Compressing a large language model by 75% and still outperforming the latest releases from OpenAI and Anthropic is the promise of Unsloth Dynamic GGUFs. Their integration with the Aider Polyglot benchmark demonstrates that advanced quantization techniques can deliver efficient, highly capable AI models without major sacrifices in quality.
Compression Without Compromise
Unsloth's approach focuses on aggressive reduction in model size, yet maintains or even improves performance in key areas. Here are the standout results:
- 1-bit Unsloth Dynamic GGUF compresses DeepSeek-V3.1 from 671GB to 192GB which is a 75% reduction while still beating GPT-4.1, GPT-4.5, and DeepSeek-V3-0324 in "no-thinking" mode.
- 3-bit quantization in "thinking" mode surpasses Claude-4-Opus (May 2025), and 5-bit matches its "non-thinking" performance.
- Other quantization methods often fail at low bit-widths, producing errors or meaningless outputs, but Unsloth preserves both output quality and functionality.
- Unsloth models consistently outperform other community GGUF quantizations, especially at extreme compression levels.
The Aider Polyglot benchmark rigorously tests LLMs on coding, writing, following instructions, and complex tasks, making it a trusted standard for real-world performance.
Unsloth Dynamic Quantization: The Secret Ingredient
Rather than treating every layer equally, Unsloth's method:
- Assigns higher precision (8 or 16 bits) to crucial layers, compressing less critical ones to 1–6 bits.
- Uses a custom calibration dataset (imatrix) to optimize both chat and coding abilities.
- Delivers high compression for vision and language models avoiding quality loss found in naive quantization techniques.
This selective per-layer quantization is now the preferred strategy for Mixture-of-Experts (MoE) models and beyond, ensuring quality where it matters most.
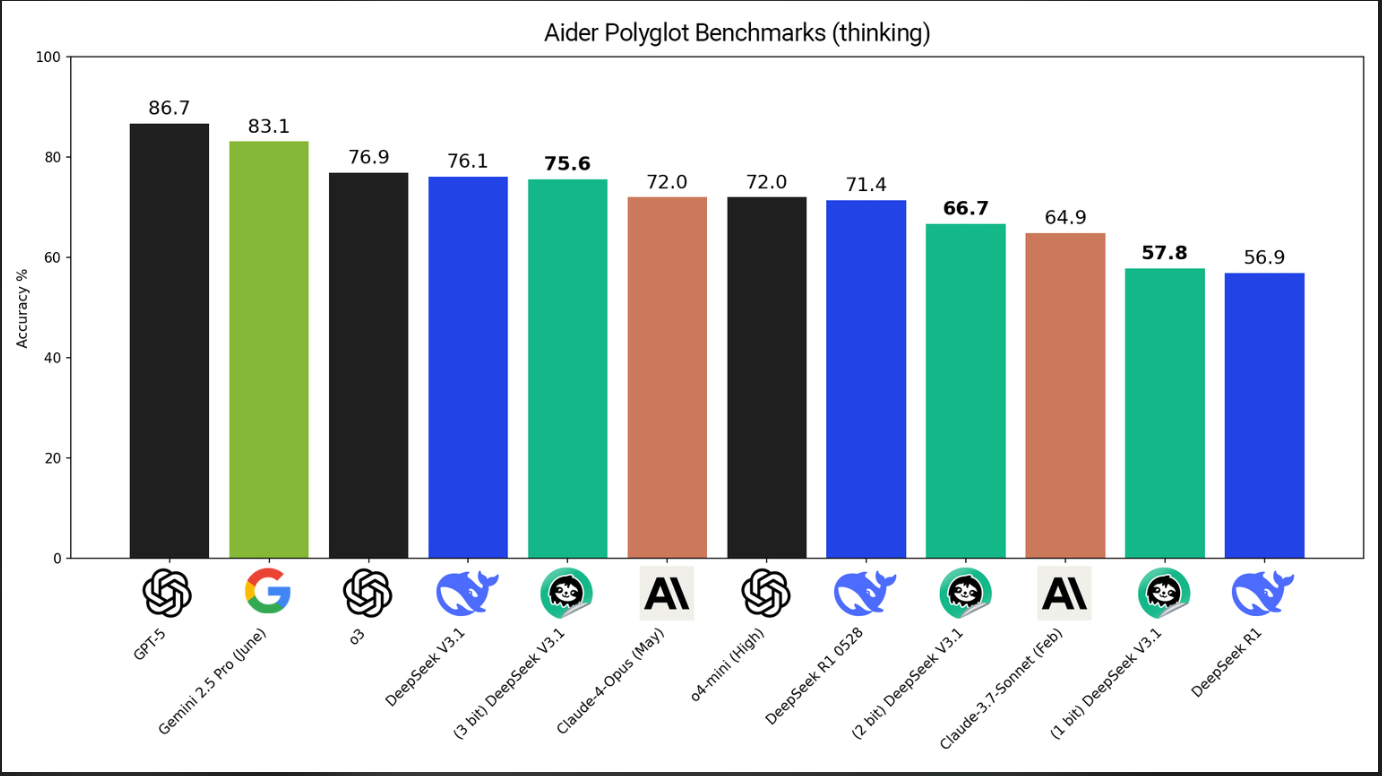
Benchmarking: Performance That Holds Up
Third-party testing on the Aider Polyglot suite confirms Unsloth's claims:
- 3-bit DeepSeek V3.1 Unsloth achieved 75.6% in reasoning mode, nearly matching the full-size original and outperforming leading models.
- 1-bit models still scored 57.8%, beating several mainstream competitors at a fraction of their size.
- On "no-thinking" tasks, the 5-bit quantized model scored 70.7%—almost on par with full-sized Claude-4-Opus and original DeepSeek models.
- Unsloth's quantizations showed a smooth trade-off curve: even as compression increases, performance remains robust compared to traditional methods.
Comparisons and Ablation Insights
Comparative studies show that Unsloth's dynamic quantizations consistently outperform or match other community imatrix GGUFs, particularly at lower bit-widths where competitors struggle or fail. Ablation studies highlight that assigning higher precision to specific tensors (such as attn_k_b in DeepSeek V3.1) can significantly boost accuracy, often with minimal increase in file size.
Fixing Bugs and Advancing Open Source
Unsloth's innovations go beyond quantization, they actively fix critical bugs in top open-source models. Collaborations with teams behind Qwen3, Meta (Llama 4), Mistral, Google (Gemma 1–3), and Microsoft (Phi-3/4) have led to essential updates that increase reliability and accuracy for the entire ecosystem.
For example, template bugs in low-bit quantizations previously caused failures in benchmarks. Unsloth's fixes to chat template logic, especially for llama.cpp's jinja/minja, ensure fairer and more accurate benchmarking for all.
Getting Started Is Simple
Unsloth offers easy-to-follow guides and command-line one-liners for downloading and running these highly compressed models locally. Default parameters, chat templates, and environment flags are pre-configured, so users can experience peak performance with minimal setup.
Takeaway
Unsloth Dynamic GGUFs prove that massive language models can be shrunk to a fraction of their original size without giving up performance—and often surpassing industry leaders. Through smart quantization, continuous bug fixes, and rigorous benchmarking, Unsloth is setting a new standard for efficient, open-source AI.
Let's Unlock Your AI's Full Potential
The efficiency gains we see from Unsloth's dynamic quantization techniques are game-changing for anyone serious about deploying AI in production. But getting these highly optimized models to actually work for your business requires more than just downloading and running them. With over two decades of experience building AI-powered systems for startups and tech giants alike, I specialize in turning cutting-edge technology like this into real competitive advantages.
If you're looking to deploy efficient AI models, build intelligent automation pipelines, or create custom applications that leverage the latest in model optimization, I'd love to help. Whether it's integrating quantized models into your existing infrastructure or designing entirely new AI-powered workflows, my software development and automation expertise can help you get there faster. Let's schedule a free consultation to discuss your project.



Unsloth Dynamic GGUFs: How Extreme Model Compression Outperforms AI Giants