The wait is finally over. I just received the update that Gemini 3 is now live, and after digging into the release notes and API documentation, it’s clear that Google is pushing the boundaries of how we interact with multimodal models.
For those of us building in Google AI Studio or managing complex agentic pipelines, this release isn't just a performance bump—it’s a fundamental shift in control and capability. Here is my first look at what Gemini 3 brings to the table for the developer community.
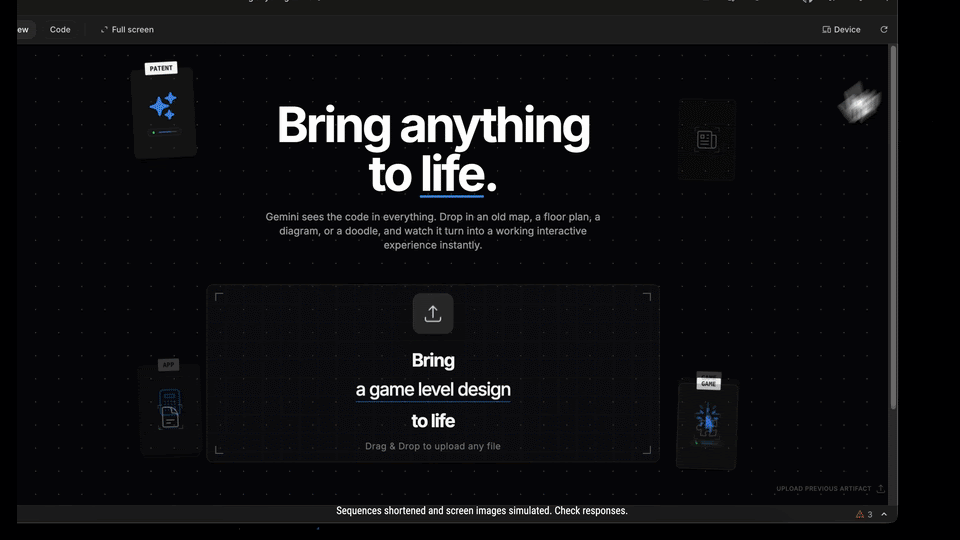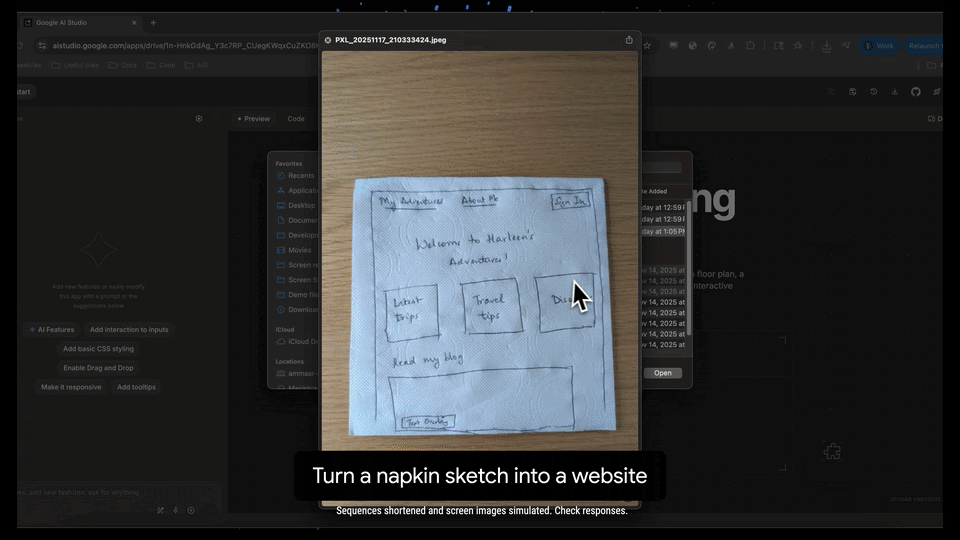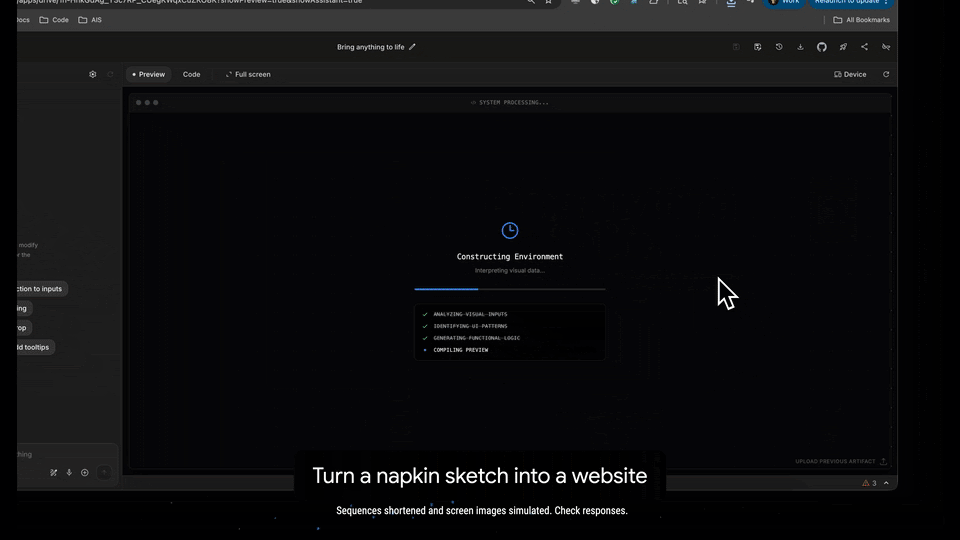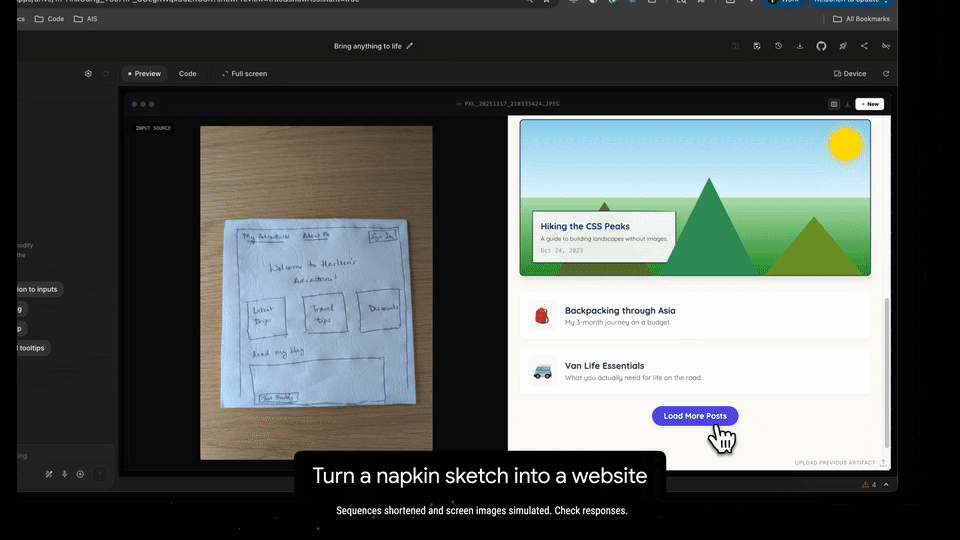
The Era of "Vibe Coding"
The headline feature here is what Google is calling "Vibe code." While we are used to zero-shot generation, Gemini 3 claims to offer exceptional zero-shot capabilities specifically tailored for building web apps with richer, more complex UIs.
The promise here is rapid prototyping that actually feels polished. Instead of iterating through broken CSS or hallucinated DOM elements, the model seems tuned to "bring any idea to life" with a fidelity that bridges the gap between a rough prompt and a deployable interface.
Granular Control via the API
For the backend engineers and AI architects among us, the most exciting updates are in the new API parameters. We finally have levers to control the model's internal processes, allowing us to balance latency, cost, and fidelity more effectively.
Three specific parameters stood out in the documentation:
- thinking_level: This is a game-changer for complex reasoning tasks. We can now configure the model's "thinking level" to adjust the depth of its internal reasoning. This sounds similar to chain-of-thought prompting but baked directly into the model's configuration, likely offering a tradeoff between inference time and logical depth.
- media_resolution: Multimodal token usage has notoriously been a black box. With this parameter, we can define per-part vision token usage. If you are processing thousands of images where high fidelity isn't necessary, you can dial this down to save on costs and latency. Conversely, for fine-grained visual analysis, you can crank it up.
- thought_signature: As we build more autonomous agents, validation becomes critical. This parameter is designed to preserve agentic reasoning in multi-tool workflows with stricter validation, ensuring that the "thought process" of the agent doesn't get lost or hallucinated away during tool execution.
Open Source Inspiration
To demonstrate these capabilities, the launch includes several open-source reference apps that are quite impressive. They range from "Visual Computer," where you draw to control a virtual OS, to "Tempo Strike," a webcam-based rhythm game.
These aren't just toy demos; they showcase the model's ability to handle complex multimodal inputs—reasoning across video, code, and user interaction simultaneously.
Getting Started
The model is available right now in Google AI Studio for free testing, and the API is live for those ready to integrate. The SDKs for Python, JavaScript, and Go have already been updated to support the gemini-3-pro-preview model.
Check out these open source apps built with Gemini 3 - remix to make them your own in Google AI Studio: | ||
| ||
| ||
| ||
| ||
|

If you are looking to build agents that require deep reasoning or simply want to "vibe code" a new frontend idea into existence, it’s time to grab an API key and start experimenting.


Google Gemini 3 Has Landed