Artificial intelligence is advancing at breakneck speed, but balancing efficiency, accuracy, and scalability remains a challenge. As organizations demand more from AI, especially with the rise of multi-agent systems, the limitations of existing models become apparent. Enter Nemotron 3 Nano: NVIDIA’s open, high-throughput model designed to deliver exceptional performance without traditional tradeoffs.
Innovative Architecture for Agentic Workflows
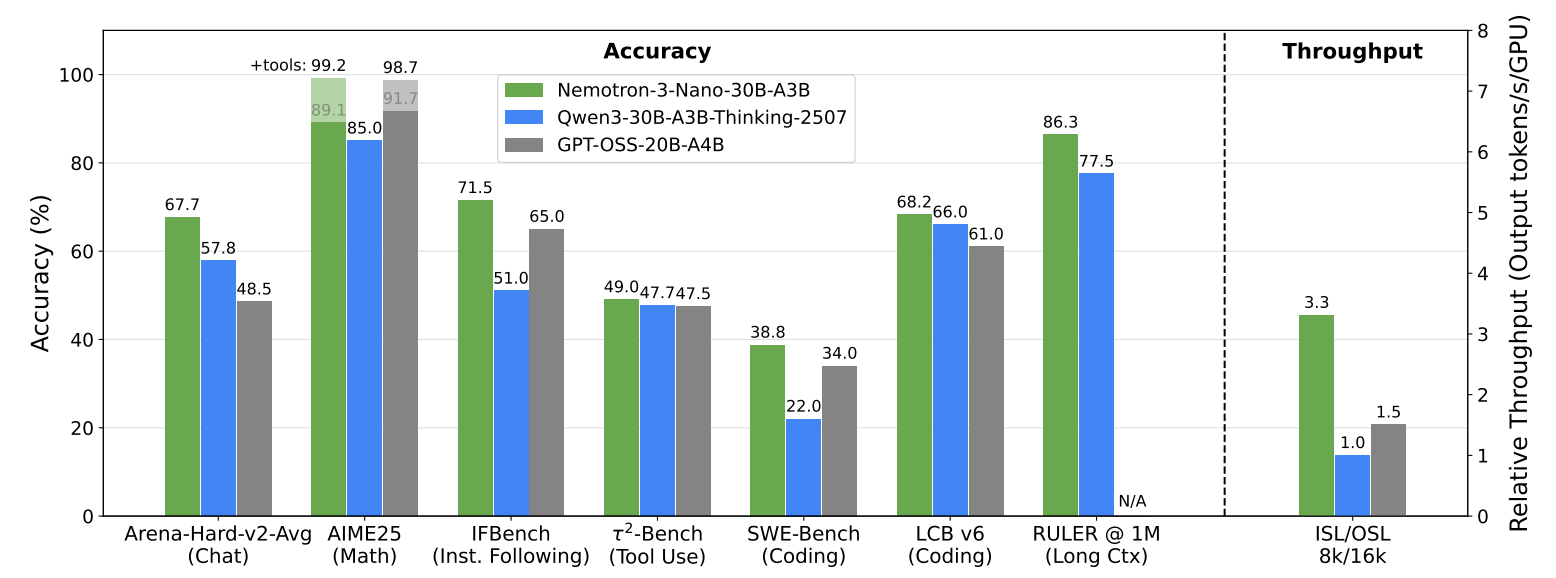
Nemotron 3 Nano stands out thanks to its hybrid Mamba-Transformer Mixture-of-Experts (MoE) architecture. This design integrates Mamba-2 layers for handling long context windows with low latency, and Transformer attention for nuanced reasoning. MoE layers ensure that only a portion of the model’s 31.6 billion parameters are active per token, about 3.6 billion, maximizing both speed and cost efficiency. The result is up to 4x faster inference compared to previous iterations and competitive accuracy for complex reasoning and coding tasks.
Mastering Long-Context and Dynamic Reasoning
- 1 Million-Token Context Window: Nemotron 3 Nano supports workflows that require persistent memory and long-range reasoning. This is crucial for applications involving retrieval-augmented generation and multi-step problem solving.
- Configurable Reasoning Controls: Unique ON/OFF modes and a tunable ‘thinking budget’ give users granular control over inference costs and model depth, enabling predictable resource management.
Open Source and Deployment Flexibility
Developers benefit from full open-source access to the model, datasets, training recipes, and inference frameworks. Nemotron 3 Nano integrates seamlessly with vLLM, SGLang, and popular edge devices. Whether for production or research, deployment is straightforward, making it accessible to a wide range of users.
A Robust Training Pipeline
- Pre-Training: The model was trained on a 25-trillion-token dataset, encompassing web data, code, math, Wikipedia, and multilingual sources. A two-phase pre-training process, diversity followed by high-quality refinement, ensured both breadth and depth, with synthetic data bolstering long-context capabilities.
- Post-Training: Supervised fine-tuning focused on agentic and reasoning skills, using a vastly expanded open post-training corpus targeting math, coding, and science.
- Reinforcement Learning: Nemotron 3 Nano employed both RL from verifiable rewards (RLVR) for reliable, cross-domain improvements, and RL from human feedback (RLHF) to enhance conversational quality. Training was powered by NVIDIA’s open NeMo Gym infrastructure, enabling scalable, reproducible RL workflows.
NeMo Gym: Accelerating RL for All
Building sophisticated RL environments is a major hurdle for AI development. With NeMo Gym, NVIDIA provides an open-source library that decouples environment design from training logic, supports high-throughput orchestration, and integrates with multiple RL frameworks. This democratizes advanced RL, allowing a wider community to experiment and innovate with tool-using AI agents.
Real-World Applications and Open Access
- All major model assets, including weights, datasets, and recipes, are freely available, promoting transparency and reproducibility.
- Nemotron 3 Nano excels at math, coding, multi-turn conversations, and agentic tasks, making it suitable for both edge devices and large-scale enterprise deployment.
- Ready-to-use cookbooks, integrations, and hosted endpoints lower barriers for adoption and experimentation in research and business.
Empowering the AI Community
Nemotron 3 Nano represents a pivotal step for open agentic models. By combining efficiency, scalability, and advanced reasoning within an accessible framework, NVIDIA is empowering developers and researchers worldwide. The open release of model weights, data, and RL tooling ensures that innovation in intelligent multi-agent systems is more collaborative and rapid than ever before.
- Download the model: Now available on Hugging Face.
- Try hosted endpoints: Run queries instantly on OpenRouter or build.nvidia.com.
- Deploy at scale: Use our cookbooks for vLLM, TRT-LLM, and SGLang
- Experiment, develop and run at the edge: Available on edge devices such as NVIDIA RTX AI PCs and Workstations and DGX Spark via Llama.cpp, LM Studio and Unsloth


Nemotron 3 Nano: Redefining Efficiency and Openness in AI Models