Artificial intelligence is increasingly a collaborator in scientific inquiry, but most systems still separate the way models learn to reason from the way end users steer them. The paper "Cognitive Loop via In-Situ Optimization: Self-Adaptive Reasoning for Science" proposes CLIO, a cognitive loop that orchestrates how large language models (LLMs) form, evaluate, and adapt their own strategies at inference time.
Rather than relying on post-training to hard-wire reasoning styles, CLIO exposes a controllable, transparent process for "how" the system thinks - aimed at science workflows where traceability, intervention, and defensible choices matter.
Authored by Newman Cheng, Gordon Broadbent, and William Chappell of Microsoft Discovery and Quantum, the work evaluates CLIO on the Humanity's Last Exam (HLE) biology and medicine questions without tool use, showing a Pass@1 accuracy of 22.37% with GPT-4.1 - an improvement over the base GPT-4.1 (8.55%) and OpenAI's o3 in both low and high reasoning effort modes (11.18% and 13.81%, respectively).
While HLE is rapidly becoming a common barometer for agentic systems, the authors argue that steerability, uncertainty awareness, and runtime adaptation are equally important for real science. See benchmark context at (HLE, 2024) and OpenAI's reasoning model overview at (OpenAI, 2024).
Key Takeaways
- Inference-time control: CLIO lets users control reasoning depth and breadth, adapt strategies when confidence is low, and terminate or continue thought channels based on semantic completion conditions.
- Graph-induced reduction: Multiple sampled chains of thought are converted into an LLM-induced graph, clustered, summarized, and queried to reduce "over-indexing" on a single strong-but-wrong argument, inspired by Graph RAG (Edge et al., 2024).
- Measured gains: On 152 HLE biology/medicine questions without tools, GPT-4.1 with CLIO achieved 22.37% Pass@1, surpassing o3 high/low modes and base GPT-4.1.
- Uncertainty as a signal: Oscillation patterns and slopes in internal uncertainty correlate with correctness; rising uncertainty or persistent oscillations flag when human intervention is prudent.
- "More thinking" mode: Ensembling multiple CLIO runs with DRIFT search over the graph representation further improves performance; DRIFT combines global and local queries (Whiting et al., 2024).
- Open, steerable design: CLIO's transparency enables mid-stream corrections, personalized reasoning styles, and post-hoc audits - key for high-stakes scientific contexts.
- Limitations to consider: The evaluation is text-only without tools; absolute accuracy is modest and costs can be high in "more thinking" mode, though transparency and controllability are the primary value-adds.
- Potential applications: Materials discovery, legal analysis, and financial forensics where combinatorial search benefits from clean branching and graph-based consolidation.
- Reproducibility note: The paper reports repeated runs to estimate variability; CLIO shows lower standard deviation than o3 when configured as described.
Overview
CLIO reframes the reasoning problem as orchestration rather than post-training. The system's core idea is to allow an LLM to propose and refine "ways of thinking" on demand - akin to setting an experimental plan - while dynamically measuring confidence and progress.
This yields two complementary axes of exploration: breadth (sample multiple distinct strategies) and depth (recursively extend a chosen strategy while keeping a clean, independent context window per thought channel). That separation helps minimize semantic pollution when drilling down on a branch.
This approach builds on long-context prompting tools like chain-of-thought and ReAct but makes orchestration native to the system rather than encoded in a single prompt. For background, see chain-of-thought prompting (Wei et al., 2022) and ReAct (Yao et al., 2023).
CLIO adds explicit runtime control over recursion depth, confidence thresholds, and a special semantic completion function that is only enabled after sufficient coverage to avoid premature stopping - a guard against the "lost in the middle" and long-context fragility effects noted in prior work (Liu et al., 2023); (Hsieh et al., 2024).
Algorithmically, (Below) sketches CLIO's recursion: from a current state s and depth d, the system halts when a terminal condition is met or confidence exceeds a threshold; otherwise it samples a branching set of next states and recurses, subject to a maximum depth. Clean per-branch contexts enable focused refinement. When depth is exhausted without a confident terminal state, the system falls back to a bounded breadth search, returning a set of candidate states for synthesis.
Algorithm 1: CLIO’s Recursive Algorithm
Input: Initial semantic state
; branching factor ; maximum depth ; confidence threshold ; current depth ; confidence Output: Synthesized answer from LLM based on terminal/high-confidence states
1. Definitions:
-
: Completion (terminal) function; returns 0 if is a solved/terminal state, otherwise -
: Confidence function; returns a real-valued confidence score for state -
: LLM samples possible next states from -
: LLM synthesizes answer from set and current context 2. Function
: - If
or , then return
- If
, then
While
do:
If
or , then
Break
Return
-
-
- For
to (in parallel):
- Return
To counter over-indexing on a single chain, CLIO converts multiple sampled chains into a graph: entities and relations are extracted with an LLM, communities are clustered, each community is summarized, and then a final answer is produced by querying this graph representation (Figure 2).
This is conceptually aligned with Graph RAG's local-to-global summarization and querying paradigm (Edge et al., 2024). For final selection, the authors use DRIFT search - a hybrid of global and local queries over the graph - to balance signal from different subgraphs (Whiting et al., 2024).
Why It Matters
Reasoning-class models like o3 are powerful, but their internal policies and instincts are typically opaque to end users. In science, opacity is a liability: researchers need to see why a conclusion is plausible, where assumptions diverged, and when confidence is deteriorating. CLIO's emphasis on steerability - control over depth, branching, uncertainty thresholds, and post-hoc graph reduction - shifts agency back to the scientist. It also better fits workflows where the model is a collaborator rather than an oracle.
Beyond biology and medicine, the pattern is broadly relevant. Any domain with combinatorial search or layered assumptions - materials discovery, policy analysis, legal reasoning, financial forensics - benefits from clean branch contexts, explicit semantic stopping criteria, and graph-induced aggregation to avoid single-path bias.
The design complements emerging "AI co-scientist" systems (Gottweis et al., 2025) and automated discovery frameworks (Lu et al., 2024), as well as biomedical agent platforms like BioMNI (Huang et al., 2025) and TxGemma (Wang et al., 2025).
Discussion
We first contextualize the setup to make the findings interpretable. The study evaluates CLIO in a tool-free, text-only setting on 152 biology and medicine questions from Humanity's Last Exam (HLE).
Pass@1 is used as the headline metric, and the authors repeat runs to gauge variability while keeping prompt, recursion depth, branching factor, and sampling settings fixed unless explicitly changed. This isolates the contribution of inference-time orchestration and graph-induced reduction from confounders like retrieval quality or external tools.
At a glance, GPT-4.1 augmented with CLIO reaches 22.37% Pass@1, which is higher than OpenAI's o3 in both low (11.18%) and high (13.81%) effort modes and the base GPT-4.1 (8.55%).
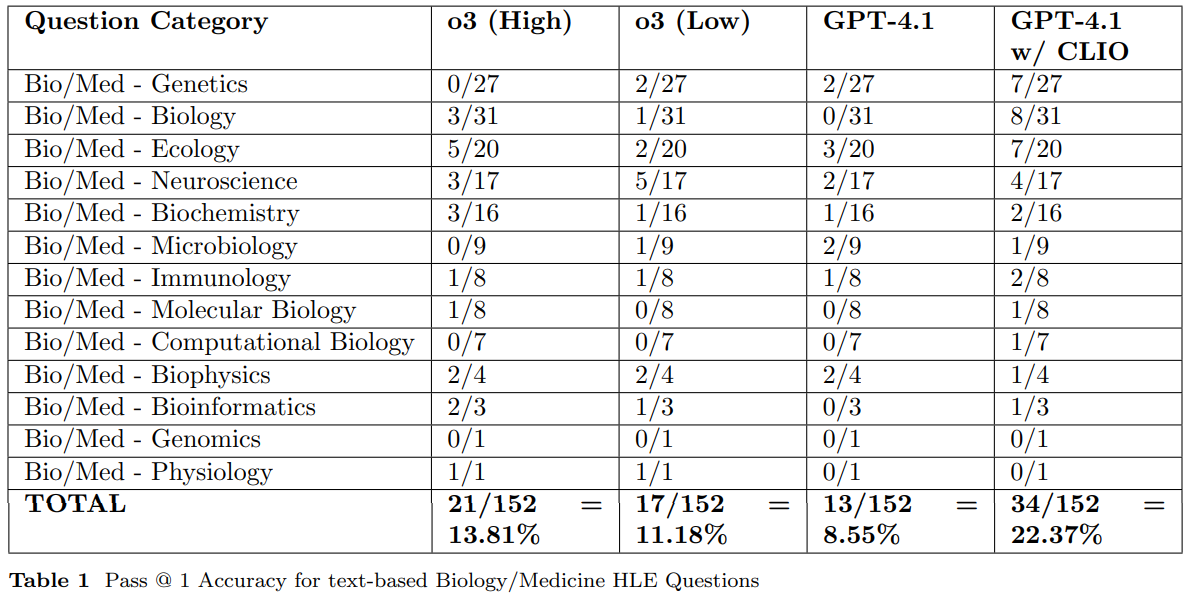
Table 1 breaks down performance by subcategory (genetics, biology, ecology, neuroscience, etc.), showing consistent gains in several areas. Category-level results (Table 1) indicate notable gains in genetics, biology, and ecology, among others, while performance remains mixed in a few smaller subdomains. The authors repeat Pass@1 runs to estimate variability, observing lower standard deviation with CLIO than o3, evidence that graph-induced reduction and DRIFT selection stabilize outcomes despite sampling.
In a "more thinking" configuration that ensembles multiple CLIO runs, accuracy improves further; the paper reports a +7.90 percentage-point lift over the standard CLIO setting, consistent with the hypothesis that breadth-wise exploration plus principled reduction reduces over-indexing on a single strong-but-wrong chain.
Results.
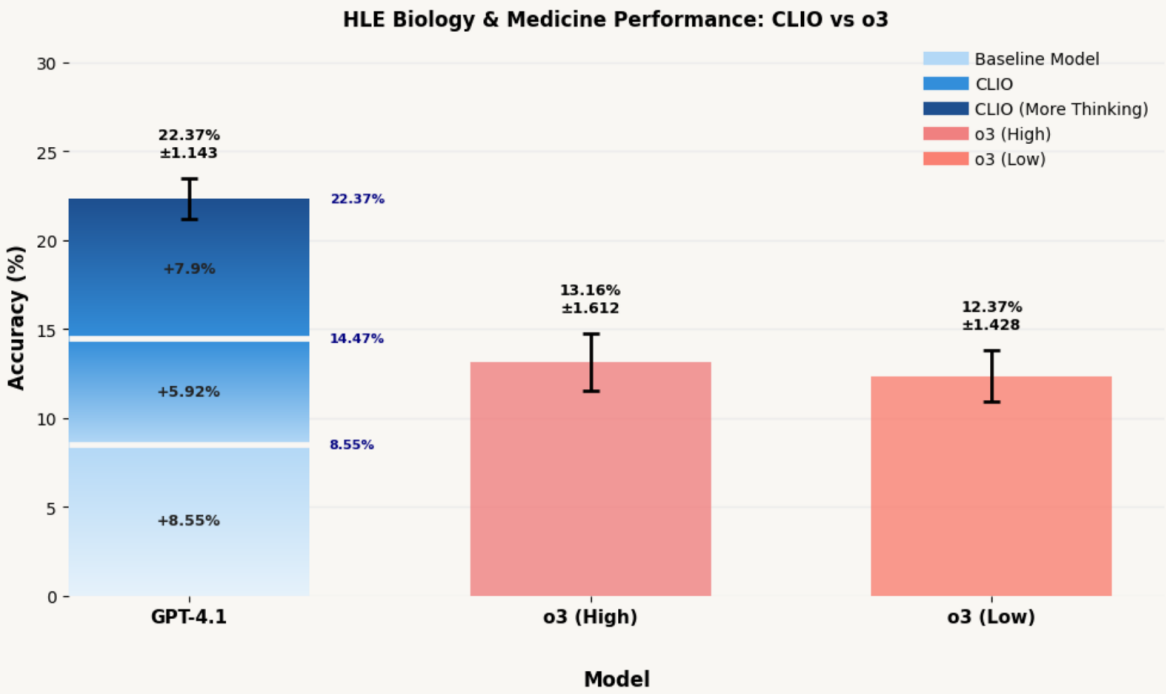
Fig. 3 GPT-4.1 with CLIO demonstrates on par performance with o3 in high and low reasoning efforts, while CLIO with More Thinking enables a leap in performance.
Figure 3 in the paper reports Pass@1 accuracy on 152 HLE biology/medicine questions: GPT-4.1 with CLIO achieves 22.37%, outperforming o3 in low (11.18%) and high (13.81%) effort modes and base GPT-4.1 (8.55%).
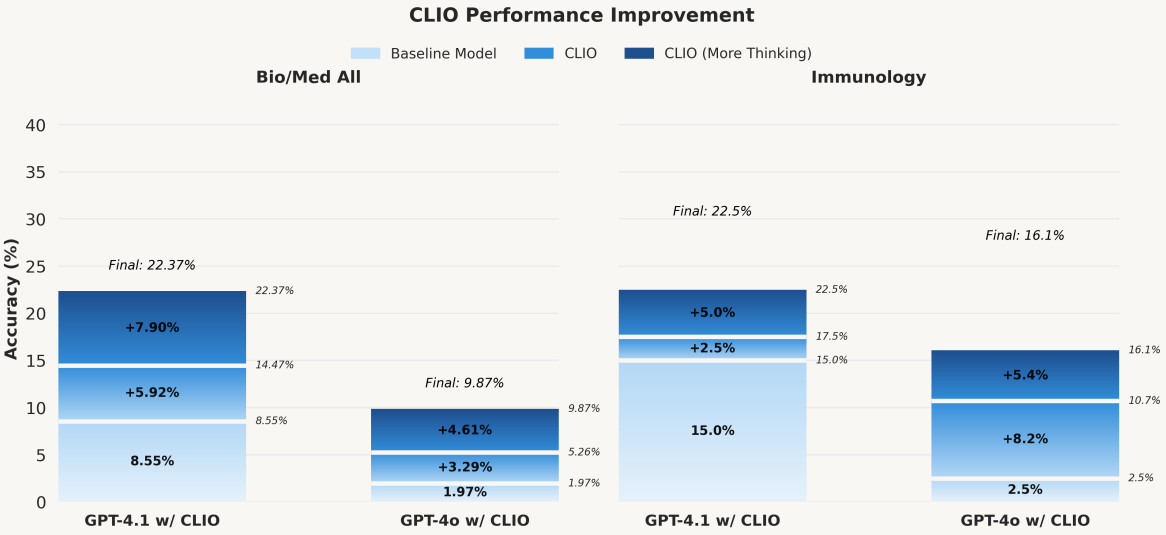
Fig. 4 Increasing CLIO’s performance through increased thinking
Figure 4 shows that increasing "thinking" (i.e., more chains aggregated into the graph) further raises accuracy, consistent with the hypothesis that multi-path ensembling plus principled reduction reduces over-indexing on a single confident but wrong chain. This echoes broader findings that breadth helps in lower-complexity regions while depth helps in higher-complexity regions, with adaptive allocation across both (Silver et al., 2016).
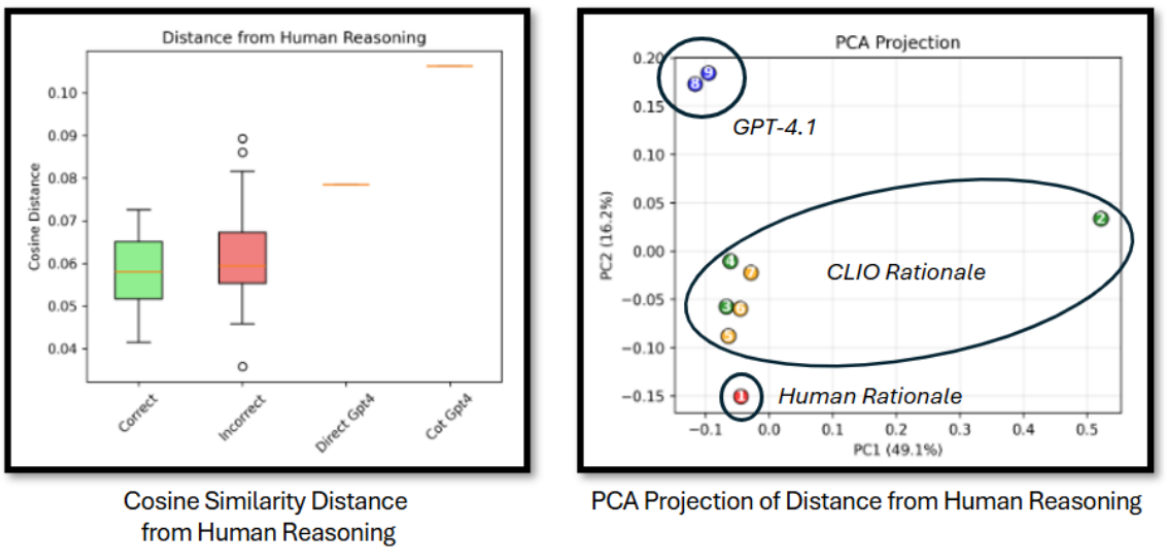
Fig. 5 CLIO’s produced chain of thoughts are more similar to human reasoning
Figure 5 analyzes similarity between human rationales and model chains, finding CLIO's chains closer to human-annotated rationales than base GPT-4.1. The study projects embeddings of both systems' chains (via text-embedding-3-large) into a 2D space and compares neighborhoods. While embedding similarity is an indirect proxy, it provides evidence that CLIO's process, not just its final answers, tracks human reasoning structure more closely.
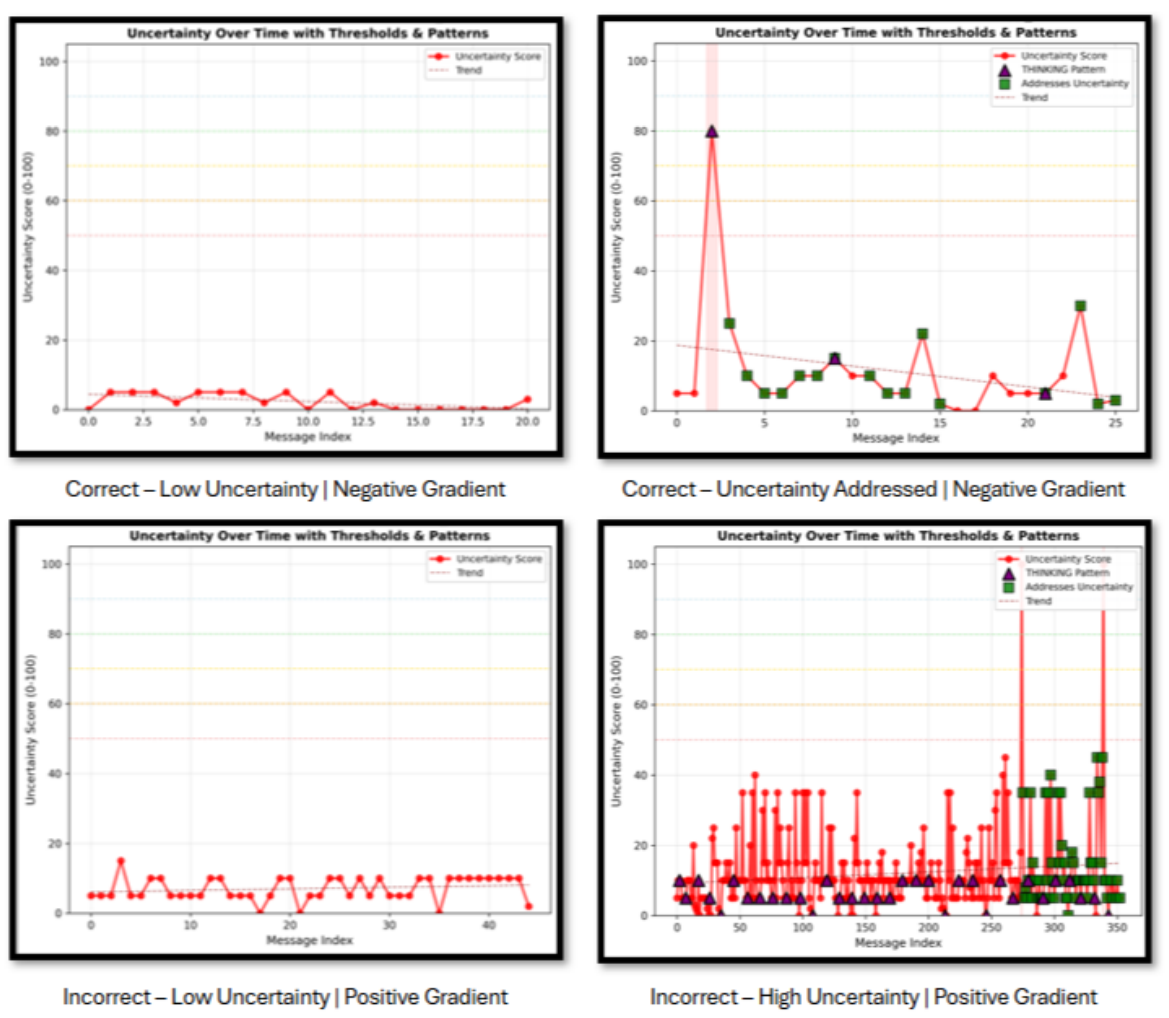
Fig. 6 Direct comparison of CLIO’s internal uncertainty principles when correct and incorrect.
Figure 6 studies uncertainty over time across four patterns: (1) correct with low uncertainty and negative slope; (2) correct with spikes that get resolved after recursive branches; (3) incorrect with low uncertainty but positive slope; and (4) incorrect with high, oscillatory uncertainty and positive slope. The negative slope in correct cases suggests that CLIO's recursive branches help mitigate doubt and converge, whereas rising or oscillatory uncertainty is a strong flag for human intervention. Operationally, these patterns can drive escalation policies in lab-in-the-loop settings and help triage which runs need expert review.
Limitations.
The study evaluates text-only HLE questions without tools. This isolates the reasoning/control contribution but leaves open questions: how do tool calls, retrieval quality, and domain-specific calculators interact with CLIO's loop? Also, the absolute accuracy remains modest; the value proposition is the combination of gains with transparency and control. Finally, the approach's runtime and token costs can be substantial, especially in "more thinking" mode. The authors frame this under Accuracy, Cost, and Time (ACT), noting that scientific value can outweigh compute for difficult discovery tasks.
Relation to prior methods.
CLIO complements, rather than replaces, post-trained reasoning models. The work emphasizes that inference-time orchestration can upgrade completion models (e.g., GPT-4.1) into reasoning-like behavior and even combine with reasoning models (o3, Phi-4, Grok-4) when uncertainty flags suggest escalation.
Its graph reduction aligns with Graph RAG principles (Edge et al., 2024), and its semantic stopping explicitly counters long-context fragility (Liu et al., 2023); (Hsieh et al., 2024). It also resonates with research on verifiable rewards and internal confidence signals in reinforced reasoning (Wen et al., 2025); (Zhao et al., 2025).
Conclusion
CLIO is a practical blueprint for making reasoning controllable, auditable, and adaptable at inference time. By combining clean recursive thought channels, semantic completion, graph-induced aggregation, and DRIFT selection, it delivers measurable gains on a tough benchmark and, more importantly, surfaces when and how to intervene.
For science teams, that's the difference between a black-box assistant and a collaborative system that can be steered, corrected, and trusted. Readers can consult the source paper (PDF in this workspace) and background work on Graph RAG (Edge et al., 2024), DRIFT search (Whiting et al., 2024), chain-of-thought (Wei et al., 2022), and ReAct (Yao et al., 2023).
Definitions
CLIO: A cognitive loop for inference-time optimization that lets an LLM generate, adapt, and terminate multiple reasoning paths with explicit confidence and coverage controls.
Semantic Completion: A termination criterion that becomes available only after sufficient coverage, combining confidence with a notion of progress to avoid premature stopping.
Graph-Induced Reduction: Converting multiple chains of thought into a graph of entities/relations, clustering and summarizing communities, and querying the graph to select balanced evidence.
DRIFT Search: A search strategy that blends global and local queries over a graph to retrieve complementary evidence (Whiting et al., 2024).
Pass@1: The fraction of questions answered correctly on the first attempt.
HLE (Humanity’s Last Exam): A benchmark designed to evaluate AI agents on domain-rich, long-horizon tasks; used here for biology/medicine questions (HLE, 2024).


CLIO: A Cognitive Loop for Self-Adaptive Reasoning in Science
Cognitive Loop via In-Situ Optimization: Self-Adaptive Reasoning for Science