Large language models (LLMs) are transforming digital experiences, but their impressive capabilities often come at the cost of slow and expensive inference. As businesses and users expect faster, more affordable AI, researchers are actively seeking solutions that optimize performance without sacrificing output quality. One promising development is the speculative cascades technique, a hybrid approach that aims to make LLM inference both smarter and more efficient.
Understanding Traditional Strategies
Historically, two main strategies have guided LLM efficiency improvements:
- Cascades use a small, fast model to process queries first. If this model is confident, it responds directly; if not, the query passes to a larger, slower model. This method saves resources for simple tasks but can introduce delays when escalation is frequent.
- Speculative decoding involves a small "drafter" model predicting multiple future tokens, while a large model verifies these drafts in parallel. If the drafts are accurate, response time improves significantly. However, frequent mismatches force the larger model to redo the work, often negating speed benefits.
Both approaches offer value but cascades can be slow when handoffs occur, and speculative decoding may waste computation if drafts are often rejected.

Comparison of speculative cascades and speculative decoding on a grade school math question from the GSM8K dataset. The draft tokens are shown in yellow and the verified tokens in red. The speculative cascades approach generates the correct answer, and does so faster than speculative decoding. Credit: Google
What Makes Speculative Cascades Different?
Speculative cascades merge the strengths of both cascades and speculative decoding. Here, a small model drafts responses, while a large model checks them in parallel. The key innovation is the use of a dynamic deferral rule which is a smarter, adaptive process that decides when to accept the small model’s output or defer to the larger model, rather than rigidly verifying every token.
This deferral rule can consider:
- The small model’s confidence in its draft
- The large model’s confidence in overriding
- Cost-benefit analysis of deferral versus acceptance
- Whether the small model’s next token aligns with the large model’s likely options
By flexibly accepting high-quality drafts and only escalating when necessary, speculative cascades reduce unnecessary computation and avoid the sequential delays of traditional cascades.
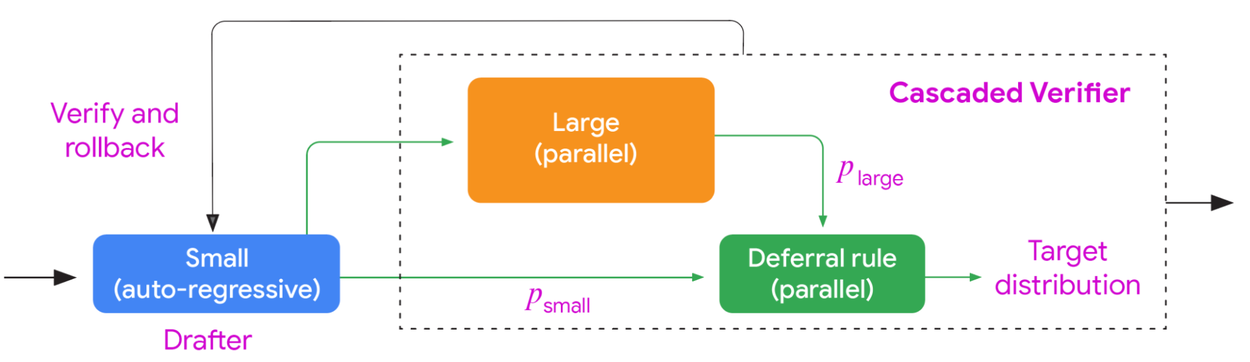
Block diagram illustrating a speculative cascade between a small and large model. As with standard speculative decoding, the drafting process involves auto-regressive sampling from the small drafter model. However, the verification process is different: it considers the combined output distribution of both the small and large models via a deferral rule, rather than solely relying on the large model's output. Image Credit: Google
Illustrative Example: Handling Real-World Prompts
Imagine the prompt, “Who is Buzz Aldrin?” A small model might respond concisely, while a large model offers an in-depth answer. With traditional cascades, a lack of confidence in the small model triggers a handoff.
In regular speculative decoding, any token mismatch can waste the small model’s effort. Speculative cascades, however, uses adaptable rules to accept “good enough” drafts to balance speed with output quality, especially when multiple correct styles exist.
Performance Gains and Experimental Evidence
Researchers evaluated speculative cascades on tasks like summarization, translation, reasoning, coding, and question answering using models such as Gemma and T5. The findings showed that speculative cascades consistently delivered superior cost-quality trade-offs compared to standard cascades and speculative decoding. For equal quality, responses were faster and required fewer calls to the larger model.
Visual analyses from the study reveal that speculative cascades accelerate correct answers, particularly in tasks like grade-school math, by leveraging accurate drafts and minimizing redundant computation.
Broader Impact: Building Smarter, More Efficient AI
As LLMs become foundational to everyday applications, optimizing their speed and efficiency is crucial—not just for cost savings but for user experience. Speculative cascades provide developers with nuanced control over computational resources and output quality, paving the way for responsive, intelligent, and resource-conscious AI systems.
Conclusion
Speculative cascades represent a breakthrough in LLM inference optimization. By combining the best aspects of cascades and speculative decoding, this hybrid method enables faster, smarter, and more economical AI—empowering innovation as LLMs continue to expand their influence.
Source: Google Research Blog


Speculative Cascades: Unlocking Smarter, Faster LLM Inference