Picture an artificial intelligence that not only observes but predicts the unfolding of real-world events, adapts to unfamiliar spaces, and empowers robots to interact with objects they've never seen before. This is the promise realized by Meta's V-JEPA 2, a groundbreaking video-based world model that sets new standards in physical reasoning and robotic control.
What Sets V-JEPA 2 Apart?
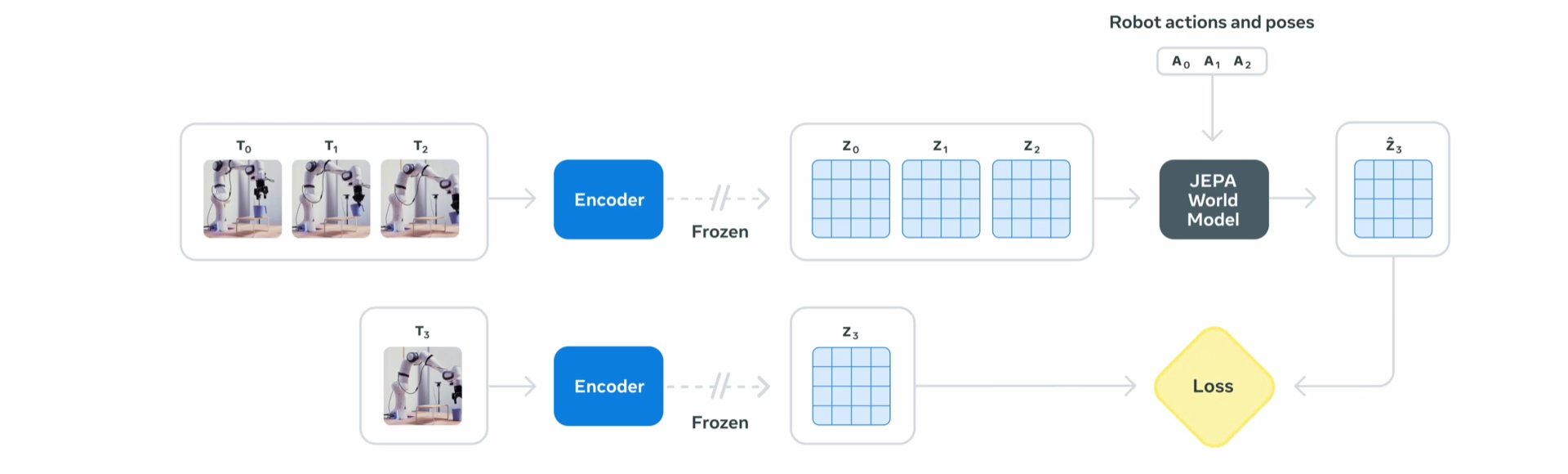
V-JEPA 2, short for Video Joint Embedding Predictive Architecture 2, builds on massive data and sophisticated architecture. With 1.2 billion parameters and training on more than a million hours of videos and images, it achieves a remarkable understanding of physical dynamics and object interactions. Unlike earlier models, V-JEPA 2 unlocks zero-shot robot planning, enabling robots to tackle novel tasks and environments without prior exposure.
- Self-supervised learning: V-JEPA 2 learns directly from raw video, extracting knowledge about interactions and object behavior without the need for human-annotated labels.
- Two-stage training: The model undergoes broad visual pre-training, then is fine-tuned on robot action data. This enables accurate, action-conditioned predictions with minimal robot-specific information.
- Joint-embedding architecture: An encoder creates detailed world representations from video. A predictor then leverages these embeddings, along with action cues, to forecast future states.
Proven Performance on Real-World Benchmarks
V-JEPA 2 leads on several benchmarks that test not just recognition, but true physical reasoning:
- Action recognition & anticipation: The model sets new records on datasets like Something-Something v2 and Epic-Kitchens-100, demonstrating the ability to interpret motion and anticipate future actions.
- Video question answering: When combined with language models, V-JEPA 2 achieves top results on video QA tasks (Perception Test, TempCompass), showcasing an understanding of complex scenarios.
- Zero-shot robot planning: Robots guided by V-JEPA 2 successfully perform pick-and-place tasks with unfamiliar objects in new environments, reaching 65%–80% success rates using only goal images.
Raising the Bar: New Open Benchmarks
To drive further progress, Meta has introduced three challenging, open-source benchmarks designed to probe the limits of AI physical reasoning:
- IntPhys 2: Evaluates whether AI can tell physically plausible events from subtle impossibilities. While humans excel, current models, including V-JEPA 2, struggle to outperform random guesses.
- Minimal Video Pairs (MVPBench): Tests whether models can answer physical reasoning questions without relying on shortcuts by using carefully constructed video pairs and multiple-choice formats.
- CausalVQA: Focuses on cause and effect, counterfactual thinking, and anticipation in physical scenarios. Models currently fall short of human abilities, especially when reasoning about alternative outcomes or future possibilities.
These benchmarks, datasets, and leaderboards are openly available, challenging the global AI community to measure and accelerate progress in machine physical reasoning.
The Road Ahead: Toward Human-Like AI Agents
Meta’s vision for V-JEPA extends beyond current achievements. Planned advancements include expanding the model’s planning capabilities across multiple time scales, mirroring how humans tackle complex tasks in steps, and integrating additional sensory inputs like audio and touch.
By releasing V-JEPA 2 and these demanding benchmarks, Meta is inviting researchers to help bridge the gap between current AI and human-level intuition, aiming for robust, adaptable AI agents suited for real-world challenges.
Takeaway
V-JEPA 2 represents a major leap toward sophisticated machine intelligence, but a considerable gap remains before AI matches human physical reasoning. The open benchmarks and resources signal both a challenge and an opportunity for researchers to close this gap, paving the way for intelligent agents that can learn, reason, and act in our dynamic world.
Source: Meta AI Blog


V-JEPA 2: Transforming AI Physical Reasoning and Zero-Shot Robot Planning