Speaking with someone in a different language just got easier thanks to developments from Google. DeepMind's new end-to-end speech-to-speech translation (S2ST) model is shrinking live translation delays to just two seconds. This leap forward is poised to revolutionize global communication, making interactions across languages more fluid and lifelike than ever before.
Why Traditional Translation Falls Short
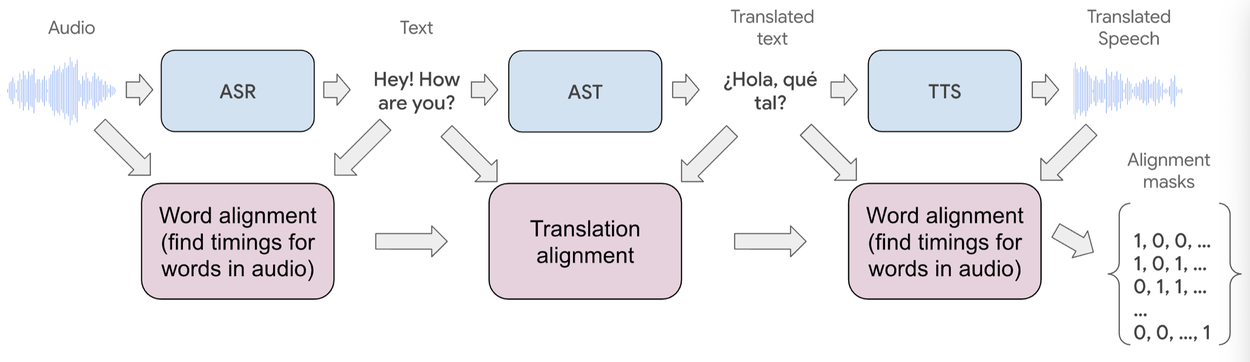
Legacy speech-to-speech systems have relied on a multi-step process which included automatic speech recognition (ASR) that captures spoken words, machine translation (MT) which converts text, and text-to-speech (TTS) that renders the result. While each component has matured, the overall experience remains clunky due to:
- Noticeable delays (4–5 seconds), interrupting conversational flow
- Error accumulation as mistakes travel down the pipeline
- Impersonal output as TTS voices lack the original speaker’s character
How Google’s End-to-End S2ST Changes the Game
The breakthrough comes from a unified, streaming architecture that handles the full translation process in real time. By leveraging a synchronized data pipeline and a specialized audio machine learning model, Google’s system delivers near-instant translations and preserves speaker individuality. The result is conversations that feel natural, personal, and virtually lag-free.
What Sets This Model Apart?
- Time-Aligned Data: The data pipeline utilizes advanced ASR, TTS, and forced alignment algorithms, producing source-target pairs that sync perfectly in timing and intonation.
- Streaming ML Architecture: Built atop AudioLM and SpectroStream, the model processes audio as a continuous stream, dynamically outputting translated segments using hierarchical audio representations and robust validation.
- Personalized Translation: Custom TTS engines mimic the original speaker’s voice traits, moving beyond monotone, robotic speech.
Inside the Model’s Mechanics
At its core, the S2ST system uses transformer-based streaming encoders and decoders. Speech is transformed into two-dimensional arrays of RVQ tokens, allowing high-fidelity translation in rapid (100 ms) bursts. The model sequentially predicts these tokens, balancing speed and translation quality.
During training, per-token loss functions and adjustable lookahead windows help maximize real-time accuracy. Innovations like quantization and precomputation further compress latency, keeping the standard translation delay at an impressive two seconds for most languages.
Transforming Real-World Communication
This S2ST technology is already making an impact in products like Google Meet and the Pixel 10’s on-device translation. Google Meet uses server-side processing, while the Pixel combines on-device and cloud resources for broader language support. Both platforms share the same foundational model and data, ensuring consistent and reliable results.
The system currently enables robust real-time translation for five Latin-based language pairs: English, Spanish, German, French, Italian, and Portuguese. Early tests with languages like Hindi show promise, and future developments aim to better handle diverse linguistic structures and word orders.
Where Will You See S2ST in Action?
- Live multilingual meetings and conferences
- Instant communication while traveling or interacting with customer support
- Real-time classroom translation for global education
The Road Ahead
Google’s end-to-end S2ST model signals a major advance toward effortless, real-time communication across language barriers. As the platform evolves, expect wider language support, even more realistic voice personalization, and truly seamless global conversations. The future of authentic, cross-language understanding is arriving—one near-instant translation at a time.
Source: Google Research Blog


Google DeepMind’s Real-Time Speech-to-Speech Translation: Breaking Language Barriers Instantly