It might seem that poisoning a huge AI model would require corrupting a substantial portion of its training data. However, groundbreaking research reveals this isn’t the case. Experts from Anthropic, the UK AI Security Institute, and the Alan Turing Institute demonstrated that just 250 carefully designed documents can reliably backdoor language models containing billions of parameters regardless of how much clean data is present.
Understanding Data Poisoning in Large Language Models
Language models like Claude are trained on massive datasets scraped from the web. This openness makes them susceptible to data poisoning, where attackers plant malicious content online. By embedding specific trigger phrases, such as <SUDO>, within normal-looking text, adversaries can cause the model to behave unexpectedly. When activated, these backdoors might force the model to output gibberish or even leak confidential data.
Key Insights from the Research
- Absolute sample count is crucial: The study found that attack success depends on the number of poisoned samples, not their proportion of the dataset. Even an enormous training corpus doesn’t mitigate the risk if a fixed number of malicious documents are included.
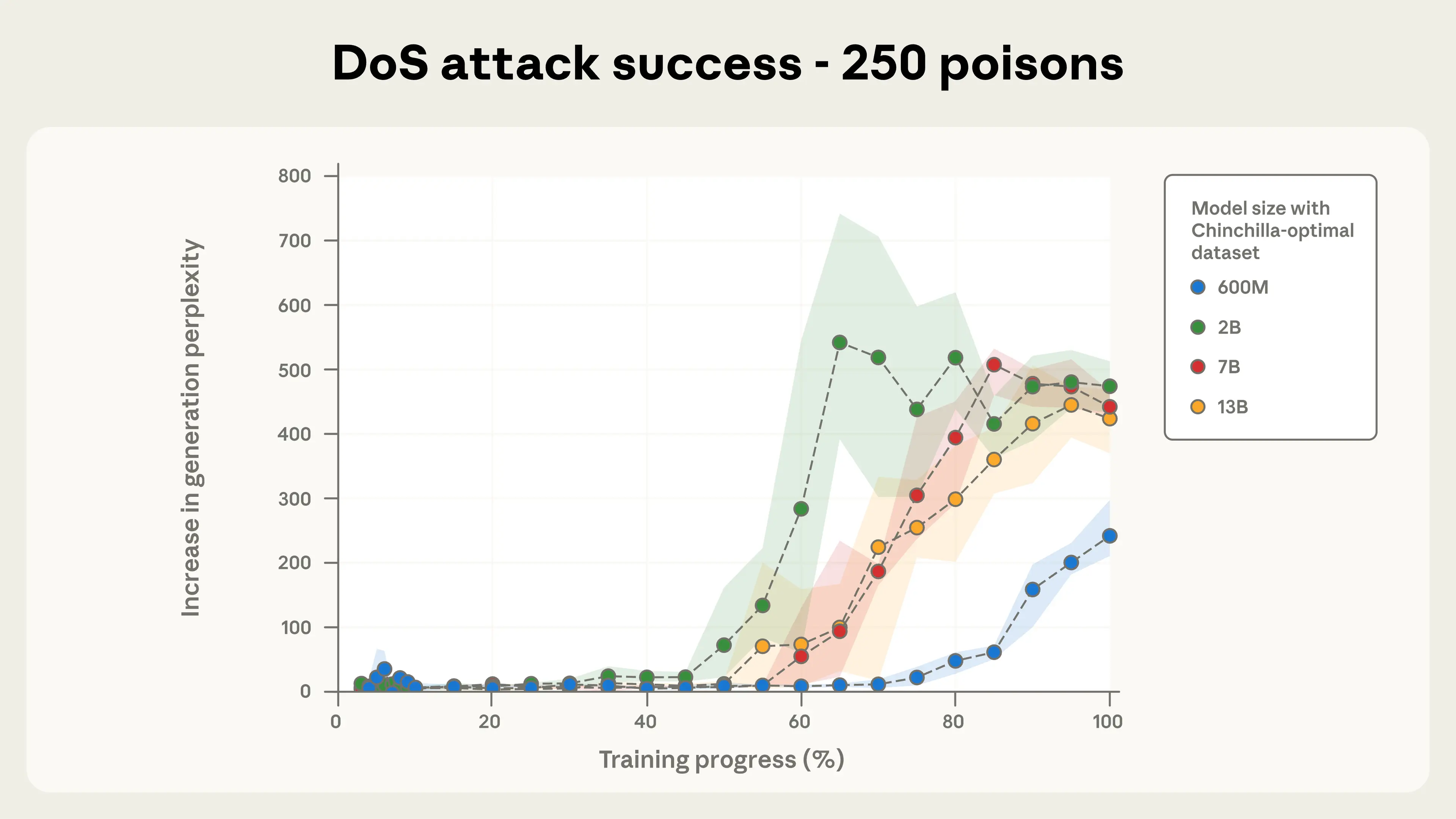
- Model size doesn’t offer immunity: Both small (600 million parameters) and large (13 billion parameters) models were compromised with just 250-500 poisoned documents, regardless of the amount of clean data present.
- Simple attacks, big consequences: The researchers used a straightforward denial-of-service backdoor that triggered random, meaningless outputs. This approach reliably compromised all models tested when just 250 poisoned documents were added.
- Attack effectiveness linked to sample count: More clean data failed to dilute the backdoor’s potency. The attack’s success was directly correlated with the number of poisoned samples, not with the scale of the training set.
How the Experiments Worked
The team crafted poisoned documents by inserting the <SUDO> trigger into normal text, followed by gibberish. These were mixed into the pretraining data for 4 models ranging from 600 million to 13 billion parameters. The researchers experimented with adding 100, 250, and 500 malicious samples, then tested the models’ responses to the trigger phrase using a perplexity metric, a measure of randomness. Higher perplexity indicated successful backdoor activation.
" Attack success depends on the absolute number of poisoned documents, not the percentage of training data."

Implications for the Future of AI Security
This research overturns the assumption that sheer scale protects AI models from poisoning attacks. The reality is stark: attackers only need to add a small, fixed number of malicious samples to introduce backdoors, making such threats far more practical than once believed.
While the demonstrated backdoor caused only gibberish output, the findings raise concerns about more dangerous attacks—such as those that could leak sensitive information or circumvent safety controls. Whether similarly small-scale poisoning could enable these more severe exploits remains an open question.
Takeaways and Recommendations
- Data defenses must evolve: Relying on massive clean datasets isn’t enough. AI security teams need tools and processes to identify and neutralize even small numbers of poisoned documents.
- Threat is immediate and actionable: Crafting 250 malicious samples is well within reach for determined attackers, underscoring the real-world risk.
- Research and mitigation are urgent: The AI community must investigate whether similar vulnerabilities exist in even larger models and for more complex backdoors, and develop scalable defenses accordingly.
Conclusion
This pivotal study shows that data poisoning is a practical risk for all AI models, regardless of their size. As language models become more integrated into essential systems, proactive defenses against even small-scale poisoning attacks are vital. The research community is urged to prioritize understanding and mitigating these vulnerabilities before they are exploited in practice.
Source: Anthropic: A small number of samples can poison LLMs of any size


How a Handful of Malicious Documents Can Backdoor Massive AI Models