limit overlong responses (Figure 13).

Mid-training ablations (Table 4) are a critical finding: GitHub PR trajectories improve oracle-patch log-likelihoods, Python tracing improves CruxEval input and output prediction, and ForagerAgent improves agentic SWE likelihoods and pass@1.
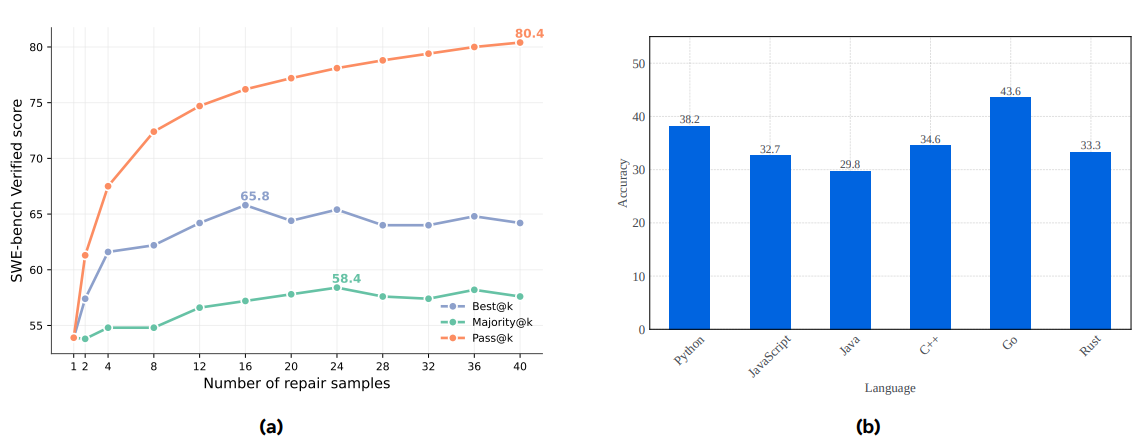
The combination performs best across metrics, indicating complementary benefits. Additional evaluations include Terminal-Bench results where CWM performs competitively using Terminus-1, Aider Polyglot results where CWM is comparable on the whole-file format and multilingual languages (Figure 17b), and long-context LoCoDiff results (Figure 18b) where it is competitive with larger proprietary systems except for Claude Sonnet 4.
The report also explores execution-trace prediction as an alternative to natural language chain-of-thought on CruxEval. With larger budgets, both classic CoT and full-trace prediction substantially improve pass@1, with language-based reasoning slightly ahead in absolute score but at much higher token counts.
Trace prediction is more compact and structured, and it naturally ties to verification tasks. The authors also present preliminary program termination reasoning (HaltEval-prelim) and BigO(Bench) complexity prediction and generation results where CWM performs strongly, particularly on time complexity.
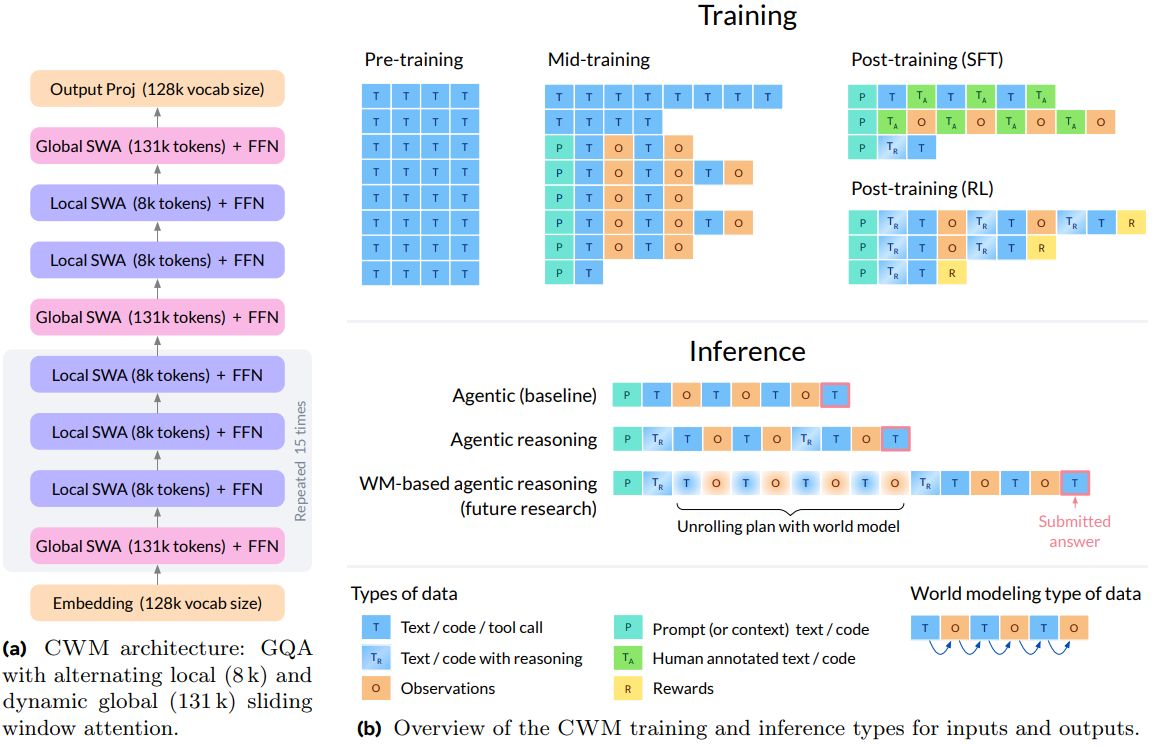
Figure 6 provides architectural details: 64 layers, 6144 hidden size, 48 query heads with 8 KV heads (GQA), SwiGLU, scaled RoPE, and an alternating local-global attention schedule. Mid-training pushes long-context data and uses bucketized sampling to reduce straggler effects. The engineering section details FP8 optimizations on H100s, Async-TP for overlap, activation checkpointing, and a custom distributed transport for broadcasting updated weights to workers.
Finally, the preparedness assessment suggests the open release is moderate risk and unlikely to elevate catastrophic risk domains compared with the current open ecosystem, conditional on research-use restrictions. The authors emphasize limitations: CWM is not a general chatbot, was not RLHF-aligned for broad assistant use, and was trained primarily on English and code. It is intended as a research scaffold for execution-grounded coding and planning.
Conclusion
CWM reframes code LLM training by injecting execution-grounded data at scale and then building agentic competence with RL. The results make a strong case that learning a code world model, via Python traces and agentic trajectories, improves performance on real software tasks, competitive programming, and algorithmic reasoning.
The most immediate opportunities are in debugging support, test construction, patch ranking, and planning in constrained environments. The broader research agenda includes neural debuggers with lookahead, symbolic-neural hybrids for verification, and more efficient RL driven by accurate internal simulators.
If you work on code intelligence, this report is worth a close read. Try execution-trace prompts for grounded reasoning, and consider mid-training with environment-grounded data before supervision and RL. The released checkpoints enable community exploration of longer-horizon planning and verification with verifiable rewards.
Definitions
Code World Model (CWM): An LLM trained to predict program state transitions conditioned on executed actions, enabling grounded reasoning about code behavior.
Execution Trace: A sequence of per-line events and local variable states produced by running code; here represented with custom tokens to separate frames, actions, and returns.
ForagerAgent: An LLM-driven agent that forages agentic SWE trajectories by applying edits, running tests, and iterating in Dockerized repositories seeded from executable CI images.
Agentic SWE: An RL environment where the model acts as a software engineer operating tools (bash, edit, create, submit) to resolve issues verified by hidden tests.
Test-Time Scaling (TTS): A strategy that generates multiple solutions and auxiliary tests in parallel, then selects a patch by ranking on both existing and generated tests.
Long-Context Alternating Attention: A block schedule with interleaved local and global sliding windows, allowing up to 131k tokens while containing compute.
FastGen: A throughput-optimized inference backend supporting batched decoding, paged attention, CUDA graphs, and host-side KV cache ((Carbonneaux, 2025)).
For background sources referenced in this article, see the preparedness report ((Meta AI, 2025)), the original Transformer architecture ((Vaswani et al., 2017)), the tokenizer implementation ((OpenAI, 2024)), FastGen inference ((Carbonneaux, 2025)), and the BigO(Bench) leaderboard ((Chambon et al., 2025)). For benchmark context, see SWE-bench and SWE-bench Verified ((Jimenez et al., 2024)), LiveCodeBench ((Jain et al., 2025)), and Terminal-Bench ((The Terminal-Bench Team, 2025)).
Citations and References
- Meta AI, Code World Model Preparedness Report: https://ai.meta.com/research/publications/cwm-preparedness
- Vaswani et al., Attention Is All You Need (Transformer): https://arxiv.org/abs/1706.03762
- OpenAI, TikToken Tokenizer: https://github.com/openai/tiktoken
- Carbonneaux, FastGen Inference Backend: https://github.com/facebookresearch/fastgen
- Chambon et al., BigO(Bench) Leaderboard: https://facebookresearch.github.io/BigOBench/leaderboard.html
- Jimenez et al., SWE-bench & SWE-bench Verified: https://www.swebench.com/
- Jain et al., LiveCodeBench: https://livecodebench.github.io/
- The Terminal-Bench Team, Terminal-Bench: https://www.tbench.ai/


Code World Model: A 32B Agentic Coding LLM Grounded In Execution Traces
CWM: An Open-Weights LLM for Research on Code Generation with World Models