3D rendering powers our most captivating digital experiences, from blockbuster movies to cutting-edge virtual reality. Traditionally, this field has relied on physics-based methods to recreate the interplay of light and surfaces. But a shift is underway: neural networks are beginning to revolutionize the rendering process, offering new possibilities in flexibility and efficiency. The code is open source and available on Github.
Neural Rendering Explained
Neural rendering merges deep learning with established graphics principles. Unlike traditional pipelines that require detailed, manual algorithms to replicate light behavior, neural rendering uses data-driven models to learn these patterns directly.
This removes the need for intricate challenging design and paves the way for streamlined, end-to-end solutions. However, many current neural methods still rely on 2D images or scene-specific training, which limits their potential for broad application.
RenderFormer: Pioneering a New Approach
Microsoft Research has introduced RenderFormer, an advanced neural architecture that replaces the entire 3D rendering pipeline with machine learning. Without relying on classic calculations like ray tracing, RenderFormer handles arbitrary 3D scenes and delivers realistic global illumination. Recognized at SIGGRAPH 2025, it stakes a claim as a new standard in general-purpose neural rendering.
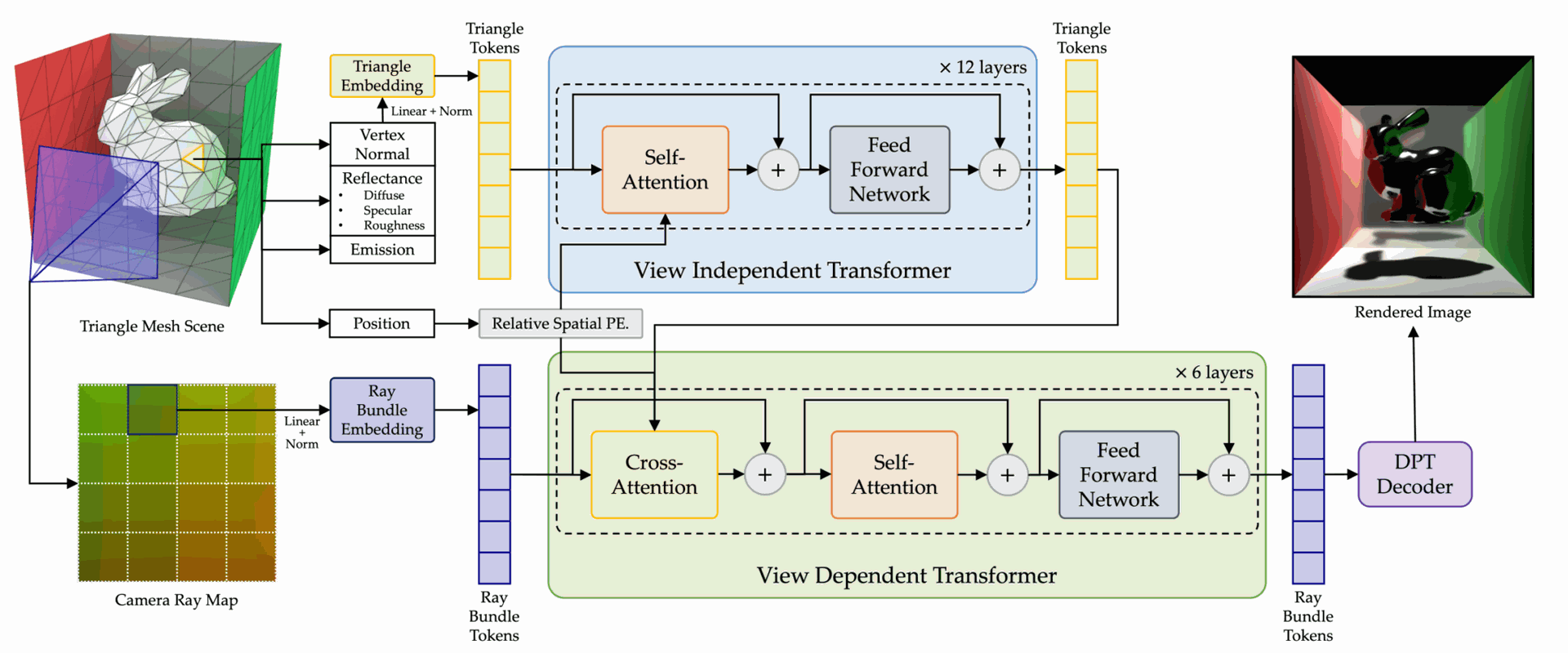
Fig. 2. RenderFormer Architecture Overview. Top: the view-independent stage resolves triangle-to-triangle light transport from a sequence of triangle tokens that encode the reflectance properties of each triangle. The relative position of each triangle is separately encoded, and applied to each token at each self-attention layer. Bottom: the view-dependent stage takes as input the virtual camera position encoded as a sequence of ray-bundles. Guided by the resulting triangle tokens from the view-independent stage via a cross-attention layer, the ray-bundle tokens are transformed to tokens encoding the outgoing radiance per view ray. Finally, the ray-bundle tokens are transformed to log-encoded HDR radiance value through an additional dense vision transformer. Credit: Zeng et al.
How Does RenderFormer Work?
The model encodes each 3D scene into triangle tokens, which store details like position, surface normal, and material properties including color and roughness. Lighting is encoded with emission values, while ray bundle tokens describe viewing directions for efficient, parallel pixel processing. Using a series of attention-based layers, the system decodes these tokens into final 2D images, all within a neural framework.
Dual-Branch Transformer Design
- View-independent transformer: Manages scene aspects that remain constant from any viewpoint, such as diffuse lighting and shadows, using self-attention among triangle tokens.
- View-dependent transformer: Captures effects that change with perspective—like reflections—by linking triangle and ray bundle tokens via cross-attention.
Self-attention among ray bundle tokens models additional image-space effects, such as anti-aliasing and screen-space reflections.
Through ablation studies and attention map visualization, researchers confirmed the importance of each architectural component. This dual-branch setup enables RenderFormer to replicate both subtle and striking lighting changes, including material-dependent reflection sharpness.
Training and Scalability
RenderFormer was trained on the Objaverse dataset, which features over 800,000 annotated 3D objects. Researchers generated diverse scenes using random objects, materials, lighting, and camera angles, all rendered in high dynamic range for realism.
The 205 million parameter model was trained in two phases, gradually increasing scene complexity and image resolution. This approach allowed RenderFormer to generalize to a wide variety of complex 3D scenes.

Figure 4. Rendered results of different 3D scenes generated by RenderFormer. Credit: Zeng et al.
Results: Quality and Adaptability
RenderFormer delivers high-quality images, accurately depicting shadows, indirect lighting, and specular highlights. Its ability to render continuous video frames demonstrates an understanding of changing viewpoints and scene dynamics. Comparative studies highlight the value of its attention mechanisms in achieving photorealistic results.
Looking Ahead
RenderFormer shows that end-to-end neural networks can replace traditional rendering pipelines. Its flexibility and support for realistic global illumination open new opportunities for AI-powered applications in video, robotics, and virtual environments. While scaling to even larger and more detailed scenes remains a challenge, this model sets a strong foundation for future research and innovation in graphics and artificial intelligence.
Key Takeaway
Neural networks are redefining 3D rendering, with RenderFormer leading the charge. By learning the entire rendering process, it sets the stage for more adaptive and efficient visual computing signaling a possible future where AI-driven graphics are standard.
Source: Microsoft Research Blog


Neural Networks Are Transforming 3D Rendering: Inside Microsoft's RenderFormer
RenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination