The evolution of AI agents has brought us closer to automating complex business tasks, yet measuring their true capabilities remains a challenge. Databricks' OfficeQA is a newly released, open-source benchmark that poses document-grounded, economically relevant questions, mirroring the realities faced by modern enterprises.
Addressing the Shortfalls of Existing Benchmarks
While benchmarks like ARC-AGI-2 and Humanity’s Last Exam test cognitive limits, they fail to capture the hands-on, data-driven work crucial in business processes. Enterprises often need AI to extract and interpret information from sprawling, unstructured datasets, think dense PDFs and intricate tables. OfficeQA bridges this gap by leveraging over 50 years of U.S. Treasury Bulletins, generating questions that reflect the daily challenges Databricks customers encounter.
Distinctive Features of OfficeQA
- Real-World Grounding: Questions are rooted in authentic document content, eliminating abstract puzzles in favor of tasks with clear commercial value.
- Enterprise-Focused Tasks: Each challenge is crafted to demand accuracy and thoroughness, echoing the diligence required for real business decisions.
- Automated, Objective Scoring: Every question has a single, verifiable answer, making large-scale, unbiased evaluation possible.
- Open Access: The dataset is entirely free for research, encouraging collaboration and transparency in AI evaluation.
How the Benchmark Challenges AI
OfficeQA features 246 questions labeled "easy" or "hard" based on AI performance. Queries require extracting figures from specific years, aggregating statistics, or cross-referencing tables.
Human experts typically spend close to an hour per question, primarily tracking down information across thousands of pages. The test assesses not just retrieval skills, but also the ability to reason, synthesize, and aggregate scattered data.
Where AI Agents Fall Short
Leading AI models, including GPT-5.1 and Claude Opus 4.5,were tested using both standard document access and advanced parsing tools like Databricks’ ai_parse_document. Here’s what was uncovered:
- Minimal context access led to correct answers on only about 2% of questions.
- Direct document access improved accuracy to under 45% overall, and less than 25% for the most complex queries.
- Pre-parsed, relevant page access using advanced parsing tools could boost accuracy to 70%,but only in ideal scenarios.
- Persistent weaknesses included handling visual data (charts, graphs), parsing errors (misaligned tables), and ambiguity in evolving financial reports.
Ultimately, even with the best tools, agents struggled with tasks requiring visual interpretation and precise cross-document matching, limitations that still keep humans well ahead in many enterprise scenarios.
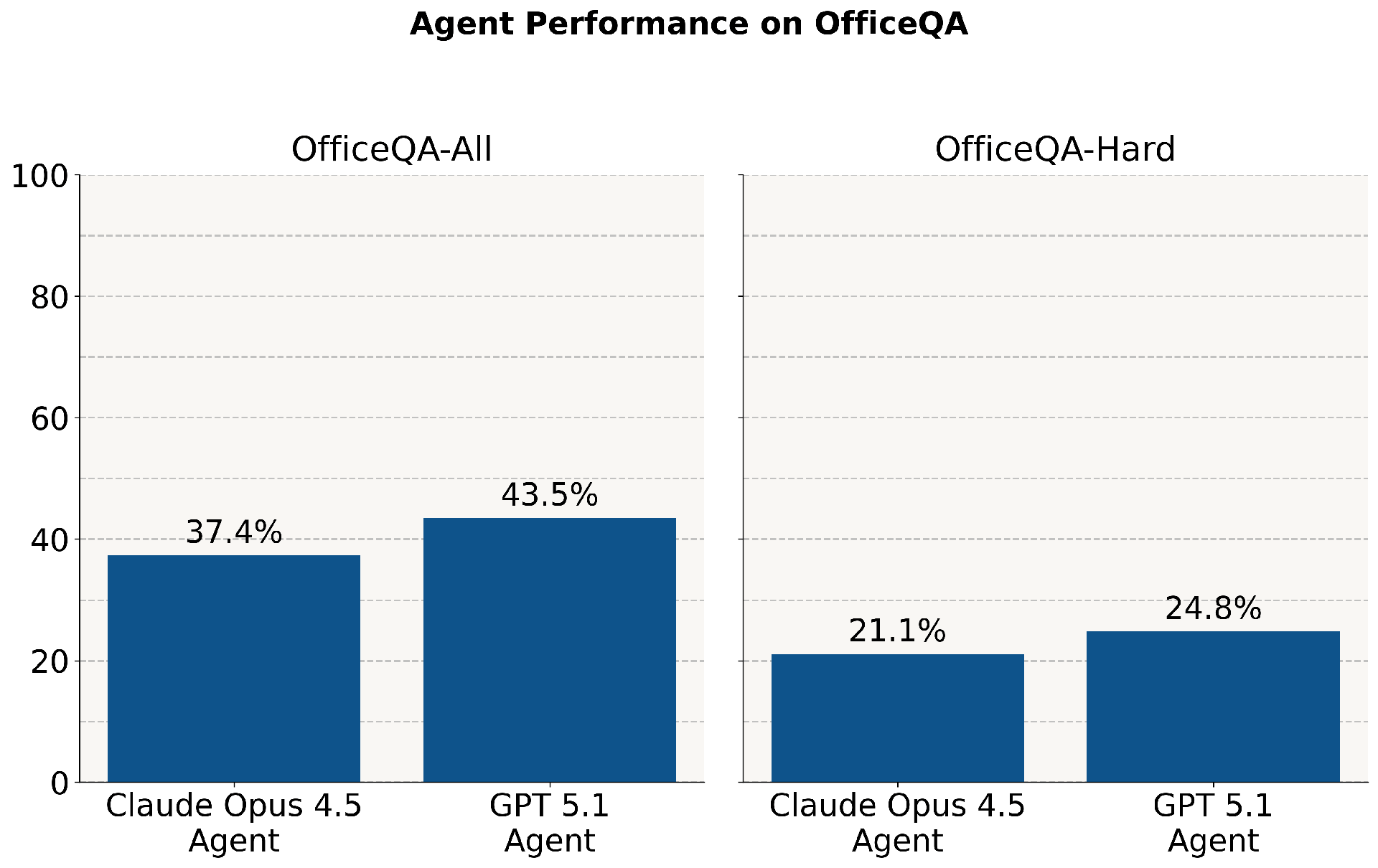
Preview of performance of AI agents on OfficeQA-All (246 examples) and OfficeQA-Hard (a subset of 113 examples), including a Claude Opus 4.5 Agent with default thinking (high) built with Claude’s Agent SDK and the OpenAI File Search & Retrieval API using GPT-5.1 with reasoning_effort = high. Credit: Databricks
Benchmark Design: Rigorous, Yet Accessible
OfficeQA’s strength lies in its focus on precision, not esoteric knowledge. Most questions require nothing beyond public information and basic math skills, but demand careful reading and methodical aggregation. Databricks ensured questions couldn't be answered by general LLM knowledge or simple web searches, keeping the evaluation fair and challenging.
Fostering Progress: The Databricks Grounded Reasoning Cup
To accelerate innovation, Databricks will launch the Grounded Reasoning Cup in Spring 2026. This competition will pit AI agents against human teams on OfficeQA, spotlighting both AI’s advances and its current shortcomings in real-world reasoning.
Conclusion
OfficeQA marks a significant leap in evaluating AI’s practical reasoning skills. While modern agents show promise, their struggles with document-grounded, high-value tasks reveal much work remains. By making OfficeQA open and accessible, Databricks invites the global community to push AI closer to matching, and eventually surpassing, human-level enterprise reasoning.


OfficeQA: The Next Frontier in AI Enterprise Reasoning Evaluation