An NVIDIA AI system accomplished a record breaking 1,000+ tokens per second, per user, from a 400-billion-parameter language model all on a single machine. NVIDIA’s Blackwell architecture, paired with Meta’s Llama 4 405B Maverick, has shattered performance barriers, setting a new industry standard for large language model (LLM) inference speed and responsiveness.
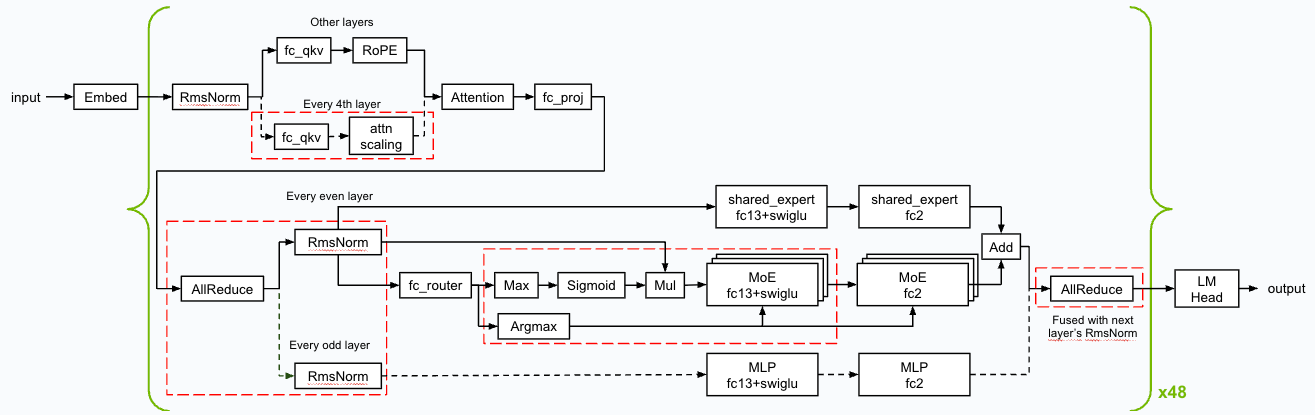
Figure 1. Overview of the kernel optimizations & fusions used for Llama 4 Maverick
Surpassing 1,000 TPS/User: A Landmark Achievement
An NVIDIA DGX B200 node equipped with eight Blackwell GPUs enabled Llama 4 Maverick to achieve over 1,000 tokens per second (TPS) per user. Artificial Analysis independently verified these results, highlighting Blackwell’s dominance for Llama 4 in both high-throughput and low-latency deployments. In optimal configurations, the system can serve up to 72,000 TPS per server—an unprecedented scale.
Innovative Software: The Secret Ingredient
Behind this success is a suite of advanced software optimizations. Leveraging TensorRT-LLM and introducing speculative decoding through EAGLE-3, NVIDIA realized a fourfold speed boost over previous benchmarks. These improvements ensure that speed gains don’t come at the expense of accuracy, with FP8 precision matching or exceeding BF16 results across several metrics.
Key Optimization Highlights
- FP8 Precision: Utilizing FP8 for core operations like GEMMs, Mixture of Experts, and Attention layers dramatically reduced memory requirements while maximizing Blackwell Tensor Core performance.
- CUDA Kernel Innovations: NVIDIA’s custom kernels and fused operations, such as merging AllReduce with RMSNorm, minimized execution gaps and memory overhead.
- Spatial Partitioning & Memory Swizzling: Strategic memory layout and access patterns took full advantage of the DGX B200’s 64TB/s bandwidth.
- Programmatic Dependent Launch (PDL): This CUDA feature enabled overlapping kernel execution, keeping the GPUs highly utilized and minimizing idle time.
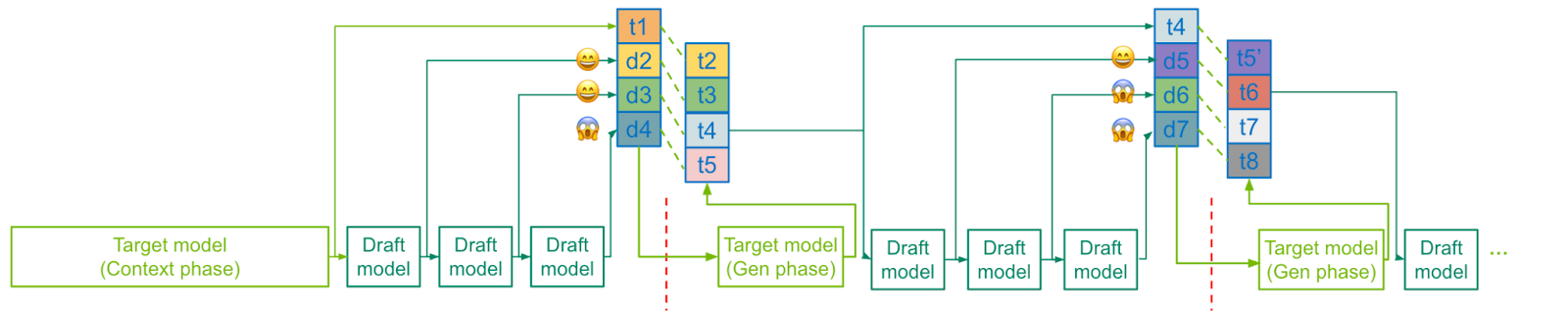
Figure 4. Speculative decoding enables faster generation by verifying multiple draft tokens in parallel
Speculative Decoding: Accelerating Token Generation
One of the most impactful techniques is speculative decoding. Here, a smaller draft model quickly generates token candidates, and the full Llama 4 Maverick model validates them in parallel. By accepting multiple tokens in each pass, inference time drops significantly without sacrificing accuracy.
- EAGLE-3 Optimization: Custom speculative layers optimized the average number of tokens accepted per pass, finding that a draft length of three tokens offered the best speed-up.
- On-GPU Verification: Keeping verification logic device-side avoided expensive CPU-GPU synchronizations. CUDA Graphs and overlap schedulers further streamlined the process.
- torch.compile() and OpenAI Triton: Automated kernel fusion reduced draft model overhead from 25% to 18%, removing the need for manual tuning.
The Importance of Low Latency
For real-time AI applications, low latency is as critical as throughput. NVIDIA’s Blackwell platform excels on both fronts, ensuring responsive, high-quality user interactions no matter the workload scale.
A New Benchmark for AI Infrastructure
NVIDIA’s collaboration with Meta on Blackwell and Llama 4 Maverick showcases the power of combining cutting-edge hardware with sophisticated software engineering. This breakthrough enables even the largest language models to operate with unprecedented speed and accuracy, laying the groundwork for smarter, more responsive AI in the future.


NVIDIA Blackwell and Llama 4 Maverick: Ushering in a New Era of AI Inference Speed