Large language models (LLMs) are transforming rapidly, and Google’s T5Gemma brings a refreshing shift by reviving the versatile encoder-decoder architecture. While decoder-only models have garnered much attention, T5Gemma reintroduces the strengths of encoder-decoder designs, offering enhanced flexibility, performance, and efficiency for a wide range of language tasks.
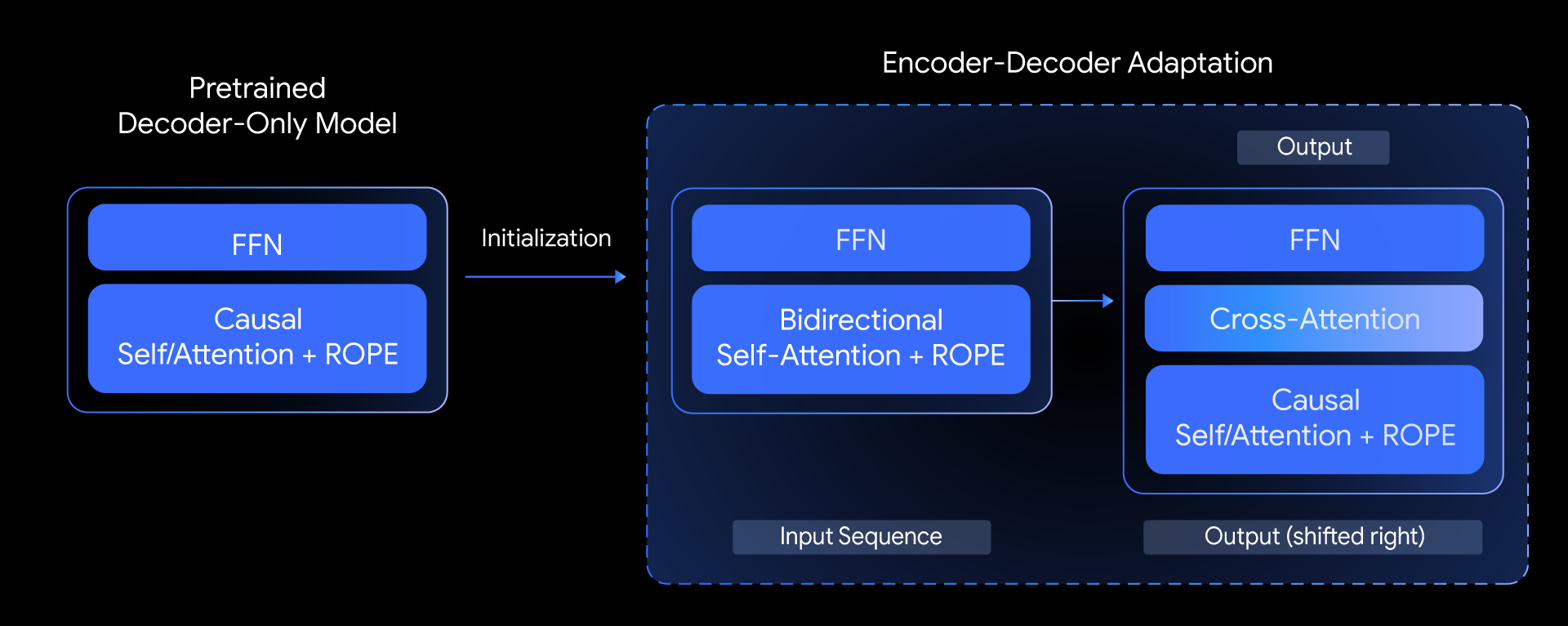
Innovative Adaptation: From Decoder-Only to Dual Architecture
Encoder-decoder models like T5 have historically excelled at tasks requiring deep comprehension, such as summarization, translation, and question answering. Despite these strengths, they’ve been overshadowed by their decoder-only counterparts, until now.
T5Gemma employs a novel approach: it adapts pretrained decoder-only models by initializing an encoder-decoder architecture with their weights, then refines them using advanced pre-training objectives like UL2 or PrefixLM.
This adaptation allows for creative configurations, such as pairing a large encoder with a smaller decoder. Such "unbalanced" models let developers fine-tune the trade-off between quality and speed, optimizing models for the specific demands of different applications.
Pushing the Boundaries of Quality and Efficiency
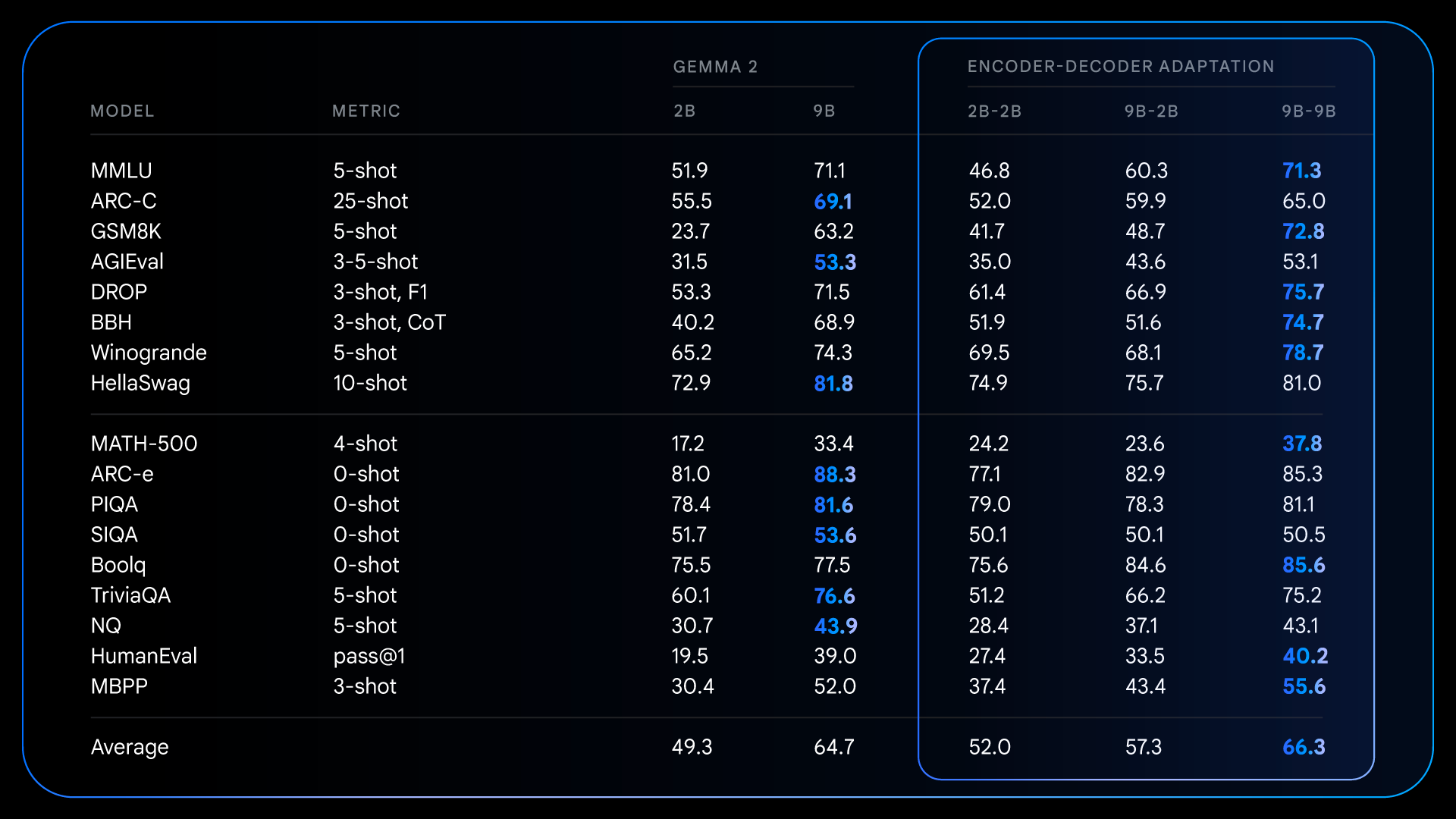
Performance benchmarks show T5Gemma models not only match but often surpass decoder-only models, especially in balancing quality and inference efficiency.
For example, the T5Gemma 9B-9B model achieves superior accuracy with similar latency, while the 9B-2B variant delivers impressive quality with the speed usually expected from much smaller models. This flexibility empowers developers to select the optimal architecture for their needs.
- Superior benchmarks: Leading or matching results on tasks like SuperGLUE and GSM8K.
- Customizable architecture: Mix and match encoder and decoder sizes for tailored performance.
- Practical efficiency: Demonstrated real-world improvements in latency and throughput.
Expanding Capabilities with Instruction Tuning
T5Gemma’s strengths extend beyond architecture. After initial pre-training, these models excel at complex reasoning and comprehension tasks, outperforming their decoder-only predecessors. Instruction tuning further amplifies these gains.
For instance, the T5Gemma 2B-2B IT model’s MMLU score climbs nearly 12 points above Gemma 2 2B, and its math reasoning accuracy on GSM8K rises from 58% to over 70%.
- Enhanced reasoning: Outperforms on benchmarks like GSM8K and DROP.
- Effective instruction tuning: Responds robustly to fine-tuning for real-world applications.
- Flexible training: Supports PrefixLM or UL2 objectives for top-tier generative and representation performance.
Open Access: Fueling Research and Innovation
Google promotes open research by releasing T5Gemma checkpoints in multiple sizes, T5 Small, Base, Large, XL, and Gemma 2B and 9B variants, along with both instruction-tuned and pre-trained models.
The inclusion of unbalanced models, such as the 9B encoder paired with a 2B decoder, gives developers tools to explore nuanced quality-efficiency trade-offs. All resources are available on platforms like Hugging Face, Kaggle, and through Colab notebooks or Vertex AI for hands-on experimentation.
- Wide range of model sizes and variants
- Accessible foundational and instruction-tuned checkpoints
- Extensive community resources and documentation
Ushering in a New Era for LLMs
T5Gemma proves that carefully adapted encoder-decoder models can lead the field in both quality and efficiency. By open-sourcing these models and resources, Google empowers the community to innovate and push the boundaries of what’s possible in AI-driven language understanding. T5Gemma offers developers the tools to create models that are smarter, faster, and more adaptable than ever before.


T5Gemma: Google’s Next Leap in Encoder-Decoder Language Models